Learning to Learn without Forgetting using Attention

0

Sign in to get full access
Overview
- This paper proposes a novel approach to "learning to learn without forgetting" using attention mechanisms.
- The key idea is to enable continual learning by selectively attending to relevant past knowledge when learning new tasks.
- This helps avoid catastrophic forgetting, where neural networks forget previously learned knowledge when adapting to new tasks.
Plain English Explanation
The paper introduces a new way for neural networks to continuously learn new information without completely forgetting what they've learned before. This is an important challenge, as neural networks often struggle with "catastrophic forgetting" - when they adapt to learn a new task, they can end up losing the knowledge they had previously learned.
The core of the researchers' approach is to have the neural network selectively pay attention to relevant past knowledge when learning a new task. This "attention" mechanism allows the network to incorporate useful prior knowledge while still being able to learn new things. By focusing on what's most important from the past, the network can continue expanding its capabilities without completely wiping out its previous understanding.
The paper demonstrates how this attention-based approach outperforms standard continual learning techniques on several benchmark tasks. This suggests it could be a promising direction for enabling neural networks to learn continually in a more effective and robust way.
Technical Explanation
The paper introduces a novel continual learning framework called "Learning to Learn without Forgetting using Attention" (L2L-A). The key innovation is the use of an attention mechanism to selectively leverage relevant past knowledge when learning new tasks.
Specifically, the authors propose an architecture with two main components:
-
Task-specific Encoder: This encodes the current task input into a latent representation.
-
Attention-based Decoder: This decoder attends over representations of past tasks to extract relevant knowledge, which is then combined with the current task encoding to produce the output.
The attention mechanism allows the model to focus on the most salient aspects of prior knowledge when adapting to a new task. This helps mitigate catastrophic forgetting, where neural networks tend to completely overwrite previously learned information.
The authors evaluate L2L-A on several continual learning benchmarks, including permuted MNIST, split CIFAR-100, and multi-task Atari games. They demonstrate that L2L-A outperforms strong baselines like elastic weight consolidation (EWC) and gradual learning. The attention-based approach allows the model to selectively retain relevant knowledge from the past while still effectively learning new tasks.
Critical Analysis
The key strength of this work is the novel use of attention mechanisms to enable more effective continual learning. By selectively attending to relevant past knowledge, the model can expand its capabilities without entirely forgetting what it has learned before.
That said, the paper does not explore some important limitations and potential issues with this approach:
-
The computational and memory costs of the attention mechanism are not fully addressed. Attending over all past task representations could become prohibitively expensive as the number of tasks grows.
-
The paper only evaluates on relatively simple benchmark tasks. It's unclear how well the approach would scale to more complex, real-world continual learning problems.
-
The authors do not provide a thorough theoretical understanding of why the attention-based approach is more effective than other continual learning techniques. More analysis is needed to fully explain the performance gains.
-
The generalization of the L2L-A framework to other neural architectures beyond the specific encoder-decoder setup is not explored. Its broader applicability remains to be seen.
Overall, this is a promising step towards improving continual learning, but further research is needed to fully understand the strengths, limitations, and scalability of this attention-based approach.
Conclusion
This paper presents a novel continual learning framework called L2L-A that leverages attention mechanisms to selectively retain and utilize relevant past knowledge when learning new tasks. By allowing the model to focus on the most salient aspects of prior experience, L2L-A is able to outperform standard continual learning baselines on several benchmark problems.
While this work demonstrates the potential of attention-based continual learning, further research is needed to fully understand the approach's strengths, limitations, and broader applicability. Nonetheless, this paper represents an important contribution to the ongoing efforts to enable neural networks to continuously expand their capabilities without catastrophically forgetting their previous knowledge.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning to Learn without Forgetting using Attention
Anna Vettoruzzo, Joaquin Vanschoren, Mohamed-Rafik Bouguelia, Thorsteinn Rognvaldsson
Continual learning (CL) refers to the ability to continually learn over time by accommodating new knowledge while retaining previously learned experience. While this concept is inherent in human learning, current machine learning methods are highly prone to overwrite previously learned patterns and thus forget past experience. Instead, model parameters should be updated selectively and carefully, avoiding unnecessary forgetting while optimally leveraging previously learned patterns to accelerate future learning. Since hand-crafting effective update mechanisms is difficult, we propose meta-learning a transformer-based optimizer to enhance CL. This meta-learned optimizer uses attention to learn the complex relationships between model parameters across a stream of tasks, and is designed to generate effective weight updates for the current task while preventing catastrophic forgetting on previously encountered tasks. Evaluations on benchmark datasets like SplitMNIST, RotatedMNIST, and SplitCIFAR-100 affirm the efficacy of the proposed approach in terms of both forward and backward transfer, even on small sets of labeled data, highlighting the advantages of integrating a meta-learned optimizer within the continual learning framework.
Read more8/15/2024
0
Remembering Transformer for Continual Learning
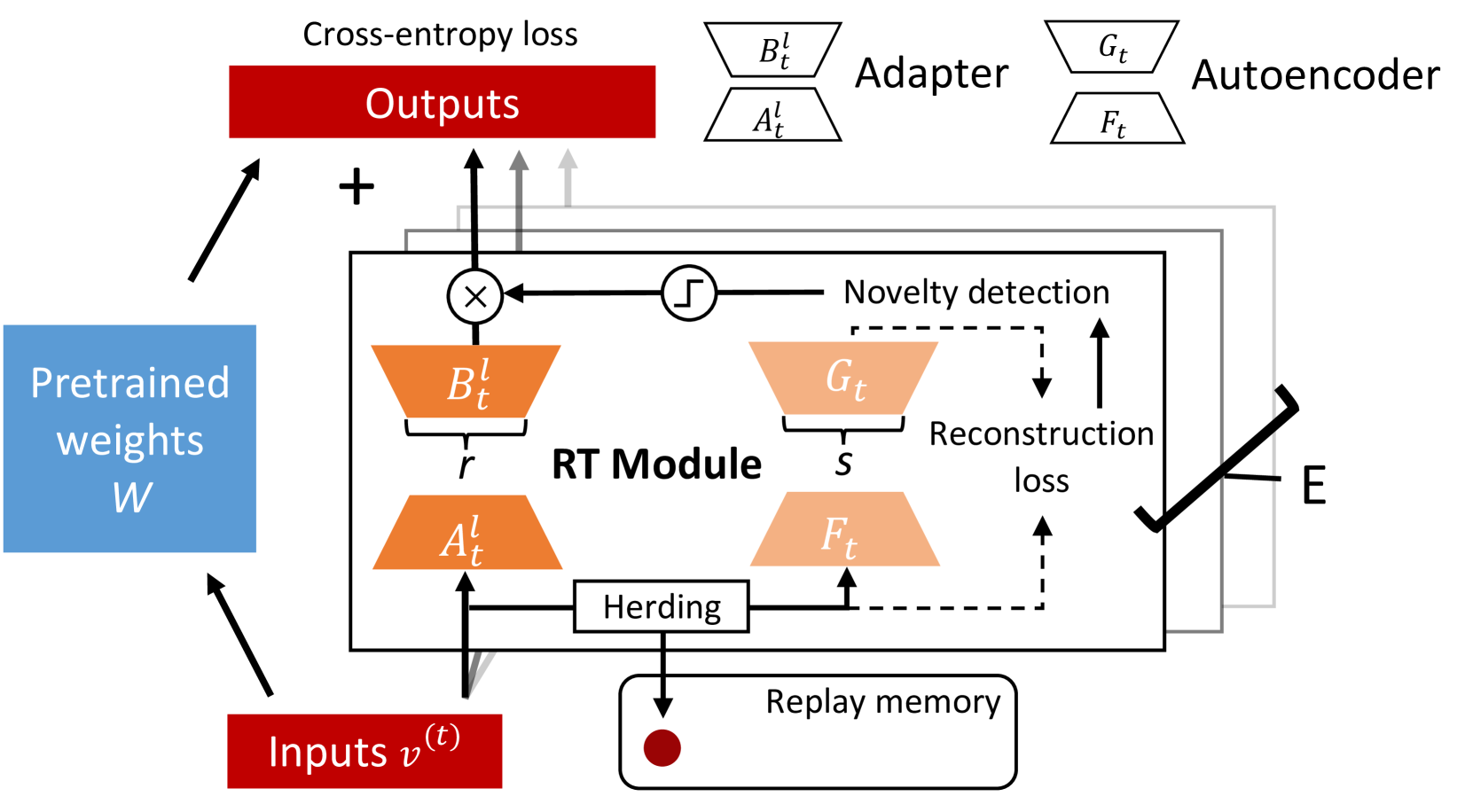
Yuwei Sun, Ippei Fujisawa, Arthur Juliani, Jun Sakuma, Ryota Kanai
Neural networks encounter the challenge of Catastrophic Forgetting (CF) in continual learning, where new task learning interferes with previously learned knowledge. Existing data fine-tuning and regularization methods necessitate task identity information during inference and cannot eliminate interference among different tasks, while soft parameter sharing approaches encounter the problem of an increasing model parameter size. To tackle these challenges, we propose the Remembering Transformer, inspired by the brain's Complementary Learning Systems (CLS). Remembering Transformer employs a mixture-of-adapters architecture and a generative model-based novelty detection mechanism in a pretrained Transformer to alleviate CF. Remembering Transformer dynamically routes task data to the most relevant adapter with enhanced parameter efficiency based on knowledge distillation. We conducted extensive experiments, including ablation studies on the novelty detection mechanism and model capacity of the mixture-of-adapters, in a broad range of class-incremental split tasks and permutation tasks. Our approach demonstrated SOTA performance surpassing the second-best method by 15.90% in the split tasks, reducing the memory footprint from 11.18M to 0.22M in the five splits CIFAR10 task.
Read more5/17/2024
0
Realistic Continual Learning Approach using Pre-trained Models
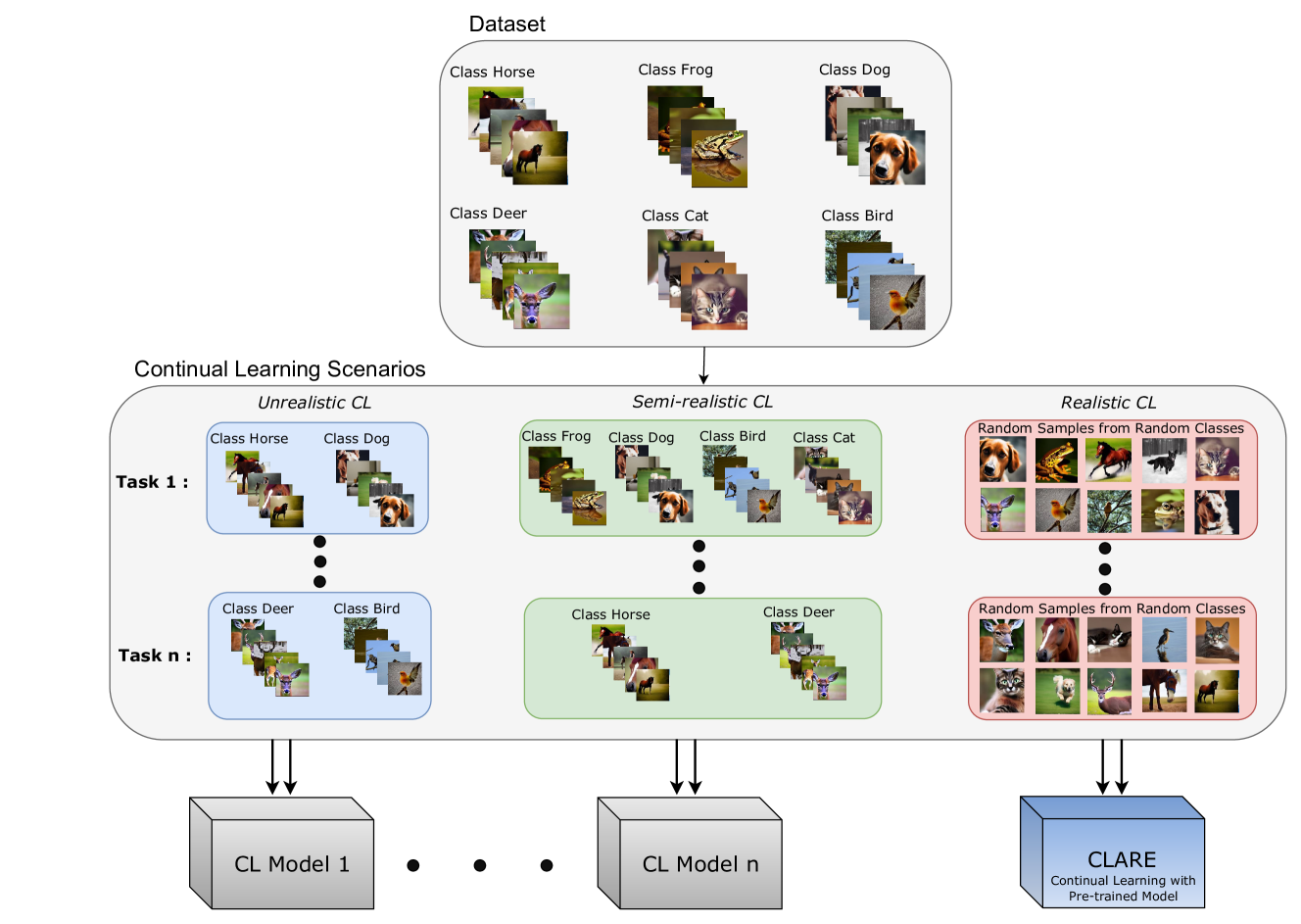
Nadia Nasri, Carlos Guti'errez-'Alvarez, Sergio Lafuente-Arroyo, Saturnino Maldonado-Basc'on, Roberto J. L'opez-Sastre
Continual learning (CL) is crucial for evaluating adaptability in learning solutions to retain knowledge. Our research addresses the challenge of catastrophic forgetting, where models lose proficiency in previously learned tasks as they acquire new ones. While numerous solutions have been proposed, existing experimental setups often rely on idealized class-incremental learning scenarios. We introduce Realistic Continual Learning (RealCL), a novel CL paradigm where class distributions across tasks are random, departing from structured setups. We also present CLARE (Continual Learning Approach with pRE-trained models for RealCL scenarios), a pre-trained model-based solution designed to integrate new knowledge while preserving past learning. Our contributions include pioneering RealCL as a generalization of traditional CL setups, proposing CLARE as an adaptable approach for RealCL tasks, and conducting extensive experiments demonstrating its effectiveness across various RealCL scenarios. Notably, CLARE outperforms existing models on RealCL benchmarks, highlighting its versatility and robustness in unpredictable learning environments.
Read more4/12/2024
0
Improving Data-aware and Parameter-aware Robustness for Continual Learning
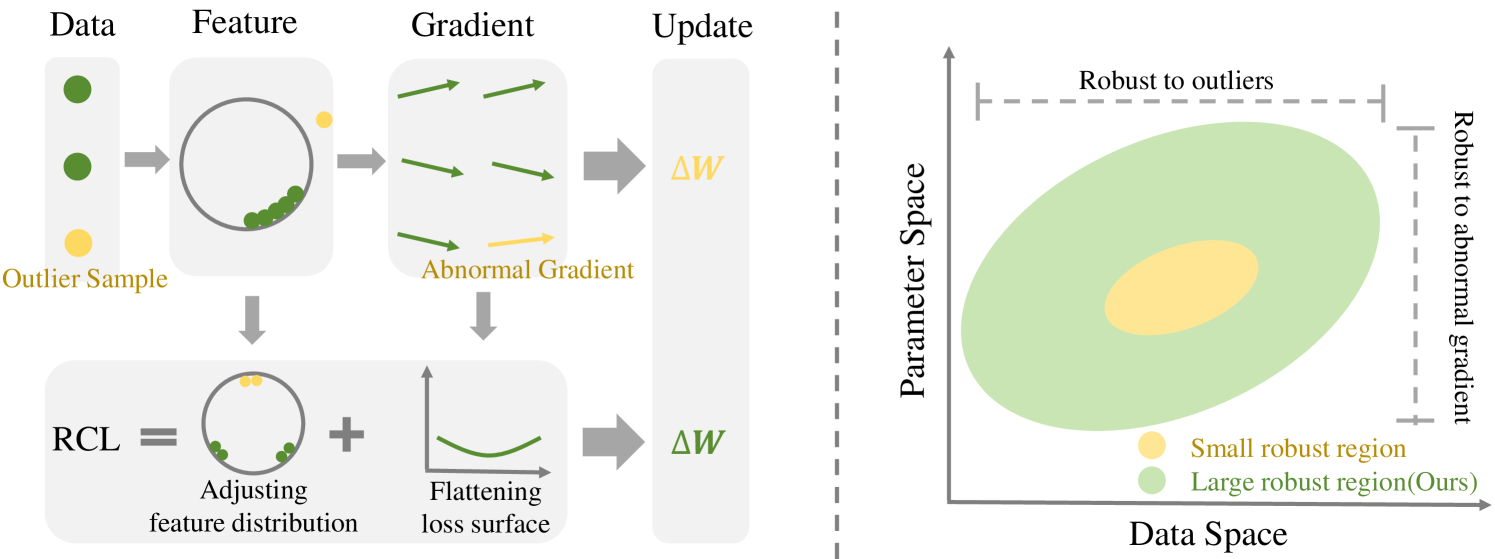
Hanxi Xiao, Fan Lyu
The goal of Continual Learning (CL) task is to continuously learn multiple new tasks sequentially while achieving a balance between the plasticity and stability of new and old knowledge. This paper analyzes that this insufficiency arises from the ineffective handling of outliers, leading to abnormal gradients and unexpected model updates. To address this issue, we enhance the data-aware and parameter-aware robustness of CL, proposing a Robust Continual Learning (RCL) method. From the data perspective, we develop a contrastive loss based on the concepts of uniformity and alignment, forming a feature distribution that is more applicable to outliers. From the parameter perspective, we present a forward strategy for worst-case perturbation and apply robust gradient projection to the parameters. The experimental results on three benchmarks show that the proposed method effectively maintains robustness and achieves new state-of-the-art (SOTA) results. The code is available at: https://github.com/HanxiXiao/RCL
Read more5/28/2024