Moving Object Segmentation: All You Need Is SAM (and Flow)

0
Sign in to get full access
Overview
- This paper proposes a new approach for moving object segmentation that combines the Segment Anything Model (SAM) and optical flow.
- The key idea is to use SAM, a powerful general-purpose segmentation model, to segment moving objects in video frames, and then refine the segmentation using optical flow information.
- The authors demonstrate that this simple yet effective approach outperforms state-of-the-art methods on several benchmark datasets for moving object segmentation.
Plain English Explanation
The paper discusses a new way to identify and isolate moving objects in video. The main technique is to use a model called the Segment Anything Model (SAM) to first roughly segment the moving objects in each video frame. Then, the authors refine these segmentations using information about the movement or "flow" of objects between frames.
The key insight is that SAM, a powerful general-purpose segmentation model, can be leveraged to do the initial detection of moving objects, even though it was not specifically designed for this task. Then, by incorporating the additional cue of optical flow, the segmentations can be improved and make the final results more accurate.
This combination of SAM and flow information is shown to outperform other state-of-the-art methods for moving object segmentation on standard benchmark datasets. The authors demonstrate that their simple yet effective approach can effectively isolate moving objects in video, which has many practical applications like video understanding, robotics, and augmented reality.
Technical Explanation
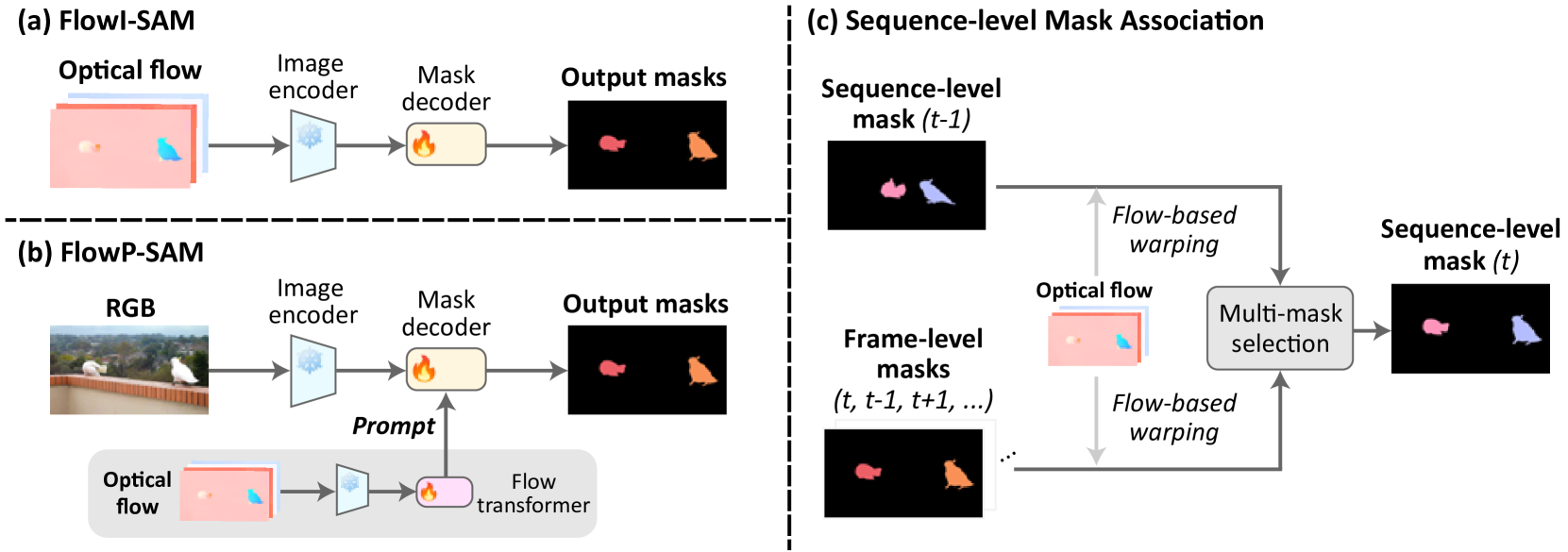
The paper proposes a two-stage approach for moving object segmentation that combines the Segment Anything Model (SAM) and optical flow information.
In the first stage, the authors leverage the power of SAM, a large language model-based segmentation model, to obtain initial segmentations of moving objects in each video frame. SAM is a general-purpose segmentation model that can be applied to a wide variety of scenes and objects, without requiring any prior training on moving objects specifically.
In the second stage, the authors refine the SAM-based segmentations by incorporating information about the movement or "flow" of objects between video frames. Optical flow algorithms are used to estimate the motion of pixels, and this flow information is then used to improve the segmentation boundaries and remove any static background regions that were initially included.
The authors evaluate their approach, which they call "SAM+Flow", on several benchmark datasets for moving object segmentation. They show that this simple two-stage method outperforms more complex state-of-the-art approaches, including those that use additional modalities like depth or saliency.
The authors attribute the success of their method to the complementary strengths of SAM and optical flow. SAM provides a robust initial segmentation, while the flow information helps refine the boundaries and remove irrelevant static regions. The authors also note that their approach is computationally efficient and can be easily integrated into real-world video processing pipelines.
Critical Analysis
The paper presents a compelling approach for moving object segmentation that leverages the power of the Segment Anything Model (SAM) in a novel way. One key strength of the work is its simplicity - the authors demonstrate that a straightforward two-stage process of SAM-based segmentation followed by flow-based refinement can outperform more complex state-of-the-art methods.
However, the paper does not address some potential limitations of the approach. For example, the authors do not discuss how well the method would perform on scenes with significant camera motion or occlusions, which can be challenging for optical flow algorithms. Additionally, the paper does not explore the robustness of the approach to variations in video quality, frame rate, or other factors that may be encountered in real-world applications.
Furthermore, the authors do not provide a detailed analysis of the failure cases or discuss potential avenues for further improvement. It would be interesting to see how the method could be extended, for example, by incorporating additional cues beyond just optical flow, or by adapting the Segment Anything Model (SAM) to the task more directly.
Overall, the paper presents a promising and practical approach for moving object segmentation, but there is likely room for further refinement and exploration to address some of the potential limitations and expand the capabilities of the method.
Conclusion
In this paper, the authors introduce a new approach for moving object segmentation that combines the power of the Segment Anything Model (SAM) with optical flow information. By leveraging SAM's robust initial segmentation and then refining the results using flow-based cues, the authors demonstrate a simple yet effective method that outperforms more complex state-of-the-art techniques.
The key significance of this work is that it shows how general-purpose segmentation models like SAM can be adapted and applied to more specialized tasks, such as isolating moving objects in video. This has important implications for the development of versatile visual foundation models that can be easily repurposed for a wide range of computer vision applications.
Moreover, the authors' approach is computationally efficient and can be readily integrated into real-world video processing pipelines, making it a practical solution for tasks like video understanding, robotics, and augmented reality. While the method has some potential limitations, the paper serves as an inspiring example of how innovative combinations of existing techniques can lead to robust and impactful solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Moving Object Segmentation: All You Need Is SAM (and Flow)
Junyu Xie, Charig Yang, Weidi Xie, Andrew Zisserman
The objective of this paper is motion segmentation -- discovering and segmenting the moving objects in a video. This is a much studied area with numerous careful,and sometimes complex, approaches and training schemes including: self-supervised learning, learning from synthetic datasets, object-centric representations, amodal representations, and many more. Our interest in this paper is to determine if the Segment Anything model (SAM) can contribute to this task. We investigate two models for combining SAM with optical flow that harness the segmentation power of SAM with the ability of flow to discover and group moving objects. In the first model, we adapt SAM to take optical flow, rather than RGB, as an input. In the second, SAM takes RGB as an input, and flow is used as a segmentation prompt. These surprisingly simple methods, without any further modifications, outperform all previous approaches by a considerable margin in both single and multi-object benchmarks. We also extend these frame-level segmentations to sequence-level segmentations that maintain object identity. Again, this simple model outperforms previous methods on multiple video object segmentation benchmarks.
Read more4/19/2024
🤷
0
UnSAMFlow: Unsupervised Optical Flow Guided by Segment Anything Model
Shuai Yuan, Lei Luo, Zhuo Hui, Can Pu, Xiaoyu Xiang, Rakesh Ranjan, Denis Demandolx
Traditional unsupervised optical flow methods are vulnerable to occlusions and motion boundaries due to lack of object-level information. Therefore, we propose UnSAMFlow, an unsupervised flow network that also leverages object information from the latest foundation model Segment Anything Model (SAM). We first include a self-supervised semantic augmentation module tailored to SAM masks. We also analyze the poor gradient landscapes of traditional smoothness losses and propose a new smoothness definition based on homography instead. A simple yet effective mask feature module has also been added to further aggregate features on the object level. With all these adaptations, our method produces clear optical flow estimation with sharp boundaries around objects, which outperforms state-of-the-art methods on both KITTI and Sintel datasets. Our method also generalizes well across domains and runs very efficiently.
Read more5/7/2024

0
Video Object Segmentation via SAM 2: The 4th Solution for LSVOS Challenge VOS Track
Feiyu Pan, Hao Fang, Runmin Cong, Wei Zhang, Xiankai Lu
Video Object Segmentation (VOS) task aims to segmenting a particular object instance throughout the entire video sequence given only the object mask of the first frame. Recently, Segment Anything Model 2 (SAM 2) is proposed, which is a foundation model towards solving promptable visual segmentation in images and videos. SAM 2 builds a data engine, which improves model and data via user interaction, to collect the largest video segmentation dataset to date. SAM 2 is a simple transformer architecture with streaming memory for real-time video processing, which trained on the date provides strong performance across a wide range of tasks. In this work, we evaluate the zero-shot performance of SAM 2 on the more challenging VOS datasets MOSE and LVOS. Without fine-tuning on the training set, SAM 2 achieved 75.79 J&F on the test set and ranked 4th place for 6th LSVOS Challenge VOS Track.
Read more8/27/2024

0
Evaluating SAM2's Role in Camouflaged Object Detection: From SAM to SAM2
Lv Tang, Bo Li
The Segment Anything Model (SAM), introduced by Meta AI Research as a generic object segmentation model, quickly garnered widespread attention and significantly influenced the academic community. To extend its application to video, Meta further develops Segment Anything Model 2 (SAM2), a unified model capable of both video and image segmentation. SAM2 shows notable improvements over its predecessor in terms of applicable domains, promptable segmentation accuracy, and running speed. However, this report reveals a decline in SAM2's ability to perceive different objects in images without prompts in its auto mode, compared to SAM. Specifically, we employ the challenging task of camouflaged object detection to assess this performance decrease, hoping to inspire further exploration of the SAM model family by researchers. The results of this paper are provided in url{https://github.com/luckybird1994/SAMCOD}.
Read more8/1/2024