Apollo: A Lightweight Multilingual Medical LLM towards Democratizing Medical AI to 6B People
2403.03640
0
0

Abstract
Despite the vast repository of global medical knowledge predominantly being in English, local languages are crucial for delivering tailored healthcare services, particularly in areas with limited medical resources. To extend the reach of medical AI advancements to a broader population, we aim to develop medical LLMs across the six most widely spoken languages, encompassing a global population of 6.1 billion. This effort culminates in the creation of the ApolloCorpora multilingual medical dataset and the XMedBench benchmark. In the multilingual medical benchmark, the released Apollo models, at various relatively-small sizes (i.e., 0.5B, 1.8B, 2B, 6B, and 7B), achieve the best performance among models of equivalent size. Especially, Apollo-7B is the state-of-the-art multilingual medical LLMs up to 70B. Additionally, these lite models could be used to improve the multi-lingual medical capabilities of larger models without fine-tuning in a proxy-tuning fashion. We will open-source training corpora, code, model weights and evaluation benchmark.
Create account to get full access
Overview
- This paper proposes a new lightweight and multilingual medical language model called Apollo, aimed at democratizing medical AI to the global population of 6 billion people.
- The researchers conducted a pilot study to assess the multilinguality of existing medical language models, finding significant performance gaps across languages.
- To address these gaps, the paper introduces the Apollo model architecture and training approach, designed to enable high-quality medical language understanding and generation in multiple languages.
- The researchers evaluate Apollo's performance on a range of medical language tasks, demonstrating its strong capabilities compared to existing models.
Plain English Explanation
The researchers who wrote this paper were concerned that existing medical language models, which are used for tasks like medical diagnosis and treatment recommendations, were not performing well in languages other than English. This means that most of the world's population, who do not speak English as their first language, may not be able to fully benefit from the latest advancements in medical AI.
To address this problem, the researchers developed a new model called Apollo. Apollo is designed to be "lightweight" and work well in multiple languages, including non-English languages. The researchers first did a pilot study to understand the limitations of existing medical language models in different languages. They then used this information to design the Apollo model architecture and training approach, which aims to enable high-quality medical language understanding and generation across many languages.
The researchers evaluated Apollo's performance on various medical language tasks and found that it outperformed existing models, even in non-English languages. This suggests that Apollo could help make the latest advancements in medical AI more accessible to the global population, not just those who speak English.
Technical Explanation
The researchers conducted a pilot study to assess the multilinguality of existing medical language models. They found significant performance gaps across languages, with models performing much better in English than in other languages. To address this, the researchers developed the Apollo model, which uses a lightweight and efficient architecture designed for multilingual medical language understanding and generation.
The Apollo model architecture is based on the Medical MT5 model, but with several modifications to improve its multilingual capabilities. These include using lightweight Transformer layers, integrating medical-specific knowledge, and employing specialized training techniques.
The researchers evaluated Apollo on a range of medical language tasks, including medical question answering, medical summarization, and medical entity recognition. They compared Apollo's performance to existing state-of-the-art medical language models and found that Apollo outperformed these models, particularly in non-English languages.
Critical Analysis
The researchers acknowledge several limitations of the current work, including the relatively small size of the multilingual medical datasets used for training and evaluation. They also note that while Apollo demonstrates strong performance, there is still room for improvement, especially in low-resource languages.
Additionally, the researchers did not compare Apollo to specialized medical language models developed for specific languages, which may outperform Apollo in those languages. Further research is needed to understand the tradeoffs between a multilingual approach like Apollo and more targeted, language-specific models.
It would also be valuable to see how Apollo performs on real-world medical tasks, such as clinical decision support or patient-facing applications. The paper focuses on standard benchmarks, but the true test of Apollo's utility will be in its ability to assist medical professionals and patients in practical settings.
Conclusion
The Apollo model represents an important step towards democratizing medical AI by providing a high-performing, multilingual solution. The researchers' pilot study and model design choices demonstrate a thoughtful approach to addressing the multilinguality challenges in medical language models.
While further research is needed to fully realize Apollo's potential, this work highlights the importance of considering global accessibility when developing medical AI systems. By creating models that can operate effectively across languages, the researchers aim to bring the benefits of advanced medical technologies to a much wider audience worldwide.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
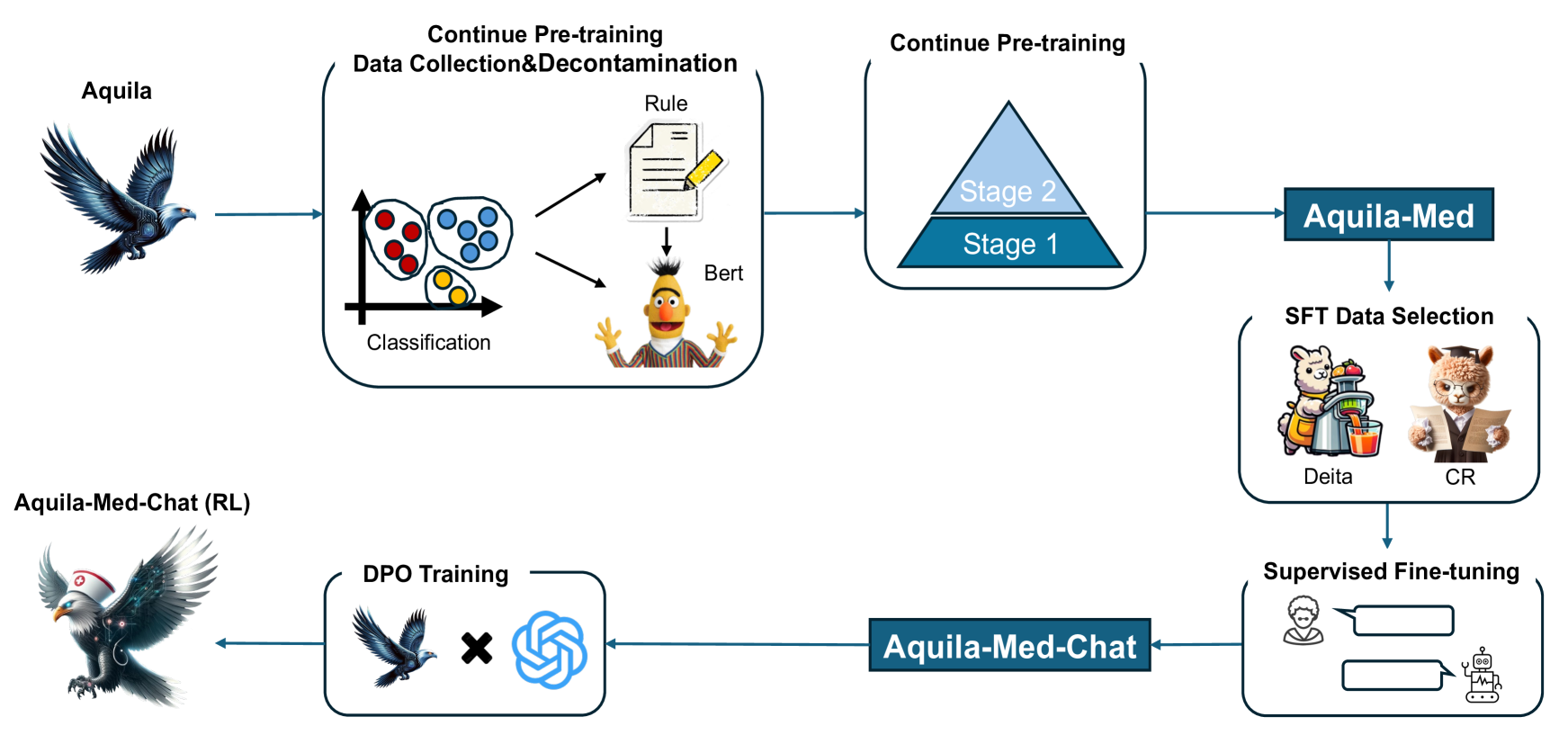
Aqulia-Med LLM: Pioneering Full-Process Open-Source Medical Language Models
Lulu Zhao, Weihao Zeng, Xiaofeng Shi, Hua Zhou, Donglin Hao, Yonghua Lin
0
0
Recently, both closed-source LLMs and open-source communities have made significant strides, outperforming humans in various general domains. However, their performance in specific professional fields such as medicine, especially within the open-source community, remains suboptimal due to the complexity of medical knowledge. We propose Aquila-Med, a bilingual medical LLM based on Aquila, addressing these challenges through continue pre-training, supervised fine-tuning (SFT), and reinforcement learning from human feedback (RLHF). We construct a large-scale Chinese and English medical dataset for continue pre-training and a high-quality SFT dataset, covering extensive medical specialties. Additionally, we develop a high-quality Direct Preference Optimization (DPO) dataset for further alignment. Aquila-Med achieves notable results across single-turn, multi-turn dialogues, and medical multiple-choice questions, demonstrating the effectiveness of our approach. We open-source the datasets and the entire training process, contributing valuable resources to the research community. Our models and datasets will released at https://huggingface.co/BAAI/AquilaMed-RL.
6/19/2024
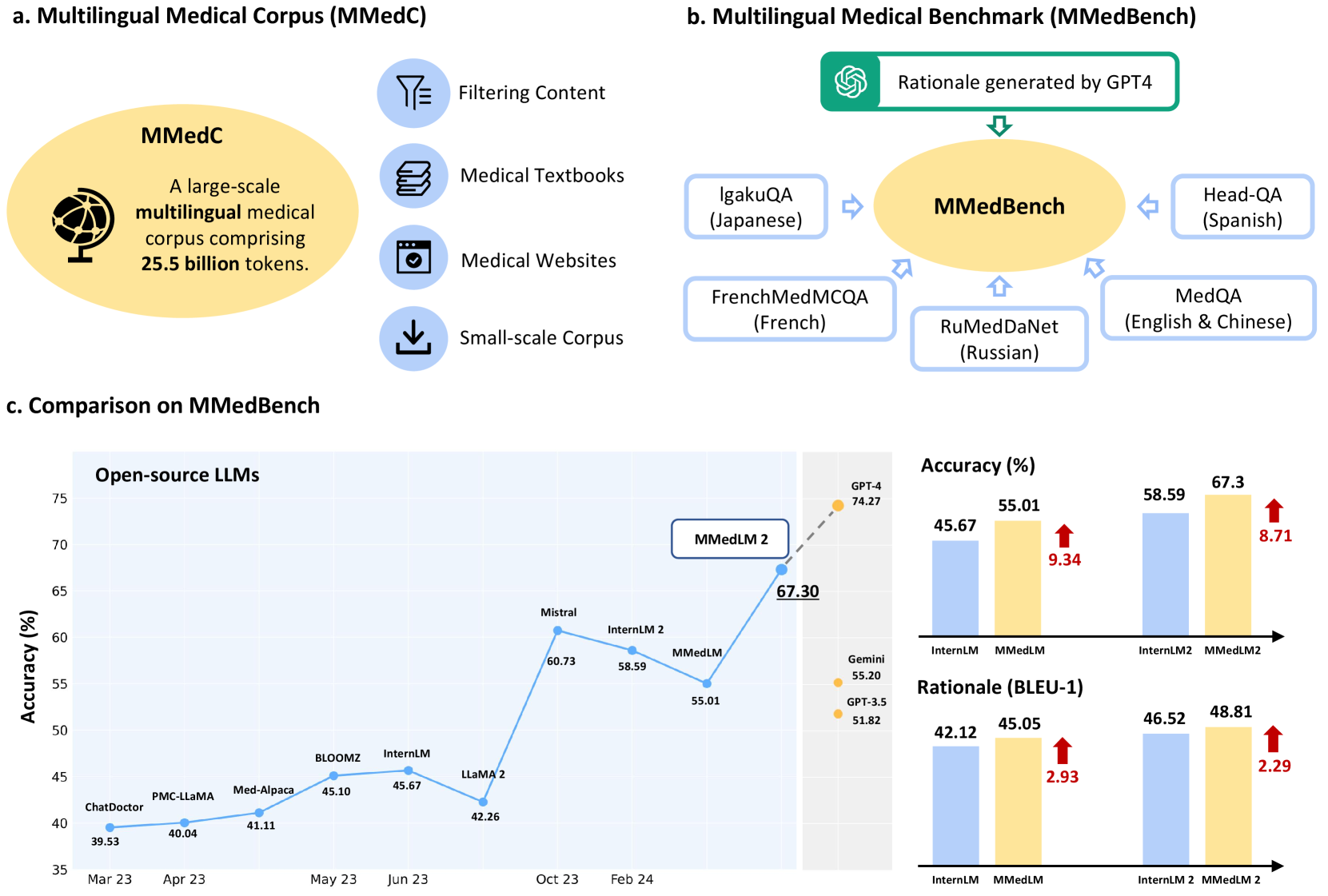
Towards Building Multilingual Language Model for Medicine
Pengcheng Qiu, Chaoyi Wu, Xiaoman Zhang, Weixiong Lin, Haicheng Wang, Ya Zhang, Yanfeng Wang, Weidi Xie
0
0
The development of open-source, multilingual medical language models can benefit a wide, linguistically diverse audience from different regions. To promote this domain, we present contributions from the following: First, we construct a multilingual medical corpus, containing approximately 25.5B tokens encompassing 6 main languages, termed as MMedC, enabling auto-regressive domain adaptation for general LLMs; Second, to monitor the development of multilingual medical LLMs, we propose a multilingual medical multi-choice question-answering benchmark with rationale, termed as MMedBench; Third, we have assessed a number of open-source large language models (LLMs) on our benchmark, along with those further auto-regressive trained on MMedC. Our final model, MMed-Llama 3, with only 8B parameters, achieves superior performance compared to all other open-source models on both MMedBench and English benchmarks, even rivaling GPT-4. In conclusion, in this work, we present a large-scale corpus, a benchmark and a series of models to support the development of multilingual medical LLMs.
6/4/2024
💬
Hippocrates: An Open-Source Framework for Advancing Large Language Models in Healthcare
Emre Can Acikgoz, Osman Batur .Ince, Rayene Bench, Arda An{i}l Boz, .Ilker Kesen, Aykut Erdem, Erkut Erdem
0
0
The integration of Large Language Models (LLMs) into healthcare promises to transform medical diagnostics, research, and patient care. Yet, the progression of medical LLMs faces obstacles such as complex training requirements, rigorous evaluation demands, and the dominance of proprietary models that restrict academic exploration. Transparent, comprehensive access to LLM resources is essential for advancing the field, fostering reproducibility, and encouraging innovation in healthcare AI. We present Hippocrates, an open-source LLM framework specifically developed for the medical domain. In stark contrast to previous efforts, it offers unrestricted access to its training datasets, codebase, checkpoints, and evaluation protocols. This open approach is designed to stimulate collaborative research, allowing the community to build upon, refine, and rigorously evaluate medical LLMs within a transparent ecosystem. Also, we introduce Hippo, a family of 7B models tailored for the medical domain, fine-tuned from Mistral and LLaMA2 through continual pre-training, instruction tuning, and reinforcement learning from human and AI feedback. Our models outperform existing open medical LLMs models by a large-margin, even surpassing models with 70B parameters. Through Hippocrates, we aspire to unlock the full potential of LLMs not just to advance medical knowledge and patient care but also to democratize the benefits of AI research in healthcare, making them available across the globe.
4/26/2024
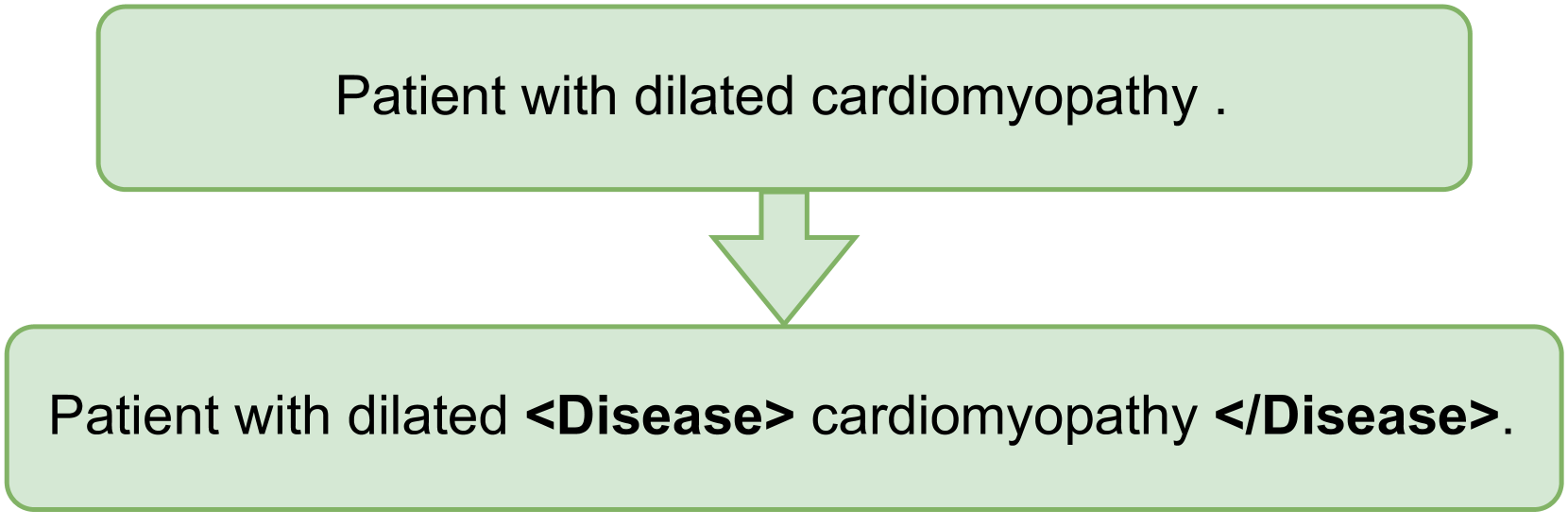
Medical mT5: An Open-Source Multilingual Text-to-Text LLM for The Medical Domain
Iker Garc'ia-Ferrero, Rodrigo Agerri, Aitziber Atutxa Salazar, Elena Cabrio, Iker de la Iglesia, Alberto Lavelli, Bernardo Magnini, Benjamin Molinet, Johana Ramirez-Romero, German Rigau, Jose Maria Villa-Gonzalez, Serena Villata, Andrea Zaninello
0
0
Research on language technology for the development of medical applications is currently a hot topic in Natural Language Understanding and Generation. Thus, a number of large language models (LLMs) have recently been adapted to the medical domain, so that they can be used as a tool for mediating in human-AI interaction. While these LLMs display competitive performance on automated medical texts benchmarks, they have been pre-trained and evaluated with a focus on a single language (English mostly). This is particularly true of text-to-text models, which typically require large amounts of domain-specific pre-training data, often not easily accessible for many languages. In this paper, we address these shortcomings by compiling, to the best of our knowledge, the largest multilingual corpus for the medical domain in four languages, namely English, French, Italian and Spanish. This new corpus has been used to train Medical mT5, the first open-source text-to-text multilingual model for the medical domain. Additionally, we present two new evaluation benchmarks for all four languages with the aim of facilitating multilingual research in this domain. A comprehensive evaluation shows that Medical mT5 outperforms both encoders and similarly sized text-to-text models for the Spanish, French, and Italian benchmarks, while being competitive with current state-of-the-art LLMs in English.
4/12/2024