Applicability of Large Language Models and Generative Models for Legal Case Judgement Summarization

0
💬
Sign in to get full access
Overview
- The paper explores the applicability of large language models and generative models for summarizing legal case judgments.
- It evaluates the performance of different models, including leveraging-large-language-models-relevance-judgments-legal, large-language-models-judicial-entity-extraction-comparative, and lamsum-novel-framework-extractive-summarization-user-generated, on the task of legal case judgment summarization.
- The research also examines the potential of topic-modelling-case-law-using-large-language and can-large-language-model-summarizers-adapt-to in this domain.
Plain English Explanation
The paper looks at how well large language models and generative models can summarize legal case judgments. These are advanced AI systems that can understand and generate human-like text. The researchers tested different models to see how accurately they could summarize the key points from legal case decisions.
The goal was to see if these powerful AI models could be useful for quickly summarizing long and complex legal documents, which is an important task for lawyers and judges. The researchers evaluated the performance of several prominent models, including some that specialize in legal tasks like leveraging-large-language-models-relevance-judgments-legal and large-language-models-judicial-entity-extraction-comparative.
They also looked at more general summarization models like lamsum-novel-framework-extractive-summarization-user-generated to see how they might work for legal texts. Additionally, the research explored using large language models for topic-modelling-case-law-using-large-language and whether summarizers could can-large-language-model-summarizers-adapt-to the legal domain.
Technical Explanation
The paper evaluates the performance of various large language models and generative models on the task of legal case judgment summarization. The researchers tested models like leveraging-large-language-models-relevance-judgments-legal, which specializes in legal relevance judgments, and large-language-models-judicial-entity-extraction-comparative, which focuses on extracting legal entities.
They also examined more general summarization models such as lamsum-novel-framework-extractive-summarization-user-generated to see how they might perform on legal texts. The research further explored using large language models for topic-modelling-case-law-using-large-language and whether summarizers could can-large-language-model-summarizers-adapt-to the legal domain.
The experiments involved training and evaluating the models on a dataset of legal case judgments, measuring their performance on metrics such as summary quality, relevance, and faithfulness to the original text. The results provide insights into the strengths and limitations of these approaches for legal case summarization.
Critical Analysis
The paper acknowledges some limitations in the research, such as the need for larger and more diverse legal datasets to fully assess the models' performance. It also highlights the potential challenges in adapting general-purpose summarization models to the specialized language and structure of legal texts.
While the researchers demonstrate the potential of large language models and generative models in this domain, further investigation is needed to fully understand their suitability and any biases they may introduce. Careful evaluation of the models' outputs, particularly regarding fairness and unintended consequences, would be an important next step.
Additionally, the paper does not explore the interpretability and explainability of the models' decision-making processes, which could be crucial for building trust and acceptance in the legal community. Incorporating human evaluation and feedback loops into the model development process may help address these concerns.
Conclusion
This research explores the applicability of large language models and generative models for summarizing legal case judgments, a crucial task in the legal field. The findings suggest these advanced AI systems have promising capabilities, but also highlight the need for further investigation and refinement to ensure their reliable and ethical use in the legal domain.
The insights provided by this paper contribute to the ongoing efforts to leverage the power of AI technologies to enhance legal analysis and decision-making, while also underscoring the importance of carefully considering the limitations and potential biases of these models. As the legal field continues to explore the integration of AI, this research serves as a valuable stepping stone towards more effective and trustworthy case judgment summarization tools.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Applicability of Large Language Models and Generative Models for Legal Case Judgement Summarization
Aniket Deroy, Kripabandhu Ghosh, Saptarshi Ghosh
Automatic summarization of legal case judgements, which are known to be long and complex, has traditionally been tried via extractive summarization models. In recent years, generative models including abstractive summarization models and Large language models (LLMs) have gained huge popularity. In this paper, we explore the applicability of such models for legal case judgement summarization. We applied various domain specific abstractive summarization models and general domain LLMs as well as extractive summarization models over two sets of legal case judgements from the United Kingdom (UK) Supreme Court and the Indian (IN) Supreme Court and evaluated the quality of the generated summaries. We also perform experiments on a third dataset of legal documents of a different type, Government reports from the United States (US). Results show that abstractive summarization models and LLMs generally perform better than the extractive methods as per traditional metrics for evaluating summary quality. However, detailed investigation shows the presence of inconsistencies and hallucinations in the outputs of the generative models, and we explore ways to reduce the hallucinations and inconsistencies in the summaries. Overall, the investigation suggests that further improvements are needed to enhance the reliability of abstractive models and LLMs for legal case judgement summarization. At present, a human-in-the-loop technique is more suitable for performing manual checks to identify inconsistencies in the generated summaries.
Read more7/23/2024
0
Leveraging Large Language Models for Relevance Judgments in Legal Case Retrieval
Shengjie Ma, Chong Chen, Qi Chu, Jiaxin Mao
Collecting relevant judgments for legal case retrieval is a challenging and time-consuming task. Accurately judging the relevance between two legal cases requires a considerable effort to read the lengthy text and a high level of domain expertise to extract Legal Facts and make juridical judgments. With the advent of advanced large language models, some recent studies have suggested that it is promising to use LLMs for relevance judgment. Nonetheless, the method of employing a general large language model for reliable relevance judgments in legal case retrieval is yet to be thoroughly explored. To fill this research gap, we devise a novel few-shot workflow tailored to the relevant judgment of legal cases. The proposed workflow breaks down the annotation process into a series of stages, imitating the process employed by human annotators and enabling a flexible integration of expert reasoning to enhance the accuracy of relevance judgments. By comparing the relevance judgments of LLMs and human experts, we empirically show that we can obtain reliable relevance judgments with the proposed workflow. Furthermore, we demonstrate the capacity to augment existing legal case retrieval models through the synthesis of data generated by the large language model.
Read more7/16/2024
💬
0
Large Language Models for Judicial Entity Extraction: A Comparative Study
Atin Sakkeer Hussain, Anu Thomas
Domain-specific Entity Recognition holds significant importance in legal contexts, serving as a fundamental task that supports various applications such as question-answering systems, text summarization, machine translation, sentiment analysis, and information retrieval specifically within case law documents. Recent advancements have highlighted the efficacy of Large Language Models in natural language processing tasks, demonstrating their capability to accurately detect and classify domain-specific facts (entities) from specialized texts like clinical and financial documents. This research investigates the application of Large Language Models in identifying domain-specific entities (e.g., courts, petitioner, judge, lawyer, respondents, FIR nos.) within case law documents, with a specific focus on their aptitude for handling domain-specific language complexity and contextual variations. The study evaluates the performance of state-of-the-art Large Language Model architectures, including Large Language Model Meta AI 3, Mistral, and Gemma, in the context of extracting judicial facts tailored to Indian judicial texts. Mistral and Gemma emerged as the top-performing models, showcasing balanced precision and recall crucial for accurate entity identification. These findings confirm the value of Large Language Models in judicial documents and demonstrate how they can facilitate and quicken scientific research by producing precise, organised data outputs that are appropriate for in-depth examination.
Read more7/9/2024
0
LaMSUM: A Novel Framework for Extractive Summarization of User Generated Content using LLMs
Garima Chhikara, Anurag Sharma, V. Gurucharan, Kripabandhu Ghosh, Abhijnan Chakraborty
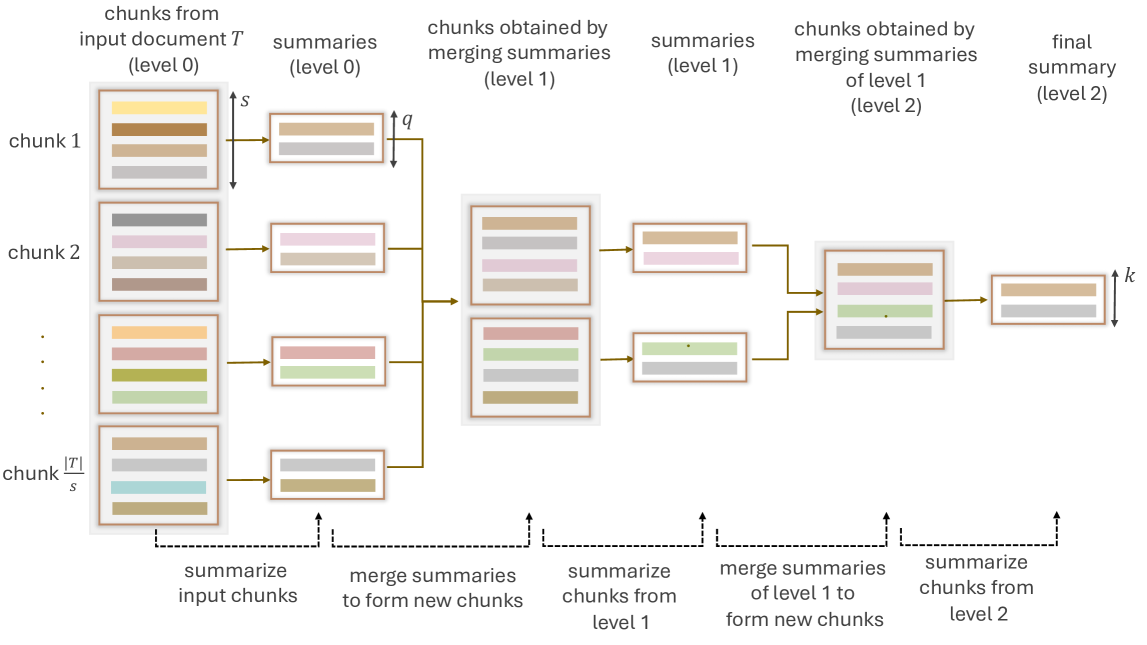
Large Language Models (LLMs) have demonstrated impressive performance across a wide range of NLP tasks, including summarization. LLMs inherently produce abstractive summaries by paraphrasing the original text, while the generation of extractive summaries - selecting specific subsets from the original text - remains largely unexplored. LLMs have a limited context window size, restricting the amount of data that can be processed at once. We tackle this challenge by introducing LaMSUM, a novel multi-level framework designed to generate extractive summaries from large collections of user-generated text using LLMs. LaMSUM integrates summarization with different voting methods to achieve robust summaries. Extensive evaluation using four popular LLMs (Llama 3, Mixtral, Gemini, GPT-4o) demonstrates that LaMSUM outperforms state-of-the-art extractive summarization methods. Overall, this work represents one of the first attempts to achieve extractive summarization by leveraging the power of LLMs, and is likely to spark further interest within the research community.
Read more8/26/2024