Anytime-valid off-policy inference for contextual bandits

0
🤯
Sign in to get full access
Overview
- Contextual bandit algorithms are used for active sequential experimentation in healthcare and tech.
- They involve online learning algorithms that adapt policies over time to map contexts to actions and maximize rewards.
- This adaptivity raises challenging statistical inference questions, especially regarding counterfactual policies.
- The paper presents a framework for "off-policy evaluation" (OPE) - estimating properties of a policy different from the one used to collect the data.
Plain English Explanation
Contextual bandits are a type of machine learning algorithm used in industries like healthcare and tech. They help systems learn which actions to take in different situations in order to maximize some reward.
For example, an online recommendation system might use a contextual bandit to decide which products to show a user based on their browsing history and other information. The system starts off making random recommendations, but over time it learns which recommendations tend to lead to the most sales (the "reward").
This adaptivity - the system continuously learning and updating its strategy - makes it challenging to analyze. Researchers are often interested in estimating what would happen if a different strategy (a "counterfactual policy") had been used. This is called "off-policy evaluation" (OPE).
The paper presents new statistical techniques that enable doing OPE more effectively than previous methods. These techniques have several advantages:
- They can be used while the original experiment is still ongoing, not just afterwards.
- They work even if the original policy is changing over time due to learning.
- They don't require strict assumptions about the data or importance weights.
Overall, the paper provides powerful new tools for analyzing and understanding the behavior of contextual bandits in real-world applications.
Technical Explanation
The paper focuses on the problem of off-policy evaluation (OPE) for contextual bandits. OPE involves estimating the properties of a hypothetical policy that is different from the one used to collect the original data.
Using modern martingale techniques, the authors develop a comprehensive framework for OPE inference that relaxes unnecessary conditions made in past work. This significantly improves on previous methods both theoretically and empirically.
Importantly, the new methods:
- Can be used while the original experiment is still running, not just post-hoc.
- Work even if the logging policy is changing over time due to learning.
- Handle highly dependent time-series context distributions, like drifting contexts.
The paper derives confidence sequences for various OPE quantities of interest. This includes doubly robust estimators for time-varying off-policy mean rewards, as well as confidence bands for the entire off-policy reward distribution.
Crucially, all the methods:
a) Are valid at arbitrary stopping times b) Make only nonparametric assumptions c) Do not require importance weights to be bounded d) Adapt to the empirical variance of the estimators
In summary, the paper presents powerful new tools for conducting anytime-valid off-policy inference using adaptively collected contextual bandit data.
Critical Analysis
The paper makes a number of valuable contributions to the field of contextual bandits and off-policy evaluation. The new OPE inference framework relaxes several restrictive assumptions made in prior work, significantly expanding the applicability of these methods.
However, the authors do acknowledge some limitations. For example, the methods require that the context process satisfies certain mixing and moment conditions, which may not hold in all real-world scenarios. Additionally, the confidence intervals and bands derived in the paper, while valid, may be quite wide in practice depending on the problem setting.
It would also be interesting to see the methods tested on a wider range of contextual bandit problems beyond the specific simulation setups considered. This could help validate the robustness of the techniques across diverse applications.
Overall, though, this work represents an important advance in our ability to reason about and draw sound statistical conclusions from adaptively collected contextual bandit data. The new tools provided by the authors should prove invaluable for researchers and practitioners working in this area.
Conclusion
This paper presents a comprehensive framework for off-policy evaluation (OPE) of contextual bandit algorithms. The key innovation is the development of new statistical inference techniques that relax unnecessary assumptions made by prior OPE methods, enabling anytime-valid off-policy analysis.
These advances unlock the ability to rigorously evaluate counterfactual policies using data collected through adaptive, online learning algorithms. This is a critical capability for industries like healthcare and tech that rely heavily on contextual bandits to make high-stakes decisions.
By expanding the scope and robustness of OPE, this work represents an important step forward in our ability to understand, audit, and optimize the behavior of these ubiquitous machine learning systems. The implications could be far-reaching, from improving the safety and fairness of automated decision-making to accelerating innovation through more effective experimentation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤯
0
Anytime-valid off-policy inference for contextual bandits
Ian Waudby-Smith, Lili Wu, Aaditya Ramdas, Nikos Karampatziakis, Paul Mineiro
Contextual bandit algorithms are ubiquitous tools for active sequential experimentation in healthcare and the tech industry. They involve online learning algorithms that adaptively learn policies over time to map observed contexts $X_t$ to actions $A_t$ in an attempt to maximize stochastic rewards $R_t$. This adaptivity raises interesting but hard statistical inference questions, especially counterfactual ones: for example, it is often of interest to estimate the properties of a hypothetical policy that is different from the logging policy that was used to collect the data -- a problem known as ``off-policy evaluation'' (OPE). Using modern martingale techniques, we present a comprehensive framework for OPE inference that relax unnecessary conditions made in some past works, significantly improving on them both theoretically and empirically. Importantly, our methods can be employed while the original experiment is still running (that is, not necessarily post-hoc), when the logging policy may be itself changing (due to learning), and even if the context distributions are a highly dependent time-series (such as if they are drifting over time). More concretely, we derive confidence sequences for various functionals of interest in OPE. These include doubly robust ones for time-varying off-policy mean reward values, but also confidence bands for the entire cumulative distribution function of the off-policy reward distribution. All of our methods (a) are valid at arbitrary stopping times (b) only make nonparametric assumptions, (c) do not require importance weights to be uniformly bounded and if they are, we do not need to know these bounds, and (d) adapt to the empirical variance of our estimators. In summary, our methods enable anytime-valid off-policy inference using adaptively collected contextual bandit data.
Read more8/19/2024
0
Effective Off-Policy Evaluation and Learning in Contextual Combinatorial Bandits
Tatsuhiro Shimizu, Koichi Tanaka, Ren Kishimoto, Haruka Kiyohara, Masahiro Nomura, Yuta Saito
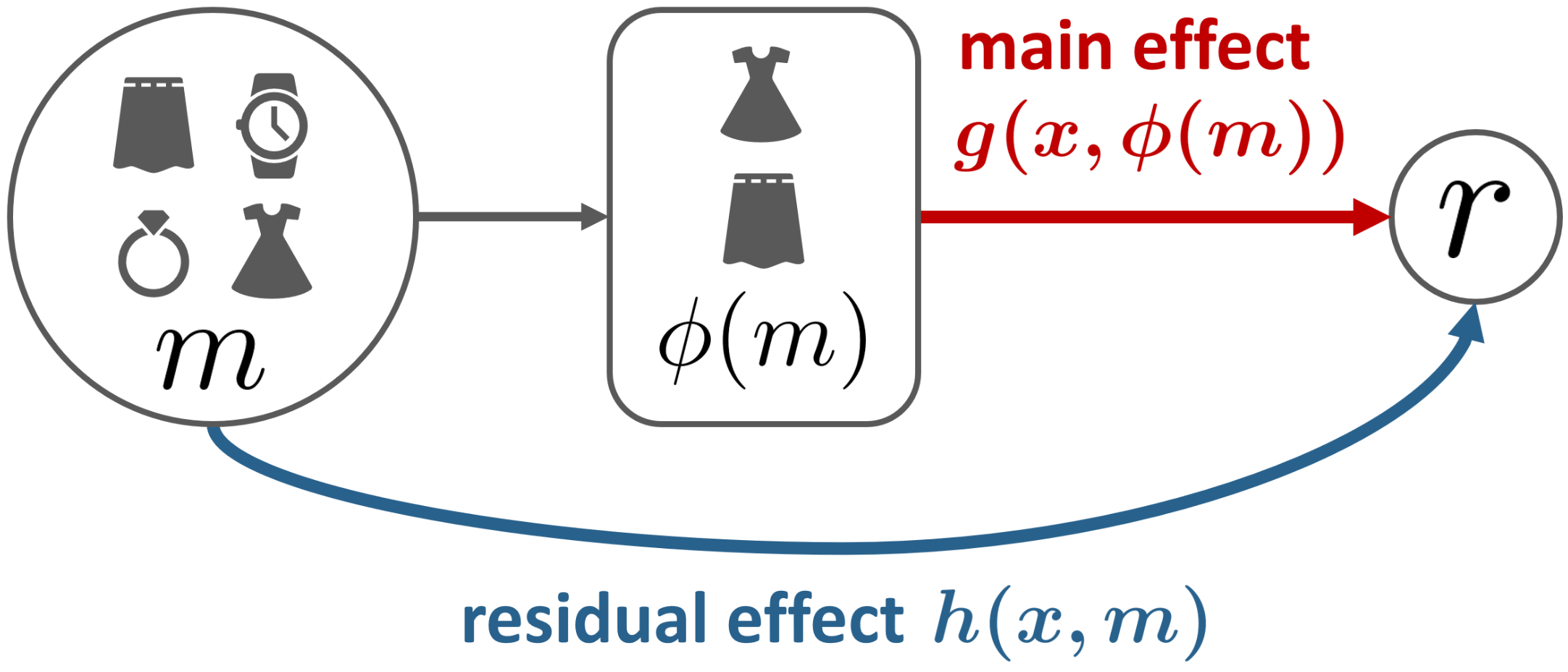
We explore off-policy evaluation and learning (OPE/L) in contextual combinatorial bandits (CCB), where a policy selects a subset in the action space. For example, it might choose a set of furniture pieces (a bed and a drawer) from available items (bed, drawer, chair, etc.) for interior design sales. This setting is widespread in fields such as recommender systems and healthcare, yet OPE/L of CCB remains unexplored in the relevant literature. Typical OPE/L methods such as regression and importance sampling can be applied to the CCB problem, however, they face significant challenges due to high bias or variance, exacerbated by the exponential growth in the number of available subsets. To address these challenges, we introduce a concept of factored action space, which allows us to decompose each subset into binary indicators. This formulation allows us to distinguish between the ''main effect'' derived from the main actions, and the ''residual effect'', originating from the supplemental actions, facilitating more effective OPE. Specifically, our estimator, called OPCB, leverages an importance sampling-based approach to unbiasedly estimate the main effect, while employing regression-based approach to deal with the residual effect with low variance. OPCB achieves substantial variance reduction compared to conventional importance sampling methods and bias reduction relative to regression methods under certain conditions, as illustrated in our theoretical analysis. Experiments demonstrate OPCB's superior performance over typical methods in both OPE and OPL.
Read more8/22/2024
⛏️
0
Off-Policy Evaluation Using Information Borrowing and Context-Based Switching
Sutanoy Dasgupta, Yabo Niu, Kishan Panaganti, Dileep Kalathil, Debdeep Pati, Bani Mallick
We consider the off-policy evaluation (OPE) problem in contextual bandits, where the goal is to estimate the value of a target policy using the data collected by a logging policy. Most popular approaches to the OPE are variants of the doubly robust (DR) estimator obtained by combining a direct method (DM) estimator and a correction term involving the inverse propensity score (IPS). Existing algorithms primarily focus on strategies to reduce the variance of the DR estimator arising from large IPS. We propose a new approach called the Doubly Robust with Information borrowing and Context-based switching (DR-IC) estimator that focuses on reducing both bias and variance. The DR-IC estimator replaces the standard DM estimator with a parametric reward model that borrows information from the 'closer' contexts through a correlation structure that depends on the IPS. The DR-IC estimator also adaptively interpolates between this modified DM estimator and a modified DR estimator based on a context-specific switching rule. We give provable guarantees on the performance of the DR-IC estimator. We also demonstrate the superior performance of the DR-IC estimator compared to the state-of-the-art OPE algorithms on a number of benchmark problems.
Read more8/20/2024

0
Optimal Baseline Corrections for Off-Policy Contextual Bandits
Shashank Gupta, Olivier Jeunen, Harrie Oosterhuis, Maarten de Rijke
The off-policy learning paradigm allows for recommender systems and general ranking applications to be framed as decision-making problems, where we aim to learn decision policies that optimize an unbiased offline estimate of an online reward metric. With unbiasedness comes potentially high variance, and prevalent methods exist to reduce estimation variance. These methods typically make use of control variates, either additive (i.e., baseline corrections or doubly robust methods) or multiplicative (i.e., self-normalisation). Our work unifies these approaches by proposing a single framework built on their equivalence in learning scenarios. The foundation of our framework is the derivation of an equivalent baseline correction for all of the existing control variates. Consequently, our framework enables us to characterize the variance-optimal unbiased estimator and provide a closed-form solution for it. This optimal estimator brings significantly improved performance in both evaluation and learning, and minimizes data requirements. Empirical observations corroborate our theoretical findings.
Read more8/15/2024