Batched Nonparametric Contextual Bandits

0
Sign in to get full access
Overview
- This paper presents a novel approach to the nonparametric contextual bandit problem, where a decision-maker must choose an action (e.g., which advertisement to show) based on the current context (e.g., user characteristics) to maximize cumulative reward over time.
- The key innovation is a "batched" framework, where the decision-maker makes a sequence of decisions in batches rather than one at a time.
- The authors develop a provably near-optimal algorithm for this batched setting and demonstrate its effectiveness through theoretical analysis and empirical evaluation.
Plain English Explanation
In many real-world decision-making scenarios, we need to choose an action (like which advertisement to show) based on the current situation or "context" (like user characteristics) in order to get the best overall outcome over time. This is known as the contextual bandit problem.
The authors of this paper found a new way to approach this problem that organizes the decisions into "batches" rather than making them one-by-one. This batched approach has some advantages - it can be more efficient and practical in certain situations.
The paper introduces a new algorithm that is designed to work well in this batched contextual bandit setting. Through mathematical analysis and experiments, the researchers show that their algorithm can perform nearly as well as the best possible approach, even in complex, real-world-like scenarios.
This work extends our understanding of contextual bandits and provides a new, potentially more practical framework for applying these techniques in applications like online advertising, recommendation systems, and beyond.
Technical Explanation
The authors consider a nonparametric contextual bandit problem, where the reward function mapping contexts to rewards is assumed to be an unknown Lipschitz continuous function. They propose a "batched" framework, where the decision-maker makes a sequence of decisions in batches of size B rather than one at a time.
They develop a novel algorithm called Batched Kernel UCB (BKUCB) that leverages kernel methods to learn the unknown reward function. BKUCB operates in rounds, where in each round it selects a batch of B actions based on the current context, observes the rewards for that batch, and then updates its estimate of the reward function.
Through a careful theoretical analysis, the authors show that BKUCB achieves (near-)optimal regret bounds that scale favorably with the batch size B. They also demonstrate the practical effectiveness of BKUCB through experiments on both synthetic and real-world datasets, including applications in online advertising and recommendation systems.
Critical Analysis
The authors acknowledge several limitations of their approach. First, BKUCB requires knowledge of the Lipschitz constant of the underlying reward function, which may be difficult to obtain in practice. The authors suggest using a conservative estimate, but this could lead to suboptimal performance.
Additionally, the theoretical analysis assumes the reward function is Lipschitz continuous, which may not always hold in real-world applications. Extensions to other function classes could improve the versatility of the approach.
Finally, the batched framework introduces a trade-off between exploration and exploitation that is not present in the standard contextual bandit setting. The authors' analysis shows BKUCB can nearly match the performance of the optimal algorithm, but further research is needed to fully understand this trade-off and its implications.
Conclusion
This paper presents a novel batched framework for the nonparametric contextual bandit problem and introduces an effective algorithm, BKUCB, to solve it. The batched approach can offer practical advantages, and the theoretical and empirical results demonstrate the strong performance of BKUCB.
While the approach has some limitations, this work extends the state of the art in contextual bandits and opens up new directions for applying these techniques to real-world problems in areas like online advertising, recommendation systems, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Batched Nonparametric Contextual Bandits
Rong Jiang, Cong Ma
We study nonparametric contextual bandits under batch constraints, where the expected reward for each action is modeled as a smooth function of covariates, and the policy updates are made at the end of each batch of observations. We establish a minimax regret lower bound for this setting and propose a novel batch learning algorithm that achieves the optimal regret (up to logarithmic factors). In essence, our procedure dynamically splits the covariate space into smaller bins, carefully aligning their widths with the batch size. Our theoretical results suggest that for nonparametric contextual bandits, a nearly constant number of policy updates can attain optimal regret in the fully online setting.
Read more6/12/2024

0
Contextual Bandits for Unbounded Context Distributions
Puning Zhao, Jiafei Wu, Zhe Liu, Huiwen Wu
Nonparametric contextual bandit is an important model of sequential decision making problems. Under $alpha$-Tsybakov margin condition, existing research has established a regret bound of $tilde{O}left(T^{1-frac{alpha+1}{d+2}}right)$ for bounded supports. However, the optimal regret with unbounded contexts has not been analyzed. The challenge of solving contextual bandit problems with unbounded support is to achieve both exploration-exploitation tradeoff and bias-variance tradeoff simultaneously. In this paper, we solve the nonparametric contextual bandit problem with unbounded contexts. We propose two nearest neighbor methods combined with UCB exploration. The first method uses a fixed $k$. Our analysis shows that this method achieves minimax optimal regret under a weak margin condition and relatively light-tailed context distributions. The second method uses adaptive $k$. By a proper data-driven selection of $k$, this method achieves an expected regret of $tilde{O}left(T^{1-frac{(alpha+1)beta}{alpha+(d+2)beta}}+T^{1-beta}right)$, in which $beta$ is a parameter describing the tail strength. This bound matches the minimax lower bound up to logarithm factors, indicating that the second method is approximately optimal.
Read more8/20/2024
0
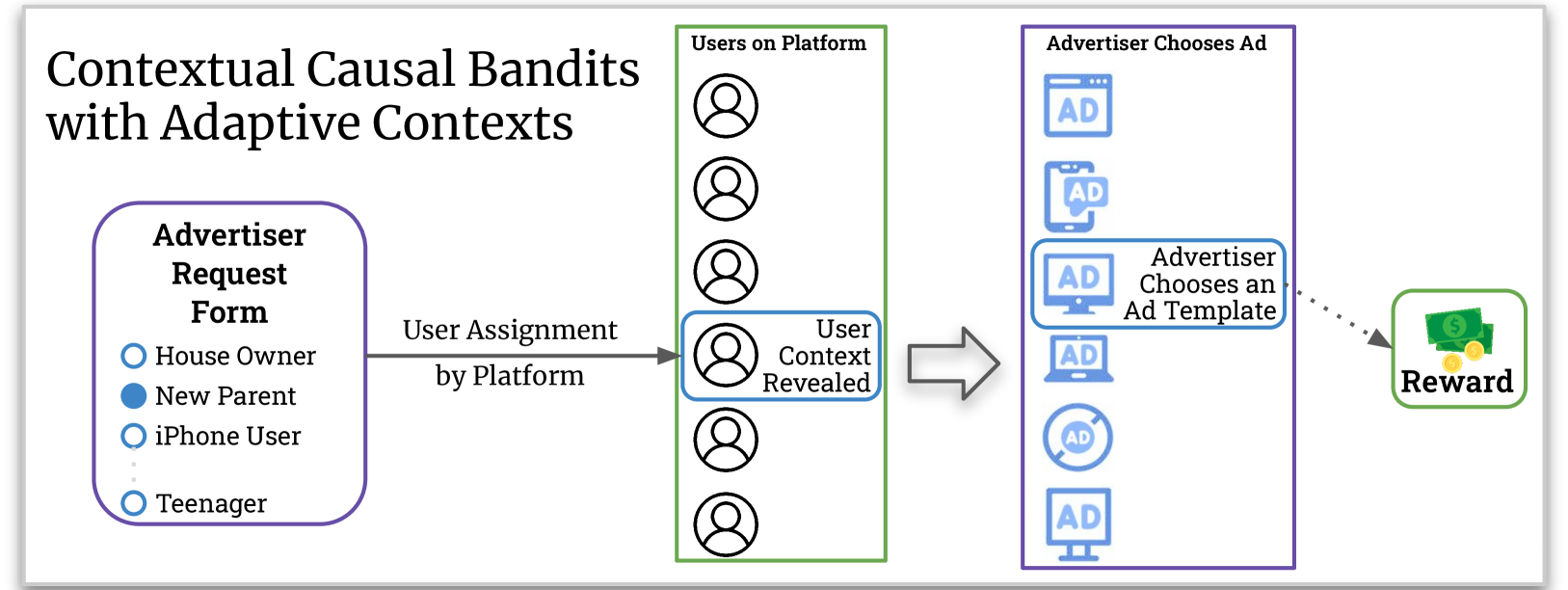
Causal Contextual Bandits with Adaptive Context
Rahul Madhavan, Aurghya Maiti, Gaurav Sinha, Siddharth Barman
We study a variant of causal contextual bandits where the context is chosen based on an initial intervention chosen by the learner. At the beginning of each round, the learner selects an initial action, depending on which a stochastic context is revealed by the environment. Following this, the learner then selects a final action and receives a reward. Given $T$ rounds of interactions with the environment, the objective of the learner is to learn a policy (of selecting the initial and the final action) with maximum expected reward. In this paper we study the specific situation where every action corresponds to intervening on a node in some known causal graph. We extend prior work from the deterministic context setting to obtain simple regret minimization guarantees. This is achieved through an instance-dependent causal parameter, $lambda$, which characterizes our upper bound. Furthermore, we prove that our simple regret is essentially tight for a large class of instances. A key feature of our work is that we use convex optimization to address the bandit exploration problem. We also conduct experiments to validate our theoretical results, and release our code at our project GitHub repository: https://github.com/adaptiveContextualCausalBandits/aCCB.
Read more6/4/2024
🛠️
0
Online Continuous Hyperparameter Optimization for Generalized Linear Contextual Bandits
Yue Kang, Cho-Jui Hsieh, Thomas C. M. Lee
In stochastic contextual bandits, an agent sequentially makes actions from a time-dependent action set based on past experience to minimize the cumulative regret. Like many other machine learning algorithms, the performance of bandits heavily depends on the values of hyperparameters, and theoretically derived parameter values may lead to unsatisfactory results in practice. Moreover, it is infeasible to use offline tuning methods like cross-validation to choose hyperparameters under the bandit environment, as the decisions should be made in real-time. To address this challenge, we propose the first online continuous hyperparameter tuning framework for contextual bandits to learn the optimal parameter configuration in practice within a search space on the fly. Specifically, we use a double-layer bandit framework named CDT (Continuous Dynamic Tuning) and formulate the hyperparameter optimization as a non-stationary continuum-armed bandit, where each arm represents a combination of hyperparameters, and the corresponding reward is the algorithmic result. For the top layer, we propose the Zooming TS algorithm that utilizes Thompson Sampling (TS) for exploration and a restart technique to get around the textit{switching} environment. The proposed CDT framework can be easily utilized to tune contextual bandit algorithms without any pre-specified candidate set for multiple hyperparameters. We further show that it could achieve a sublinear regret in theory and performs consistently better than all existing methods on both synthetic and real datasets.
Read more4/9/2024