Anti-LM Decoding for Zero-shot In-context Machine Translation

0
👀
Sign in to get full access
Overview
- Zero-shot In-context learning refers to models that can perform a task simply from the instructions, without additional training.
- However, pre-trained large language models often struggle with this task and are poorly calibrated.
- One effective approach to address this is using a contrastive decoding objective, which accounts for the probability of generating the next token based on the context.
- This paper introduces an "Anti-Language Model" objective with a decay factor to improve In-context Machine Translation.
Plain English Explanation
Imagine you have a very smart friend who knows a lot about different topics. Sometimes, you might ask this friend to help you with a new task, like translating a document from one language to another. If your friend is really knowledgeable, they might be able to do the translation just by understanding the instructions, without needing extra training.
However, large artificial intelligence (AI) language models, which are like super-smart digital assistants, don't always work this way. These models can struggle to perform certain tasks, even if they have a lot of general knowledge. The reason is that they can be "miscalibrated" - they don't always accurately assess the probability of generating the correct output.
To address this problem, the researchers in this paper tried a new approach called "contrastive decoding." The idea is to have the model not only consider the probability of each possible next word, but also how that word fits with the overall context. This helps the model make better choices and perform the task more accurately.
The researchers also introduced a specific type of contrastive decoding called the "Anti-Language Model" objective, which is designed to work well for translating text from one language to another using only the instructions, without any additional training.
Technical Explanation
This paper explores the problem of zero-shot in-context learning, where language models are asked to perform a task like machine translation simply based on the instructions, without any additional training. The authors note that pre-trained large language models often struggle with this task due to poor calibration.
To address this, the authors propose a new decoding objective called the "Anti-Language Model" (ALM) objective. This approach accounts for the prior probability of generating each next token, conditioning on the context. The ALM objective includes a decay factor that is designed to improve the model's performance on in-context machine translation tasks.
The researchers conduct experiments across 3 different model types and sizes, 3 language directions, and for both greedy decoding and beam search. They find that the proposed ALM objective outperforms other state-of-the-art decoding approaches, with up to 20 BLEU point improvements in some settings.
Critical Analysis
The paper provides a promising approach to addressing the challenges of zero-shot in-context learning, which is an important capability for language models to possess. The proposed ALM objective seems effective at improving model performance on machine translation tasks without additional training.
However, the paper does not explore the broader implications or limitations of this approach. For example, it's unclear how well the ALM objective would generalize to other types of tasks beyond machine translation. Additionally, the paper does not discuss potential biases or fairness issues that could arise from this method.
Further research would be needed to fully understand the scope and limitations of the ALM objective. It would be valuable to see experiments on a wider range of tasks and model architectures to assess the broader applicability of this technique.
Conclusion
This paper introduces a novel decoding objective called the "Anti-Language Model" (ALM) objective that aims to improve the performance of language models on zero-shot in-context learning tasks, specifically for machine translation. The researchers demonstrate significant improvements in translation quality compared to other state-of-the-art approaches.
While this is a promising step forward, further research is needed to fully understand the strengths, weaknesses, and broader implications of this technique. Nonetheless, the ALM objective represents an important advancement in addressing the calibration challenges of large language models and could have far-reaching impacts on the development of more capable and versatile AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👀
0
Anti-LM Decoding for Zero-shot In-context Machine Translation
Suzanna Sia, Alexandra DeLucia, Kevin Duh
Zero-shot In-context learning is the phenomenon where models can perform the task simply given the instructions. However, pre-trained large language models are known to be poorly calibrated for this task. One of the most effective approaches to handling this bias is to adopt a contrastive decoding objective, which accounts for the prior probability of generating the next token by conditioning on some context. This work introduces an Anti-Language Model objective with a decay factor designed to address the weaknesses of In-context Machine Translation. We conduct our experiments across 3 model types and sizes, 3 language directions, and for both greedy decoding and beam search ($B=5$). The proposed method outperforms other state-of-art decoding objectives, with up to $20$ BLEU point improvement from the default objective observed in some settings.
Read more4/4/2024
0
Enhancing Contextual Understanding in Large Language Models through Contrastive Decoding
Zheng Zhao, Emilio Monti, Jens Lehmann, Haytham Assem
Large language models (LLMs) tend to inadequately integrate input context during text generation, relying excessively on encoded prior knowledge in model parameters, potentially resulting in generated text with factual inconsistencies or contextually unfaithful content. LLMs utilize two primary knowledge sources: 1) prior (parametric) knowledge from pretraining, and 2) contextual (non-parametric) knowledge from input prompts. The study addresses the open question of how LLMs effectively balance these knowledge sources during the generation process, specifically in the context of open-domain question answering. To address this issue, we introduce a novel approach integrating contrastive decoding with adversarial irrelevant passages as negative samples to enhance robust context grounding during generation. Notably, our method operates at inference time without requiring further training. We conduct comprehensive experiments to demonstrate its applicability and effectiveness, providing empirical evidence showcasing its superiority over existing methodologies. Our code is publicly available at: https://github.com/amazon-science/ContextualUnderstanding-ContrastiveDecoding.
Read more5/7/2024

0
Understanding and Addressing the Under-Translation Problem from the Perspective of Decoding Objective
Chenze Shao, Fandong Meng, Jiali Zeng, Jie Zhou
Neural Machine Translation (NMT) has made remarkable progress over the past years. However, under-translation and over-translation remain two challenging problems in state-of-the-art NMT systems. In this work, we conduct an in-depth analysis on the underlying cause of under-translation in NMT, providing an explanation from the perspective of decoding objective. To optimize the beam search objective, the model tends to overlook words it is less confident about, leading to the under-translation phenomenon. Correspondingly, the model's confidence in predicting the End Of Sentence (EOS) diminishes when under-translation occurs, serving as a mild penalty for under-translated candidates. Building upon this analysis, we propose employing the confidence of predicting EOS as a detector for under-translation, and strengthening the confidence-based penalty to penalize candidates with a high risk of under-translation. Experiments on both synthetic and real-world data show that our method can accurately detect and rectify under-translated outputs, with minor impact on other correct translations.
Read more5/30/2024
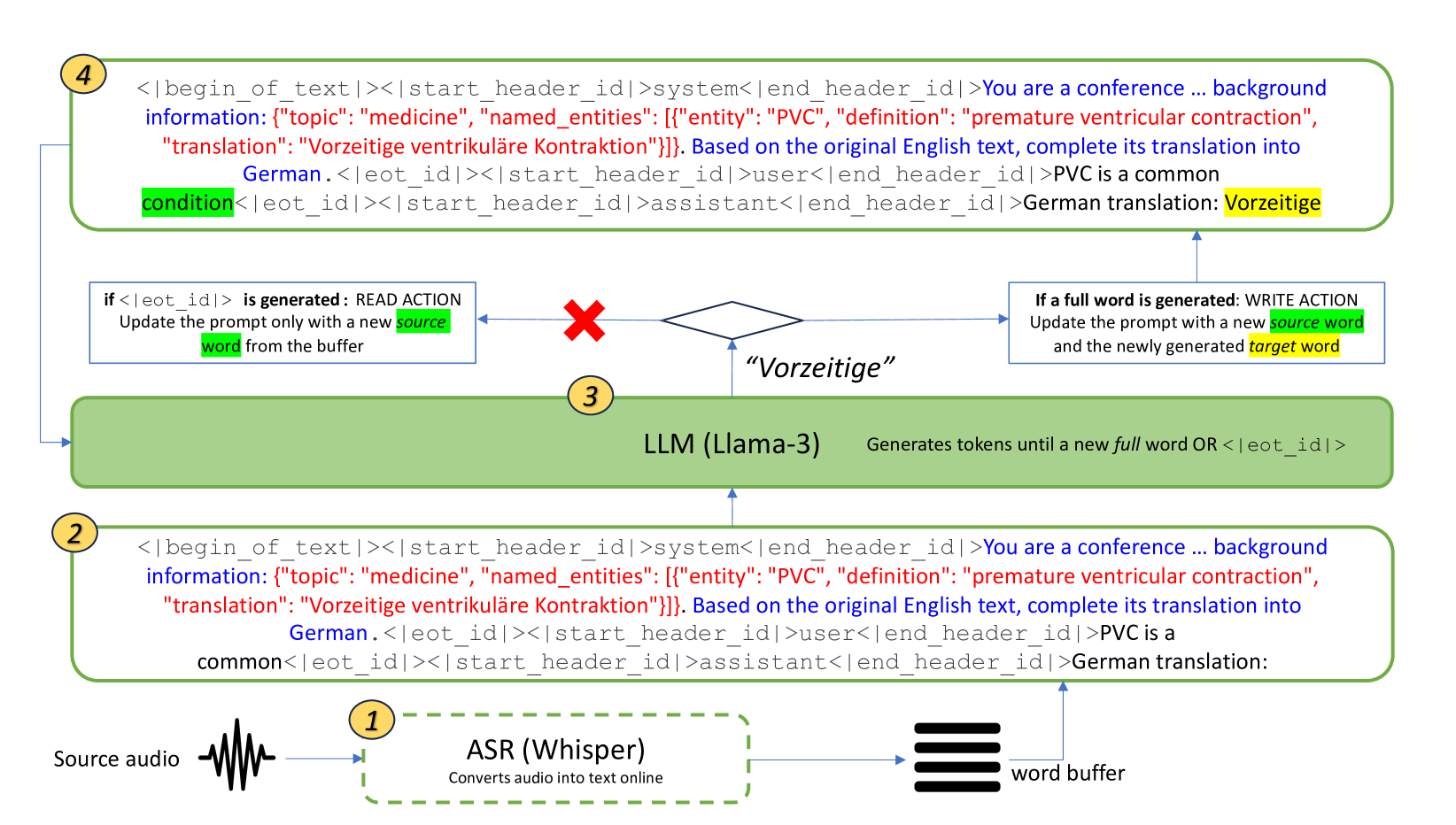
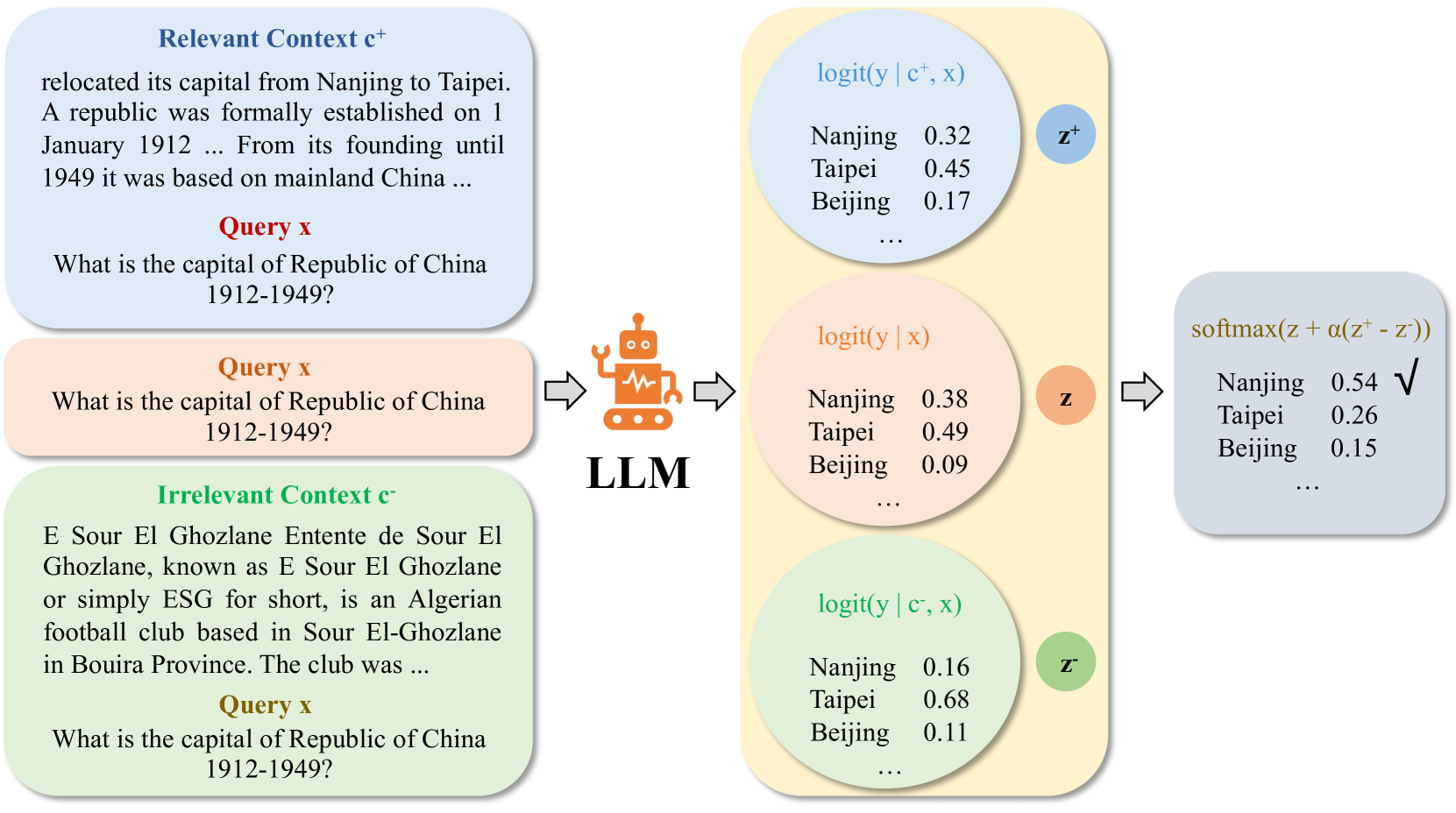
0
LLMs Are Zero-Shot Context-Aware Simultaneous Translators
Roman Koshkin, Katsuhito Sudoh, Satoshi Nakamura
The advent of transformers has fueled progress in machine translation. More recently large language models (LLMs) have come to the spotlight thanks to their generality and strong performance in a wide range of language tasks, including translation. Here we show that open-source LLMs perform on par with or better than some state-of-the-art baselines in simultaneous machine translation (SiMT) tasks, zero-shot. We also demonstrate that injection of minimal background information, which is easy with an LLM, brings further performance gains, especially on challenging technical subject-matter. This highlights LLMs' potential for building next generation of massively multilingual, context-aware and terminologically accurate SiMT systems that require no resource-intensive training or fine-tuning.
Read more6/24/2024