Medical mT5: An Open-Source Multilingual Text-to-Text LLM for The Medical Domain
2404.07613
0
0
Abstract
Research on language technology for the development of medical applications is currently a hot topic in Natural Language Understanding and Generation. Thus, a number of large language models (LLMs) have recently been adapted to the medical domain, so that they can be used as a tool for mediating in human-AI interaction. While these LLMs display competitive performance on automated medical texts benchmarks, they have been pre-trained and evaluated with a focus on a single language (English mostly). This is particularly true of text-to-text models, which typically require large amounts of domain-specific pre-training data, often not easily accessible for many languages. In this paper, we address these shortcomings by compiling, to the best of our knowledge, the largest multilingual corpus for the medical domain in four languages, namely English, French, Italian and Spanish. This new corpus has been used to train Medical mT5, the first open-source text-to-text multilingual model for the medical domain. Additionally, we present two new evaluation benchmarks for all four languages with the aim of facilitating multilingual research in this domain. A comprehensive evaluation shows that Medical mT5 outperforms both encoders and similarly sized text-to-text models for the Spanish, French, and Italian benchmarks, while being competitive with current state-of-the-art LLMs in English.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces Medical mT5, an open-source multilingual text-to-text large language model (LLM) designed for the medical domain.
- The model is trained on a large corpus of multilingual medical data from various sources, including scientific literature, clinical notes, and health-related websites.
- The goal of Medical mT5 is to provide a powerful and versatile language model that can be used for a wide range of medical NLP tasks, such as medical question answering, summarization, and generation.
Plain English Explanation
Medical mT5 is a powerful language model that has been specifically trained to understand and generate text related to the medical field. Unlike general-purpose language models, Medical mT5 has been exposed to a vast amount of medical data, allowing it to better comprehend and work with medical terminology, concepts, and tasks.
The model is "multilingual," meaning it can understand and generate text in multiple languages, including internal link German, internal link Spanish, and French, in addition to English. This makes it a versatile tool for healthcare professionals and researchers around the world.
By making Medical mT5 open-source, the researchers hope to encourage its widespread adoption and use in the medical community. Researchers and developers can build upon the model to create specialized applications, such as internal link clinical named entity recognition or internal link healthcare language model embedding spaces, further advancing the state of the art in medical natural language processing.
Technical Explanation
The researchers trained Medical mT5 using a large corpus of multilingual medical data, including scientific literature, clinical notes, and health-related websites. This data was carefully curated and preprocessed to ensure high quality and consistency.
The model architecture is based on the T5 (Text-to-Text Transfer Transformer) model, a state-of-the-art text-to-text transformer that has been widely used in natural language processing tasks. The researchers fine-tuned the T5 model on the medical dataset, allowing it to learn the nuances and complexities of medical language and tasks.
To evaluate the model's performance, the researchers conducted extensive experiments on a variety of medical NLP benchmarks, including internal link medical question answering and internal link healthcare language model embedding. The results show that Medical mT5 outperforms other state-of-the-art models, demonstrating its strong capabilities in the medical domain.
Critical Analysis
The researchers have made a significant contribution to the field of medical natural language processing by developing Medical mT5. The model's multilingual capabilities and its open-source nature are particularly noteworthy, as they will enable researchers and developers from around the world to leverage this powerful tool for a wide range of medical applications.
However, the paper does not address potential limitations or concerns with the model. For example, the researchers do not discuss the ethical implications of using such a powerful language model in the medical field, where the consequences of errors or biases can be severe. Additionally, the paper does not explore the potential challenges of deploying the model in real-world clinical settings, where data privacy and security may be critical considerations.
Further research is needed to investigate these and other areas of concern, such as the model's robustness to domain-specific terminology and jargon, its performance on specialized medical tasks, and its ability to handle rare or complex medical scenarios.
Conclusion
Medical mT5 is a groundbreaking open-source multilingual language model that has the potential to revolutionize the field of medical natural language processing. By leveraging a vast corpus of medical data and building upon the powerful T5 architecture, the researchers have created a highly capable model that can be used for a wide range of medical tasks, from question answering to text summarization.
The model's open-source nature and multilingual capabilities make it a valuable resource for healthcare professionals, researchers, and developers around the world. As the use of language models in the medical domain continues to grow, tools like Medical mT5 will become increasingly important in driving innovation and improving patient outcomes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Me LLaMA: Foundation Large Language Models for Medical Applications
Qianqian Xie, Qingyu Chen, Aokun Chen, Cheng Peng, Yan Hu, Fongci Lin, Xueqing Peng, Jimin Huang, Jeffrey Zhang, Vipina Keloth, Xinyu Zhou, Huan He, Lucila Ohno-Machado, Yonghui Wu, Hua Xu, Jiang Bian
0
0
Recent advancements in large language models (LLMs) such as ChatGPT and LLaMA have hinted at their potential to revolutionize medical applications, yet their application in clinical settings often reveals limitations due to a lack of specialized training on medical-specific data. In response to this challenge, this study introduces Me-LLaMA, a novel medical LLM family that includes foundation models - Me-LLaMA 13/70B, along with their chat-enhanced versions - Me-LLaMA 13/70B-chat, developed through continual pre-training and instruction tuning of LLaMA2 using large medical datasets. Our methodology leverages a comprehensive domain-specific data suite, including a large-scale, continual pre-training dataset with 129B tokens, an instruction tuning dataset with 214k samples, and a new medical evaluation benchmark (MIBE) across six critical medical tasks with 12 datasets. Our extensive evaluation using the MIBE shows that Me-LLaMA models achieve overall better performance than existing open-source medical LLMs in zero-shot, few-shot and supervised learning abilities. With task-specific instruction tuning, Me-LLaMA models outperform ChatGPT on 7 out of 8 datasets and GPT-4 on 5 out of 8 datasets. In addition, we investigated the catastrophic forgetting problem, and our results show that Me-LLaMA models outperform other open-source medical LLMs in mitigating this issue. Me-LLaMA is one of the largest open-source medical foundation LLMs that use both biomedical and clinical data. It exhibits superior performance across both general and medical tasks compared to other open-source medical LLMs, rendering it an attractive choice for medical AI applications. We release our models, datasets, and evaluation scripts at: https://github.com/BIDS-Xu-Lab/Me-LLaMA.
4/12/2024
💬
Evaluating large language models in medical applications: a survey
Xiaolan Chen, Jiayang Xiang, Shanfu Lu, Yexin Liu, Mingguang He, Danli Shi
0
0
Large language models (LLMs) have emerged as powerful tools with transformative potential across numerous domains, including healthcare and medicine. In the medical domain, LLMs hold promise for tasks ranging from clinical decision support to patient education. However, evaluating the performance of LLMs in medical contexts presents unique challenges due to the complex and critical nature of medical information. This paper provides a comprehensive overview of the landscape of medical LLM evaluation, synthesizing insights from existing studies and highlighting evaluation data sources, task scenarios, and evaluation methods. Additionally, it identifies key challenges and opportunities in medical LLM evaluation, emphasizing the need for continued research and innovation to ensure the responsible integration of LLMs into clinical practice.
5/14/2024
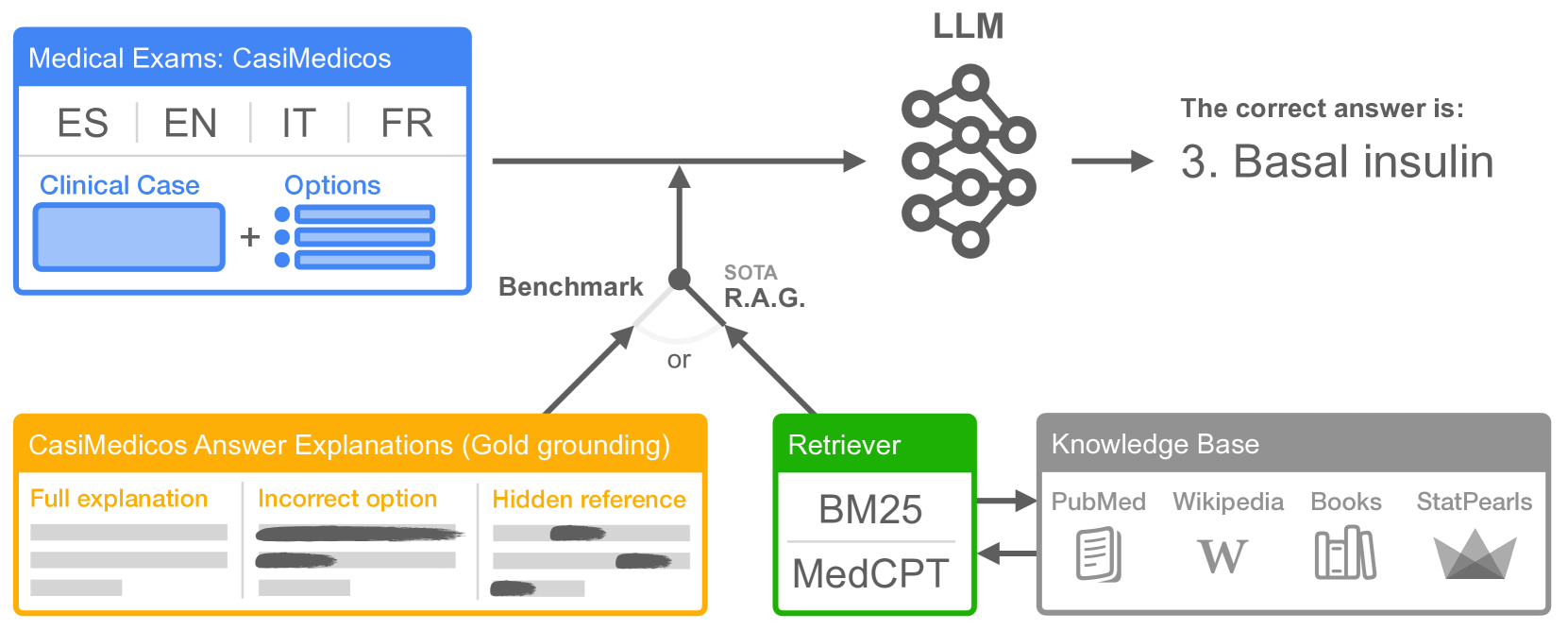
MedExpQA: Multilingual Benchmarking of Large Language Models for Medical Question Answering
I~nigo Alonso, Maite Oronoz, Rodrigo Agerri
0
0
Large Language Models (LLMs) have the potential of facilitating the development of Artificial Intelligence technology to assist medical experts for interactive decision support, which has been demonstrated by their competitive performances in Medical QA. However, while impressive, the required quality bar for medical applications remains far from being achieved. Currently, LLMs remain challenged by outdated knowledge and by their tendency to generate hallucinated content. Furthermore, most benchmarks to assess medical knowledge lack reference gold explanations which means that it is not possible to evaluate the reasoning of LLMs predictions. Finally, the situation is particularly grim if we consider benchmarking LLMs for languages other than English which remains, as far as we know, a totally neglected topic. In order to address these shortcomings, in this paper we present MedExpQA, the first multilingual benchmark based on medical exams to evaluate LLMs in Medical Question Answering. To the best of our knowledge, MedExpQA includes for the first time reference gold explanations written by medical doctors which can be leveraged to establish various gold-based upper-bounds for comparison with LLMs performance. Comprehensive multilingual experimentation using both the gold reference explanations and Retrieval Augmented Generation (RAG) approaches show that performance of LLMs still has large room for improvement, especially for languages other than English. Furthermore, and despite using state-of-the-art RAG methods, our results also demonstrate the difficulty of obtaining and integrating readily available medical knowledge that may positively impact results on downstream evaluations for Medical Question Answering. So far the benchmark is available in four languages, but we hope that this work may encourage further development to other languages.
4/9/2024
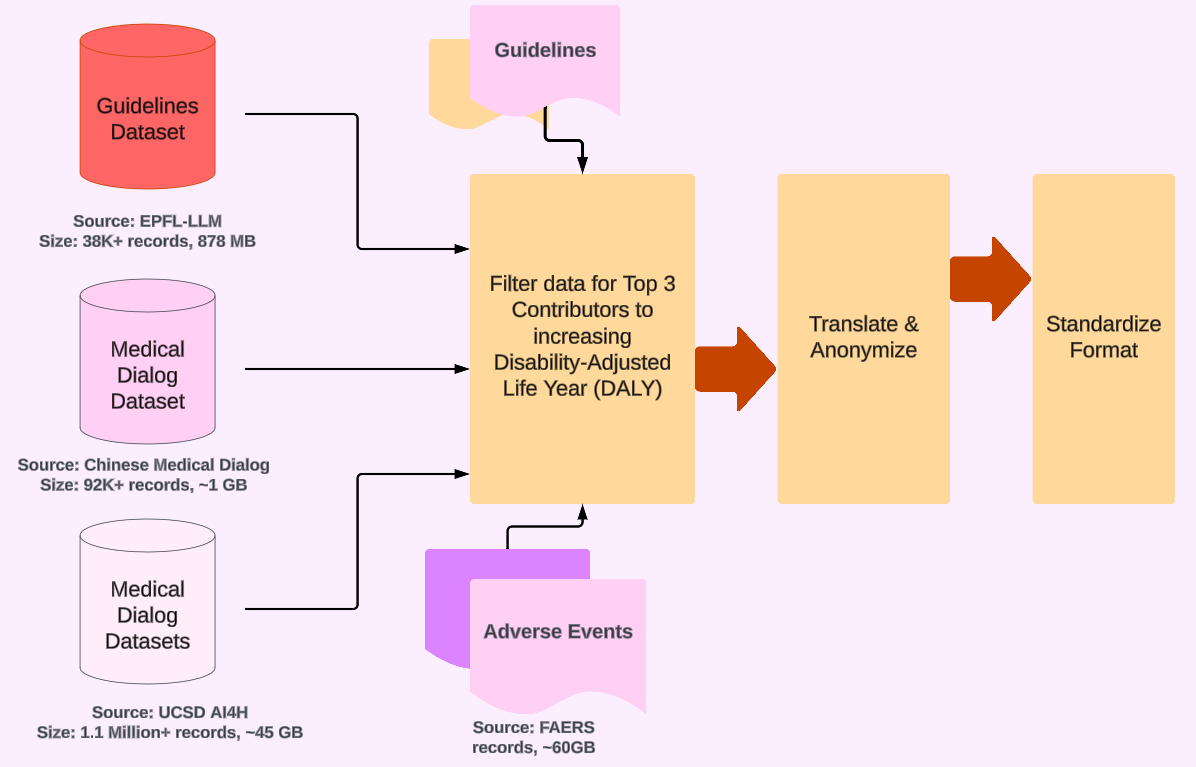
Introducing L2M3, A Multilingual Medical Large Language Model to Advance Health Equity in Low-Resource Regions
Agasthya Gangavarapu
0
0
Addressing the imminent shortfall of 10 million health workers by 2030, predominantly in Low- and Middle-Income Countries (LMICs), this paper introduces an innovative approach that harnesses the power of Large Language Models (LLMs) integrated with machine translation models. This solution is engineered to meet the unique needs of Community Health Workers (CHWs), overcoming language barriers, cultural sensitivities, and the limited availability of medical dialog datasets. I have crafted a model that not only boasts superior translation capabilities but also undergoes rigorous fine-tuning on open-source datasets to ensure medical accuracy and is equipped with comprehensive safety features to counteract the risks of misinformation. Featuring a modular design, this approach is specifically structured for swift adaptation across various linguistic and cultural contexts, utilizing open-source components to significantly reduce healthcare operational costs. This strategic innovation markedly improves the accessibility and quality of healthcare services by providing CHWs with contextually appropriate medical knowledge and diagnostic tools. This paper highlights the transformative impact of this context-aware LLM, underscoring its crucial role in addressing the global healthcare workforce deficit and propelling forward healthcare outcomes in LMICs.
4/16/2024