Appearance-Based Refinement for Object-Centric Motion Segmentation

0

Sign in to get full access
Overview
- This blog post provides a plain English summary and technical explanation of the research paper "Appearance-based Refinement for Object-Centric Motion Segmentation".
- The paper introduces a new approach for segmenting and tracking moving objects in videos using appearance-based refinement.
- The key ideas and insights from the paper are discussed, as well as potential caveats, limitations, and areas for further research.
Plain English Explanation
The research paper focuses on the problem of motion segmentation, which is the task of identifying and isolating the moving objects in a video. This is an important task for applications like autonomous driving, video surveillance, and augmented reality.
The researchers propose a new approach that combines object detection and motion segmentation to improve the accuracy of identifying and tracking moving objects. The key idea is to use the visual appearance of the objects, in addition to their motion, to refine the segmentation and ensure that the boundaries of the moving objects are accurately captured.
The appearance-based mask selector component of the system uses a neural network to identify the visual features of the objects and select the appropriate segmentation masks. The appearance-based mask corrector then refines the masks to improve the accuracy of the object boundaries.
By incorporating appearance information in addition to motion cues, the researchers demonstrate that their approach can achieve state-of-the-art performance on several benchmark datasets for motion segmentation. This suggests that the combination of object detection and motion segmentation can be a powerful tool for a variety of computer vision applications.
Technical Explanation
The paper presents a novel approach for object-centric motion segmentation that leverages both motion cues and appearance information. The key components of the system are:
-
Motion segmentation: The initial motion segmentation is performed using a state-of-the-art motion segmentation algorithm, which identifies the moving objects in the video based on their motion patterns.
-
Appearance-based mask selector: A neural network is used to analyze the visual appearance of the objects and select the appropriate segmentation masks. This component helps to refine the initial motion segmentation by incorporating appearance information.
-
Appearance-based mask corrector: The selected masks are further refined by the appearance-based mask corrector, which adjusts the object boundaries to better match the visual features of the objects.
The researchers evaluate their approach on several benchmark datasets for motion segmentation and demonstrate that it outperforms state-of-the-art methods. The incorporation of appearance information is shown to be a key factor in improving the accuracy of the object segmentation and tracking.
Critical Analysis
The paper presents a compelling approach to motion segmentation that leverages both motion cues and appearance information. However, there are a few potential limitations and areas for further research:
-
Computational complexity: The use of neural networks for the appearance-based components may introduce additional computational overhead, which could be a concern for real-time applications.
-
Generalization to diverse datasets: The evaluation is limited to a few benchmark datasets, and it's unclear how the approach would perform on more diverse or challenging video datasets.
-
Robustness to occlusions: The paper does not explicitly address the challenge of handling occlusions, which can be a common issue in real-world video footage.
-
Comparison to other motion-appearance approaches: While the paper demonstrates state-of-the-art performance, it would be interesting to see a more detailed comparison to other methods that also combine motion and appearance information for motion segmentation.
Overall, the research represents a valuable contribution to the field of computer vision and motion analysis, and the proposed approach shows promise for a wide range of applications. Further research and development in this area could lead to even more robust and accurate motion segmentation systems.
Conclusion
The "Appearance-based Refinement for Object-Centric Motion Segmentation" paper presents a novel approach to motion segmentation that combines motion cues and appearance information to improve the accuracy of object detection and tracking. By incorporating visual features in addition to motion patterns, the researchers demonstrate that their method can outperform state-of-the-art motion segmentation algorithms on several benchmark datasets.
This research highlights the potential benefits of integrating multiple modalities, such as motion and appearance, for computer vision tasks. The proposed approach could have significant implications for a variety of applications, including autonomous driving, video surveillance, and augmented reality, where the ability to accurately segment and track moving objects is crucial. Further development and refinement of this technique could lead to even more robust and versatile motion segmentation systems in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Appearance-Based Refinement for Object-Centric Motion Segmentation
Junyu Xie, Weidi Xie, Andrew Zisserman
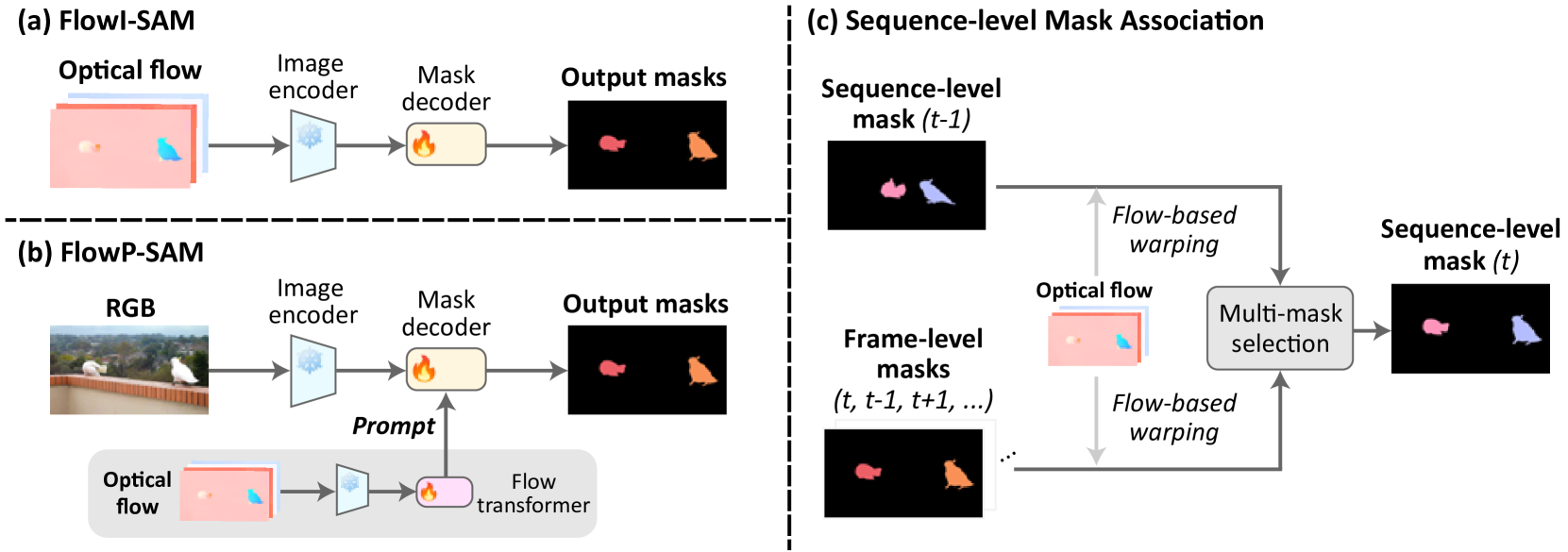
The goal of this paper is to discover, segment, and track independently moving objects in complex visual scenes. Previous approaches have explored the use of optical flow for motion segmentation, leading to imperfect predictions due to partial motion, background distraction, and object articulations and interactions. To address this issue, we introduce an appearance-based refinement method that leverages temporal consistency in video streams to correct inaccurate flow-based proposals. Our approach involves a sequence-level selection mechanism that identifies accurate flow-predicted masks as exemplars, and an object-centric architecture that refines problematic masks based on exemplar information. The model is pre-trained on synthetic data and then adapted to real-world videos in a self-supervised manner, eliminating the need for human annotations. Its performance is evaluated on multiple video segmentation benchmarks, including DAVIS, YouTubeVOS, SegTrackv2, and FBMS-59. We achieve competitive performance on single-object segmentation, while significantly outperforming existing models on the more challenging problem of multi-object segmentation. Finally, we investigate the benefits of using our model as a prompt for the per-frame Segment Anything Model.
Read more8/20/2024
0
Moving Object Segmentation: All You Need Is SAM (and Flow)
Junyu Xie, Charig Yang, Weidi Xie, Andrew Zisserman
The objective of this paper is motion segmentation -- discovering and segmenting the moving objects in a video. This is a much studied area with numerous careful,and sometimes complex, approaches and training schemes including: self-supervised learning, learning from synthetic datasets, object-centric representations, amodal representations, and many more. Our interest in this paper is to determine if the Segment Anything model (SAM) can contribute to this task. We investigate two models for combining SAM with optical flow that harness the segmentation power of SAM with the ability of flow to discover and group moving objects. In the first model, we adapt SAM to take optical flow, rather than RGB, as an input. In the second, SAM takes RGB as an input, and flow is used as a segmentation prompt. These surprisingly simple methods, without any further modifications, outperform all previous approaches by a considerable margin in both single and multi-object benchmarks. We also extend these frame-level segmentations to sequence-level segmentations that maintain object identity. Again, this simple model outperforms previous methods on multiple video object segmentation benchmarks.
Read more4/19/2024

0
Dense Monocular Motion Segmentation Using Optical Flow and Pseudo Depth Map: A Zero-Shot Approach
Yuxiang Huang, Yuhao Chen, John Zelek
Motion segmentation from a single moving camera presents a significant challenge in the field of computer vision. This challenge is compounded by the unknown camera movements and the lack of depth information of the scene. While deep learning has shown impressive capabilities in addressing these issues, supervised models require extensive training on massive annotated datasets, and unsupervised models also require training on large volumes of unannotated data, presenting significant barriers for both. In contrast, traditional methods based on optical flow do not require training data, however, they often fail to capture object-level information, leading to over-segmentation or under-segmentation. In addition, they also struggle in complex scenes with substantial depth variations and non-rigid motion, due to the overreliance of optical flow. To overcome these challenges, we propose an innovative hybrid approach that leverages the advantages of both deep learning methods and traditional optical flow based methods to perform dense motion segmentation without requiring any training. Our method initiates by automatically generating object proposals for each frame using foundation models. These proposals are then clustered into distinct motion groups using both optical flow and relative depth maps as motion cues. The integration of depth maps derived from state-of-the-art monocular depth estimation models significantly enhances the motion cues provided by optical flow, particularly in handling motion parallax issues. Our method is evaluated on the DAVIS-Moving and YTVOS-Moving datasets, and the results demonstrate that our method outperforms the best unsupervised method and closely matches with the state-of-theart supervised methods.
Read more6/28/2024

0
Learning Spatial-Semantic Features for Robust Video Object Segmentation
Xin Li, Deshui Miao, Zhenyu He, Yaowei Wang, Huchuan Lu, Ming-Hsuan Yang
Tracking and segmenting multiple similar objects with complex or separate parts in long-term videos is inherently challenging due to the ambiguity of target parts and identity confusion caused by occlusion, background clutter, and long-term variations. In this paper, we propose a robust video object segmentation framework equipped with spatial-semantic features and discriminative object queries to address the above issues. Specifically, we construct a spatial-semantic network comprising a semantic embedding block and spatial dependencies modeling block to associate the pretrained ViT features with global semantic features and local spatial features, providing a comprehensive target representation. In addition, we develop a masked cross-attention module to generate object queries that focus on the most discriminative parts of target objects during query propagation, alleviating noise accumulation and ensuring effective long-term query propagation. The experimental results show that the proposed method set a new state-of-the-art performance on multiple datasets, including the DAVIS2017 test (89.1%), YoutubeVOS 2019 (88.5%), MOSE (75.1%), LVOS test (73.0%), and LVOS val (75.1%), which demonstrate the effectiveness and generalization capacity of the proposed method. We will make all source code and trained models publicly available.
Read more7/11/2024