Can Large Language Model Summarizers Adapt to Diverse Scientific Communication Goals?
2401.10415
0
0
💬
Abstract
In this work, we investigate the controllability of large language models (LLMs) on scientific summarization tasks. We identify key stylistic and content coverage factors that characterize different types of summaries such as paper reviews, abstracts, and lay summaries. By controlling stylistic features, we find that non-fine-tuned LLMs outperform humans in the MuP review generation task, both in terms of similarity to reference summaries and human preferences. Also, we show that we can improve the controllability of LLMs with keyword-based classifier-free guidance (CFG) while achieving lexical overlap comparable to strong fine-tuned baselines on arXiv and PubMed. However, our results also indicate that LLMs cannot consistently generate long summaries with more than 8 sentences. Furthermore, these models exhibit limited capacity to produce highly abstractive lay summaries. Although LLMs demonstrate strong generic summarization competency, sophisticated content control without costly fine-tuning remains an open problem for domain-specific applications.
Create account to get full access
Overview
- This research investigates how well large language models (LLMs) can be controlled to generate different types of scientific summaries, such as paper reviews, abstracts, and lay summaries.
- The researchers identify key stylistic and content features that characterize these summary types.
- They find that non-fine-tuned LLMs can outperform humans on certain review generation tasks, and that keyword-based guidance can improve the controllability of LLMs on summarization tasks.
- However, LLMs struggle to consistently generate long summaries or highly abstractive lay summaries, indicating that sophisticated content control remains a challenge without costly fine-tuning.
Plain English Explanation
The researchers explored whether large AI language models, which are trained on vast amounts of text data, can be effectively controlled to produce different types of scientific summaries. These include things like paper reviews, abstracts (brief overviews), and lay summaries (explanations for non-experts).
They looked at the key features that distinguish these summary types, such as the writing style and the breadth of information covered. Surprisingly, they found that even without specialized fine-tuning, the language models could outperform humans at generating realistic-sounding paper reviews. This suggests the models have a strong grasp of the style and content expected in that type of summary.
The researchers also showed they could improve the models' control over the summaries by giving them specific keywords to focus on. This allowed the models to match the level of detail and accuracy seen in summaries written by experts, without requiring extensive additional training.
However, the models struggled when asked to generate longer, more comprehensive summaries. They also had difficulty producing highly simplified "lay" summaries that explain complex scientific concepts in plain language. This indicates that while these language models are remarkably capable at summarization in general, fine-tuning or other techniques are still needed to consistently control the content and style of domain-specific summaries.
Technical Explanation
The researchers investigated the ability of large language models (LLMs) to generate different types of scientific summaries, including paper reviews, abstracts, and lay summaries. They identified key stylistic and content factors that distinguish these summary genres, such as [length, level of detail, use of technical jargon, etc.].
Through experiments, they found that non-fine-tuned LLMs can outperform humans on certain review generation tasks, as measured by [metrics like similarity to reference summaries and human preferences]. This suggests these models have a strong grasp of the expected style and content of paper reviews.
The researchers also demonstrated that they could improve the controllability of LLMs using a technique called [keyword-based classifier-free guidance (CFG)]. This allowed the models to generate summaries with lexical overlap comparable to strong fine-tuned baselines on datasets like [ArXiv and PubMed].
However, the results also indicate that LLMs struggle to consistently produce long summaries with more than 8 sentences. Furthermore, the models exhibited limited capacity to generate highly abstractive lay summaries that explain complex scientific concepts in simple terms.
These findings suggest that while LLMs show impressive generic summarization abilities, [controlling the content and style of domain-specific summaries] without costly fine-tuning remains an open challenge. More sophisticated techniques may be needed to fully harness the potential of these large language models for specialized summarization tasks.
Critical Analysis
The researchers provide a thorough investigation into the capabilities and limitations of large language models for scientific summarization. Their identification of key stylistic and content factors that characterize different summary types is a valuable contribution, as it helps illuminate the nuances involved in this task.
The finding that non-fine-tuned LLMs can outperform humans on certain review generation metrics is quite striking and suggests these models have an innate understanding of the expected format and content of that genre. This has promising implications for using LLMs to streamline the peer review process or other summarization-heavy workflows.
However, the researchers also acknowledge significant limitations in the models' ability to generate longer, more comprehensive summaries or highly simplified lay summaries. This aligns with other research on the challenges of controllable text generation and the tendency of LLMs to struggle with structured, domain-specific summarization tasks.
While the keyword-based guidance technique showed promise, the researchers note that more sophisticated content control mechanisms may be needed to fully harness the potential of LLMs for specialized summarization applications. Expanding the evaluation to include more diverse datasets and summary types could also yield additional insights.
Overall, this work contributes valuable empirical evidence to the ongoing discussion around the capabilities and limitations of large language models for scientific communication tasks. The nuanced findings highlight the importance of carefully assessing model performance across a range of relevant metrics and applications.
Conclusion
This research provides a detailed investigation into the ability of large language models to generate different types of scientific summaries, including paper reviews, abstracts, and lay summaries. The researchers identify key stylistic and content factors that distinguish these summary genres, and find that non-fine-tuned LLMs can outperform humans on certain review generation tasks.
The researchers also demonstrate that keyword-based guidance can improve the controllability of LLMs, allowing them to generate summaries with lexical overlap comparable to strong fine-tuned baselines. However, the models struggle to consistently produce long, comprehensive summaries, and exhibit limited capacity for highly abstractive lay summaries.
These findings suggest that while LLMs show impressive generic summarization abilities, sophisticated content control without costly fine-tuning remains an open challenge for domain-specific applications. Continued research into more advanced techniques for controllable text generation may be needed to fully harness the potential of these large language models for specialized scientific communication tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Adapted Large Language Models Can Outperform Medical Experts in Clinical Text Summarization
Dave Van Veen, Cara Van Uden, Louis Blankemeier, Jean-Benoit Delbrouck, Asad Aali, Christian Bluethgen, Anuj Pareek, Malgorzata Polacin, Eduardo Pontes Reis, Anna Seehofnerova, Nidhi Rohatgi, Poonam Hosamani, William Collins, Neera Ahuja, Curtis P. Langlotz, Jason Hom, Sergios Gatidis, John Pauly, Akshay S. Chaudhari
0
0
Analyzing vast textual data and summarizing key information from electronic health records imposes a substantial burden on how clinicians allocate their time. Although large language models (LLMs) have shown promise in natural language processing (NLP), their effectiveness on a diverse range of clinical summarization tasks remains unproven. In this study, we apply adaptation methods to eight LLMs, spanning four distinct clinical summarization tasks: radiology reports, patient questions, progress notes, and doctor-patient dialogue. Quantitative assessments with syntactic, semantic, and conceptual NLP metrics reveal trade-offs between models and adaptation methods. A clinical reader study with ten physicians evaluates summary completeness, correctness, and conciseness; in a majority of cases, summaries from our best adapted LLMs are either equivalent (45%) or superior (36%) compared to summaries from medical experts. The ensuing safety analysis highlights challenges faced by both LLMs and medical experts, as we connect errors to potential medical harm and categorize types of fabricated information. Our research provides evidence of LLMs outperforming medical experts in clinical text summarization across multiple tasks. This suggests that integrating LLMs into clinical workflows could alleviate documentation burden, allowing clinicians to focus more on patient care.
4/15/2024
WisPerMed at BioLaySumm: Adapting Autoregressive Large Language Models for Lay Summarization of Scientific Articles
Tabea M. G. Pakull, Hendrik Damm, Ahmad Idrissi-Yaghir, Henning Schafer, Peter A. Horn, Christoph M. Friedrich
0
0
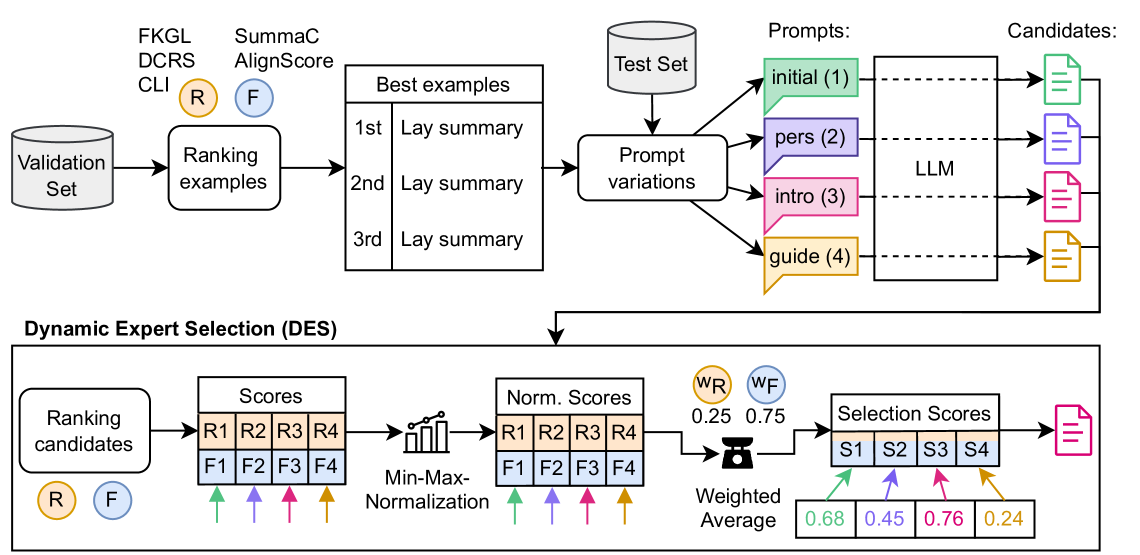
This paper details the efforts of the WisPerMed team in the BioLaySumm2024 Shared Task on automatic lay summarization in the biomedical domain, aimed at making scientific publications accessible to non-specialists. Large language models (LLMs), specifically the BioMistral and Llama3 models, were fine-tuned and employed to create lay summaries from complex scientific texts. The summarization performance was enhanced through various approaches, including instruction tuning, few-shot learning, and prompt variations tailored to incorporate specific context information. The experiments demonstrated that fine-tuning generally led to the best performance across most evaluated metrics. Few-shot learning notably improved the models' ability to generate relevant and factually accurate texts, particularly when using a well-crafted prompt. Additionally, a Dynamic Expert Selection (DES) mechanism to optimize the selection of text outputs based on readability and factuality metrics was developed. Out of 54 participants, the WisPerMed team reached the 4th place, measured by readability, factuality, and relevance. Determined by the overall score, our approach improved upon the baseline by approx. 5.5 percentage points and was only approx 1.5 percentage points behind the first place.
5/21/2024

Evaluating Large Language Models for Structured Science Summarization in the Open Research Knowledge Graph
Vladyslav Nechakhin, Jennifer D'Souza, Steffen Eger
0
0
Structured science summaries or research contributions using properties or dimensions beyond traditional keywords enhances science findability. Current methods, such as those used by the Open Research Knowledge Graph (ORKG), involve manually curating properties to describe research papers' contributions in a structured manner, but this is labor-intensive and inconsistent between the domain expert human curators. We propose using Large Language Models (LLMs) to automatically suggest these properties. However, it's essential to assess the readiness of LLMs like GPT-3.5, Llama 2, and Mistral for this task before application. Our study performs a comprehensive comparative analysis between ORKG's manually curated properties and those generated by the aforementioned state-of-the-art LLMs. We evaluate LLM performance through four unique perspectives: semantic alignment and deviation with ORKG properties, fine-grained properties mapping accuracy, SciNCL embeddings-based cosine similarity, and expert surveys comparing manual annotations with LLM outputs. These evaluations occur within a multidisciplinary science setting. Overall, LLMs show potential as recommendation systems for structuring science, but further finetuning is recommended to improve their alignment with scientific tasks and mimicry of human expertise.
5/6/2024
Characterizing Multimodal Long-form Summarization: A Case Study on Financial Reports
Tianyu Cao, Natraj Raman, Danial Dervovic, Chenhao Tan
0
0
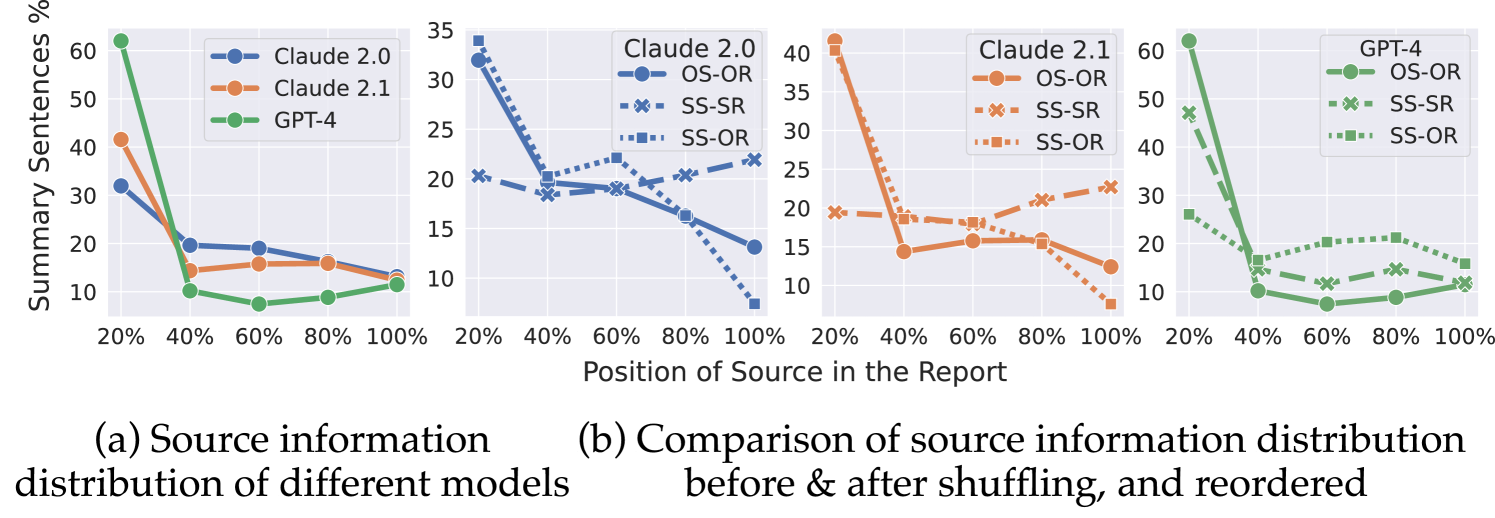
As large language models (LLMs) expand the power of natural language processing to handle long inputs, rigorous and systematic analyses are necessary to understand their abilities and behavior. A salient application is summarization, due to its ubiquity and controversy (e.g., researchers have declared the death of summarization). In this paper, we use financial report summarization as a case study because financial reports not only are long but also use numbers and tables extensively. We propose a computational framework for characterizing multimodal long-form summarization and investigate the behavior of Claude 2.0/2.1, GPT-4/3.5, and Command. We find that GPT-3.5 and Command fail to perform this summarization task meaningfully. For Claude 2 and GPT-4, we analyze the extractiveness of the summary and identify a position bias in LLMs. This position bias disappears after shuffling the input for Claude, which suggests that Claude has the ability to recognize important information. We also conduct a comprehensive investigation on the use of numeric data in LLM-generated summaries and offer a taxonomy of numeric hallucination. We employ prompt engineering to improve GPT-4's use of numbers with limited success. Overall, our analyses highlight the strong capability of Claude 2 in handling long multimodal inputs compared to GPT-4.
5/9/2024