Anytime Continual Learning for Open Vocabulary Classification

0

Sign in to get full access
Overview
- Presents an "Anytime Continual Learning" approach for open-vocabulary classification
- Allows models to learn continuously from new data without forgetting previous knowledge
- Enables models to classify samples into an open-ended set of categories
Plain English Explanation
The paper introduces a new approach called "Anytime Continual Learning" for open-vocabulary classification. This allows machine learning models to continuously learn from new data without forgetting what they've learned before.
Typically, machine learning models are trained on a fixed set of classes or categories. But in many real-world scenarios, the set of possible classes is constantly expanding as new information becomes available. The "Anytime Continual Learning" method addresses this by enabling models to classify samples into an open-ended and growing set of categories.
The key idea is to maintain a flexible model that can adapt and expand its knowledge over time, rather than being limited to a predefined set of classes. This makes the models more versatile and useful in dynamic, real-world environments.
Technical Explanation
The paper proposes an "Anytime Continual Learning" framework that allows machine learning models to continuously learn new classes or categories without forgetting previously acquired knowledge. This is achieved through several key components:
-
Flexible Classifier: The model uses a flexible classifier head that can dynamically expand to accommodate new classes as they are introduced, rather than being restricted to a fixed set of output neurons.
-
Knowledge Distillation: When learning new classes, the model uses knowledge distillation to retain information about previously learned classes, preventing catastrophic forgetting.
-
Class-Incremental Learning: The model is trained in a class-incremental manner, learning new classes one at a time while preserving performance on previous classes.
-
Memory Bank: The model maintains a memory bank of past examples to replay during training, further reinforcing the retention of old knowledge.
-
Dynamic Routing: The model dynamically routes inputs to the appropriate classifier heads, allowing it to handle an open-ended and growing set of classes.
These techniques work together to enable the model to continuously expand its knowledge and classification capabilities over time, without losing its ability to recognize previously learned classes.
Critical Analysis
The paper presents a compelling approach to the challenge of open-vocabulary classification and continual learning. By allowing the model to dynamically expand its knowledge and classification capabilities, it addresses a key limitation of traditional machine learning models that are restricted to a fixed set of classes.
However, the paper does not discuss potential drawbacks or limitations of the proposed method. For example, the computational and memory requirements of maintaining a flexible classifier and memory bank may become burdensome as the number of classes grows. Additionally, the performance of the model on previously learned classes may degrade over time as new classes are introduced.
Further research could explore ways to optimize the efficiency and scalability of the "Anytime Continual Learning" approach, as well as investigate potential biases or edge cases that may arise when dealing with an open-ended and growing set of classes.
Conclusion
The "Anytime Continual Learning" framework presented in this paper represents an important advancement in machine learning, enabling models to continuously expand their knowledge and classification capabilities over time. This addresses a key limitation of traditional machine learning models and opens up new possibilities for applications that require versatile and adaptable classification systems.
While the paper does not address all potential challenges, the core ideas and techniques introduced here lay the groundwork for further research and development in the field of continual learning. As the volume and complexity of data continue to grow, the ability to learn and adapt in an open-ended manner will become increasingly crucial for the success of AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Anytime Continual Learning for Open Vocabulary Classification
Zhen Zhu, Yiming Gong, Derek Hoiem
We propose an approach for anytime continual learning (AnytimeCL) for open vocabulary image classification. The AnytimeCL problem aims to break away from batch training and rigid models by requiring that a system can predict any set of labels at any time and efficiently update and improve when receiving one or more training samples at any time. Despite the challenging goal, we achieve substantial improvements over recent methods. We propose a dynamic weighting between predictions of a partially fine-tuned model and a fixed open vocabulary model that enables continual improvement when training samples are available for a subset of a task's labels. We also propose an attention-weighted PCA compression of training features that reduces storage and computation with little impact to model accuracy. Our methods are validated with experiments that test flexibility of learning and inference. Code is available at https://github.com/jessemelpolio/AnytimeCL.
Read more9/16/2024
0
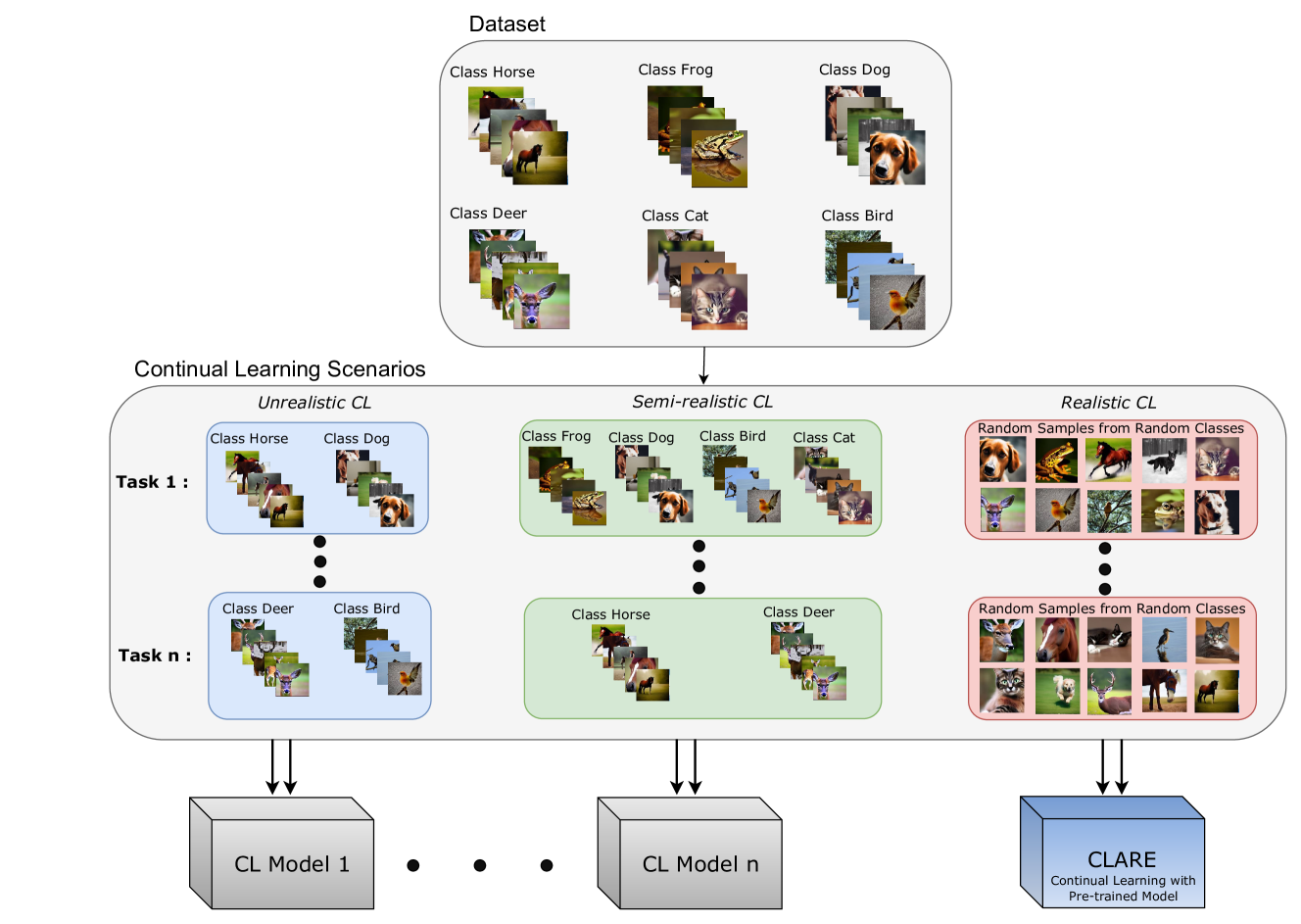
Realistic Continual Learning Approach using Pre-trained Models
Nadia Nasri, Carlos Guti'errez-'Alvarez, Sergio Lafuente-Arroyo, Saturnino Maldonado-Basc'on, Roberto J. L'opez-Sastre
Continual learning (CL) is crucial for evaluating adaptability in learning solutions to retain knowledge. Our research addresses the challenge of catastrophic forgetting, where models lose proficiency in previously learned tasks as they acquire new ones. While numerous solutions have been proposed, existing experimental setups often rely on idealized class-incremental learning scenarios. We introduce Realistic Continual Learning (RealCL), a novel CL paradigm where class distributions across tasks are random, departing from structured setups. We also present CLARE (Continual Learning Approach with pRE-trained models for RealCL scenarios), a pre-trained model-based solution designed to integrate new knowledge while preserving past learning. Our contributions include pioneering RealCL as a generalization of traditional CL setups, proposing CLARE as an adaptable approach for RealCL tasks, and conducting extensive experiments demonstrating its effectiveness across various RealCL scenarios. Notably, CLARE outperforms existing models on RealCL benchmarks, highlighting its versatility and robustness in unpredictable learning environments.
Read more4/12/2024
0
CLAP4CLIP: Continual Learning with Probabilistic Finetuning for Vision-Language Models
Saurav Jha, Dong Gong, Lina Yao
Continual learning (CL) aims to help deep neural networks to learn new knowledge while retaining what has been learned. Recently, pre-trained vision-language models such as CLIP, with powerful generalizability, have been gaining traction as practical CL candidates. However, the domain mismatch between the pre-training and the downstream CL tasks calls for finetuning of the CLIP on the latter. The deterministic nature of the existing finetuning methods makes them overlook the many possible interactions across the modalities and deems them unsafe for high-risk CL tasks requiring reliable uncertainty estimation. To address these, our work proposes Continual LeArning with Probabilistic finetuning (CLAP). CLAP develops probabilistic modeling over task-specific modules with visual-guided text features, providing more calibrated finetuning in CL. It further alleviates forgetting by exploiting the rich pre-trained knowledge of CLIP for weight initialization and distribution regularization of task-specific modules. Cooperating with the diverse range of existing prompting methods, CLAP can surpass the predominant deterministic finetuning approaches for CL with CLIP. We conclude with out-of-the-box applications of superior uncertainty estimation abilities of CLAP for novel data detection and exemplar selection within CL setups. Our code is available at url{https://github.com/srvCodes/clap4clip}.
Read more5/24/2024

0
Learning to Learn without Forgetting using Attention
Anna Vettoruzzo, Joaquin Vanschoren, Mohamed-Rafik Bouguelia, Thorsteinn Rognvaldsson
Continual learning (CL) refers to the ability to continually learn over time by accommodating new knowledge while retaining previously learned experience. While this concept is inherent in human learning, current machine learning methods are highly prone to overwrite previously learned patterns and thus forget past experience. Instead, model parameters should be updated selectively and carefully, avoiding unnecessary forgetting while optimally leveraging previously learned patterns to accelerate future learning. Since hand-crafting effective update mechanisms is difficult, we propose meta-learning a transformer-based optimizer to enhance CL. This meta-learned optimizer uses attention to learn the complex relationships between model parameters across a stream of tasks, and is designed to generate effective weight updates for the current task while preventing catastrophic forgetting on previously encountered tasks. Evaluations on benchmark datasets like SplitMNIST, RotatedMNIST, and SplitCIFAR-100 affirm the efficacy of the proposed approach in terms of both forward and backward transfer, even on small sets of labeled data, highlighting the advantages of integrating a meta-learned optimizer within the continual learning framework.
Read more8/15/2024