Aqulia-Med LLM: Pioneering Full-Process Open-Source Medical Language Models
2406.12182
0
0
Abstract
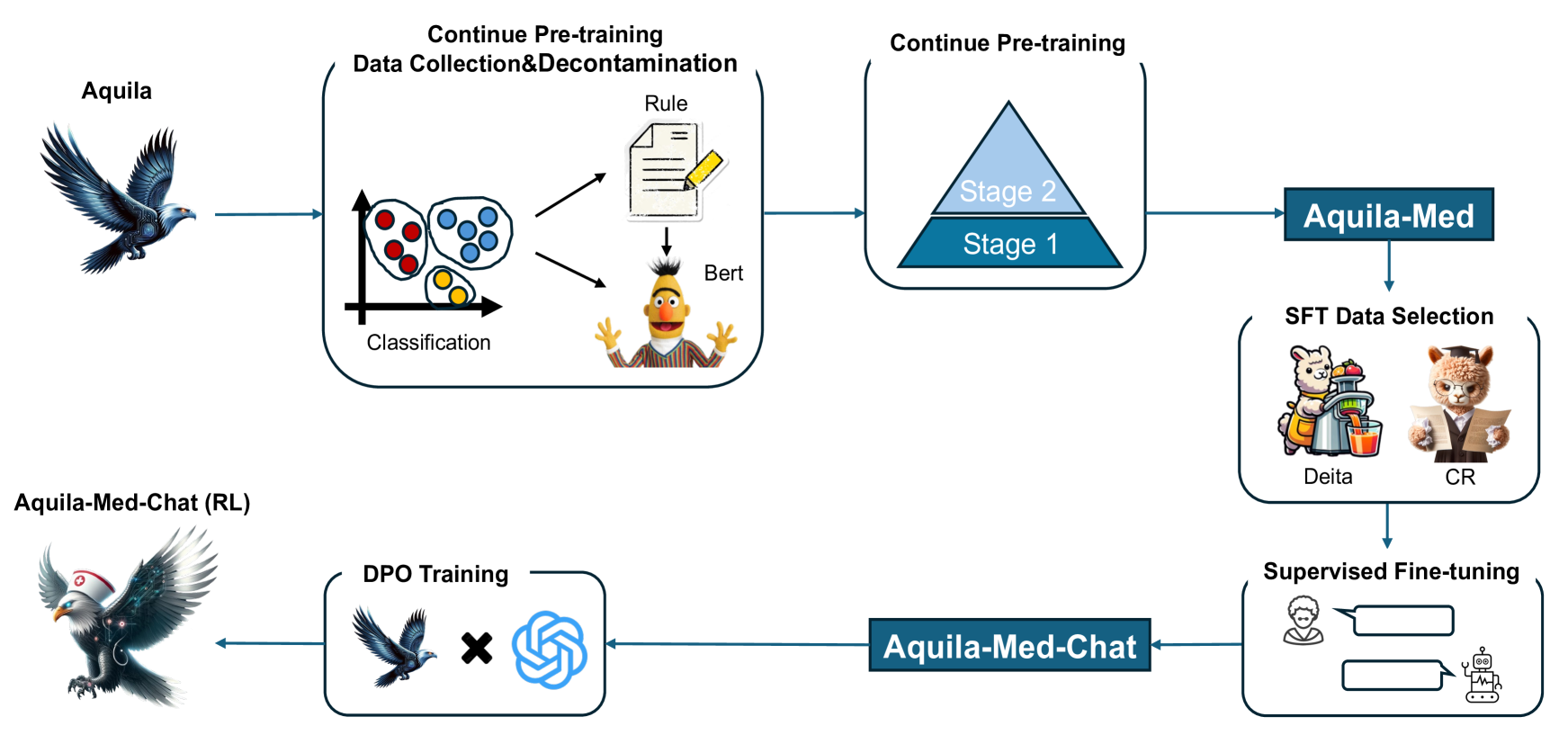
Recently, both closed-source LLMs and open-source communities have made significant strides, outperforming humans in various general domains. However, their performance in specific professional fields such as medicine, especially within the open-source community, remains suboptimal due to the complexity of medical knowledge. We propose Aquila-Med, a bilingual medical LLM based on Aquila, addressing these challenges through continue pre-training, supervised fine-tuning (SFT), and reinforcement learning from human feedback (RLHF). We construct a large-scale Chinese and English medical dataset for continue pre-training and a high-quality SFT dataset, covering extensive medical specialties. Additionally, we develop a high-quality Direct Preference Optimization (DPO) dataset for further alignment. Aquila-Med achieves notable results across single-turn, multi-turn dialogues, and medical multiple-choice questions, demonstrating the effectiveness of our approach. We open-source the datasets and the entire training process, contributing valuable resources to the research community. Our models and datasets will released at https://huggingface.co/BAAI/AquilaMed-RL.
Create account to get full access
Overview
• The paper presents Aqulia-Med, an open-source, full-process medical language model that aims to advance the state-of-the-art in medical natural language processing.
• Aqulia-Med is designed to handle a wide range of medical tasks, from clinical documentation to drug discovery, by leveraging large language models trained on extensive medical data.
• The research highlights the importance of open-source, accessible medical AI models to drive innovation and improve healthcare outcomes.
Plain English Explanation
Aqulia-Med is a new type of language model, which is a computer program that can understand and generate human-like text. This model is specifically designed to work with medical information, such as patient records, research papers, and drug data.
The key idea behind Aqulia-Med is to create an open-source, or freely available, system that can be used by researchers, doctors, and others to develop new medical applications. This is important because it allows more people to access and build upon the latest advancements in medical AI, rather than having these tools be controlled by a few large companies.
By training Aqulia-Med on a vast amount of medical data, the researchers have created a model that can perform a wide variety of tasks, from summarizing patient notes to assisting in drug discovery. This means that Aqulia-Med could potentially be used to streamline medical workflows, speed up research, and ultimately improve patient care.
The researchers emphasize the value of open-source models like Aqulia-Med, as they believe this approach will foster more collaboration and innovation in the field of medical AI. They hope that by making their work freely available, other researchers and developers will be able to build upon it and create even more powerful tools to support the healthcare industry.
Technical Explanation
The paper describes the development of Aqulia-Med, an open-source, full-process medical language model that can perform a wide range of tasks in the healthcare domain. The researchers trained Aqulia-Med on a large, curated dataset of medical literature, including scientific papers, clinical notes, and drug information, to enable it to understand and generate human-like text related to medicine.
The model's architecture is based on the Transformer language model, a powerful deep learning approach that has shown great success in natural language processing. The researchers fine-tuned the Transformer model on their medical dataset, allowing Aqulia-Med to capture the nuances and specialized vocabulary of the healthcare field.
To demonstrate the capabilities of Aqulia-Med, the paper presents experiments on various medical tasks, such as medical machine translation, cost-effective model adaptation, and clinical summarization. The results show that Aqulia-Med outperforms existing medical language models, highlighting its potential to drive innovation in the healthcare sector.
Critical Analysis
The paper makes a strong case for the importance of open-source, full-process medical language models like Aqulia-Med. By making the model and its training data freely available, the researchers aim to democratize access to cutting-edge medical AI and encourage more researchers and developers to contribute to the field.
However, the paper does not address potential concerns around data privacy and the ethical use of medical AI. While open-source models can promote innovation, there must be robust safeguards in place to protect patient information and ensure the responsible deployment of these technologies.
Additionally, the paper does not provide a detailed analysis of the limitations of Aqulia-Med or areas for further research. As with any large language model, there may be biases or gaps in the model's knowledge that could impact its performance on certain medical tasks. Further research is needed to fully understand the strengths and weaknesses of Aqulia-Med.
Despite these caveats, the paper represents an important step forward in the development of large language models for medical applications. The researchers' commitment to open-source development and their focus on a wide range of medical tasks make Aqulia-Med a promising tool for advancing the state of the art in medical natural language processing.
Conclusion
The Aqulia-Med paper introduces an open-source, full-process medical language model that aims to drive innovation and improve healthcare outcomes. By making the model and its training data freely available, the researchers hope to democratize access to cutting-edge medical AI and encourage more collaboration in the field.
The technical details of Aqulia-Med's architecture and its performance on various medical tasks showcase the model's potential to streamline clinical workflows, accelerate research, and enhance patient care. However, the paper also highlights the need for continued research to address potential concerns around data privacy and the ethical use of medical AI.
Overall, the Aqulia-Med project represents an important step forward in the development of large language models for healthcare applications. By embracing an open-source approach, the researchers are paving the way for a more collaborative and accessible future in medical natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Towards Building Multilingual Language Model for Medicine
Pengcheng Qiu, Chaoyi Wu, Xiaoman Zhang, Weixiong Lin, Haicheng Wang, Ya Zhang, Yanfeng Wang, Weidi Xie
0
0
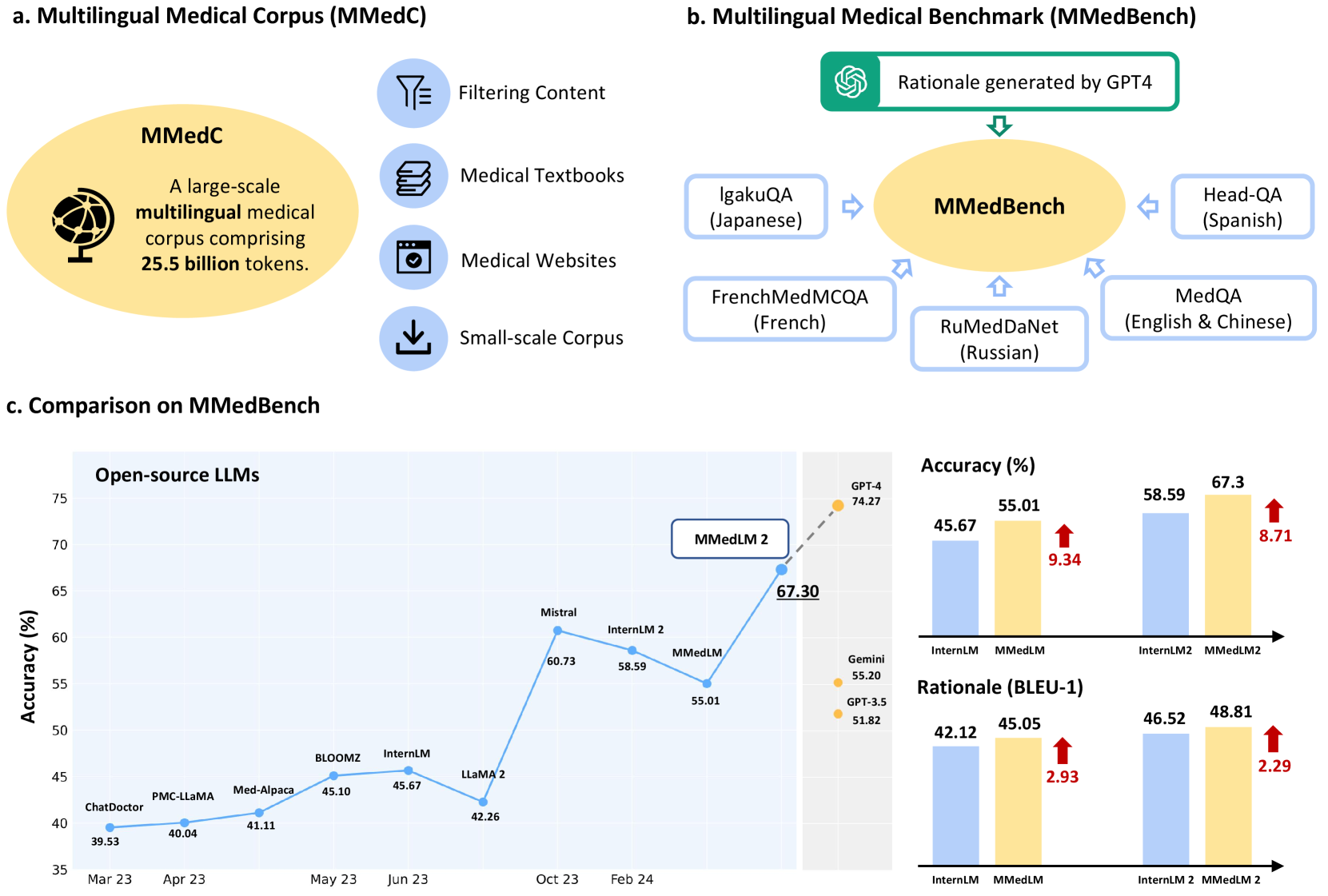
The development of open-source, multilingual medical language models can benefit a wide, linguistically diverse audience from different regions. To promote this domain, we present contributions from the following: First, we construct a multilingual medical corpus, containing approximately 25.5B tokens encompassing 6 main languages, termed as MMedC, enabling auto-regressive domain adaptation for general LLMs; Second, to monitor the development of multilingual medical LLMs, we propose a multilingual medical multi-choice question-answering benchmark with rationale, termed as MMedBench; Third, we have assessed a number of open-source large language models (LLMs) on our benchmark, along with those further auto-regressive trained on MMedC. Our final model, MMed-Llama 3, with only 8B parameters, achieves superior performance compared to all other open-source models on both MMedBench and English benchmarks, even rivaling GPT-4. In conclusion, in this work, we present a large-scale corpus, a benchmark and a series of models to support the development of multilingual medical LLMs.
6/4/2024

New!Apollo: A Lightweight Multilingual Medical LLM towards Democratizing Medical AI to 6B People
Xidong Wang, Nuo Chen, Junyin Chen, Yan Hu, Yidong Wang, Xiangbo Wu, Anningzhe Gao, Xiang Wan, Haizhou Li, Benyou Wang
0
0
Despite the vast repository of global medical knowledge predominantly being in English, local languages are crucial for delivering tailored healthcare services, particularly in areas with limited medical resources. To extend the reach of medical AI advancements to a broader population, we aim to develop medical LLMs across the six most widely spoken languages, encompassing a global population of 6.1 billion. This effort culminates in the creation of the ApolloCorpora multilingual medical dataset and the XMedBench benchmark. In the multilingual medical benchmark, the released Apollo models, at various relatively-small sizes (i.e., 0.5B, 1.8B, 2B, 6B, and 7B), achieve the best performance among models of equivalent size. Especially, Apollo-7B is the state-of-the-art multilingual medical LLMs up to 70B. Additionally, these lite models could be used to improve the multi-lingual medical capabilities of larger models without fine-tuning in a proxy-tuning fashion. We will open-source training corpora, code, model weights and evaluation benchmark.
7/1/2024
Medical mT5: An Open-Source Multilingual Text-to-Text LLM for The Medical Domain
Iker Garc'ia-Ferrero, Rodrigo Agerri, Aitziber Atutxa Salazar, Elena Cabrio, Iker de la Iglesia, Alberto Lavelli, Bernardo Magnini, Benjamin Molinet, Johana Ramirez-Romero, German Rigau, Jose Maria Villa-Gonzalez, Serena Villata, Andrea Zaninello
0
0
Research on language technology for the development of medical applications is currently a hot topic in Natural Language Understanding and Generation. Thus, a number of large language models (LLMs) have recently been adapted to the medical domain, so that they can be used as a tool for mediating in human-AI interaction. While these LLMs display competitive performance on automated medical texts benchmarks, they have been pre-trained and evaluated with a focus on a single language (English mostly). This is particularly true of text-to-text models, which typically require large amounts of domain-specific pre-training data, often not easily accessible for many languages. In this paper, we address these shortcomings by compiling, to the best of our knowledge, the largest multilingual corpus for the medical domain in four languages, namely English, French, Italian and Spanish. This new corpus has been used to train Medical mT5, the first open-source text-to-text multilingual model for the medical domain. Additionally, we present two new evaluation benchmarks for all four languages with the aim of facilitating multilingual research in this domain. A comprehensive evaluation shows that Medical mT5 outperforms both encoders and similarly sized text-to-text models for the Spanish, French, and Italian benchmarks, while being competitive with current state-of-the-art LLMs in English.
4/12/2024
Towards Adapting Open-Source Large Language Models for Expert-Level Clinical Note Generation
Hanyin Wang, Chufan Gao, Bolun Liu, Qiping Xu, Guleid Hussein, Mohamad El Labban, Kingsley Iheasirim, Hariprasad Korsapati, Chuck Outcalt, Jimeng Sun
0
0
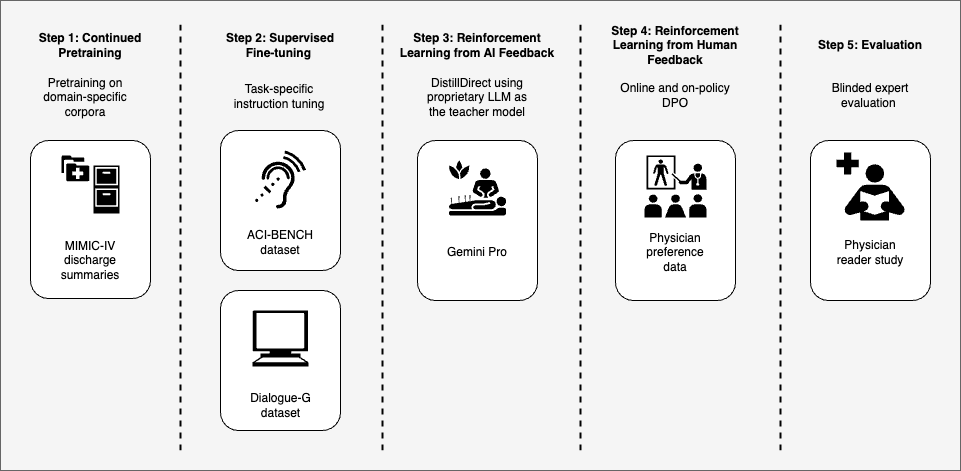
Proprietary Large Language Models (LLMs) such as GPT-4 and Gemini have demonstrated promising capabilities in clinical text summarization tasks. However, due to patient data privacy concerns and computational costs, many healthcare providers prefer using small, locally-hosted models over external generic LLMs. This study presents a comprehensive domain- and task-specific adaptation process for the open-source LLaMA-2 13 billion parameter model, enabling it to generate high-quality clinical notes from outpatient patient-doctor dialogues. Our process incorporates continued pre-training, supervised fine-tuning, and reinforcement learning from both AI and human feedback. We introduced a new approach, DistillDirect, for performing on-policy reinforcement learning with Gemini 1.0 Pro as the teacher model. Our resulting model, LLaMA-Clinic, can generate clinical notes comparable in quality to those authored by physicians. In a blinded physician reader study, the majority (90.4%) of individual evaluations rated the notes generated by LLaMA-Clinic as acceptable or higher across all three criteria: real-world readiness, completeness, and accuracy. In the more challenging Assessment and Plan section, LLaMA-Clinic scored higher (4.2/5) in real-world readiness than physician-authored notes (4.1/5). Our cost analysis for inference shows that our LLaMA-Clinic model achieves a 3.75-fold cost reduction compared to an external generic LLM service. Additionally, we highlight key considerations for future clinical note-generation tasks, emphasizing the importance of pre-defining a best-practice note format, rather than relying on LLMs to determine this for clinical practice. We have made our newly created synthetic clinic dialogue-note dataset and the physician feedback dataset publicly available to foster future research.
6/11/2024