Approaches of large-scale images recognition with more than 50,000 categoris

0
👁️
Sign in to get full access
Overview
- Current computer vision (CV) models can achieve high accuracy on small-scale image classification datasets with hundreds or thousands of categories.
- However, these models often become computationally infeasible or consume too much memory when applied to large-scale datasets with over 50,000 categories.
- This paper presents a viable solution for classifying large-scale species datasets using traditional CV techniques like feature extraction and processing, Bag of Visual Words (BOVW), and statistical learning methods like Mini-Batch K-Means and Support Vector Machines (SVM), combined with a neural network model.
- The authors optimize these techniques to reduce time and memory consumption, making them feasible for large-scale datasets.
- They also use techniques to mitigate the impact of mislabeled data.
Plain English Explanation
Classifying images into hundreds or thousands of categories is relatively easy for modern computer vision models. However, when the number of categories exceeds 50,000, these models become too computationally intensive and require too much memory to be practical.
This paper presents a solution that combines traditional computer vision techniques, like extracting and processing image features, with more advanced statistical learning methods, such as Bag of Visual Words and clustering algorithms. By optimizing these techniques, the researchers were able to create a system that can classify images into over 50,000 categories, even on a standard computer with 6GB of RAM and a 3GHz CPU.
The key ideas are to use a mix of established computer vision methods and modern machine learning approaches, and to carefully optimize the algorithms to reduce the time and memory required. This allows the system to handle the enormous scale of the dataset without needing specialized, high-end hardware.
Technical Explanation
The paper proposes a hybrid approach that combines traditional computer vision techniques with neural network models to tackle the challenge of classifying large-scale datasets with over 50,000 categories.
The traditional CV techniques used include feature extraction and processing, Bag of Visual Words (BOVW), and statistical learning methods like Mini-Batch K-Means and Support Vector Machines (SVM). The authors optimize these techniques to reduce the time and memory consumption, making them feasible for large-scale datasets.
Additionally, the researchers use methods to mitigate the impact of mislabeled data, which can be a common issue with large-scale datasets. The proposed hybrid approach is evaluated on a dataset with more than 50,000 categories, using a standard computer with 6GB of RAM and a 3GHz CPU.
The key contributions of the paper are:
- Analysis of the problems that may arise during the training process for large-scale datasets and presentation of several feasible solutions to address these issues.
- Demonstration of how traditional CV models combined with neural network models can provide viable scenarios for training large-scale classification datasets within the constraints of time and spatial resources.
Critical Analysis
The paper presents a practical solution for classifying large-scale datasets with over 50,000 categories, which is a significant challenge faced by many computer vision applications. The authors' approach of combining traditional CV techniques with modern machine learning methods is a compelling idea, as it leverages the strengths of both approaches to overcome the limitations of each.
One potential limitation of the research is that it was evaluated on a single dataset, and it would be valuable to see how the proposed methods perform on other large-scale datasets with different characteristics. Additionally, the paper does not provide a detailed comparison of the hybrid approach's performance with other state-of-the-art methods for large-scale classification, which would help contextualize the significance of the proposed solution.
Furthermore, the paper does not delve into the specific optimizations made to the traditional CV techniques to reduce time and memory consumption. A more in-depth discussion of these optimizations and their impact on the overall system's performance would be helpful for readers interested in replicating or building upon this research.
Despite these minor limitations, the paper offers a practical and innovative solution to a pressing problem in computer vision, and the authors' work demonstrates the potential of combining established and emerging techniques to tackle large-scale classification challenges. Readers interested in large-scale machine vision applications or optimizing computer vision algorithms may find this research particularly relevant and informative.
Conclusion
This paper presents a viable solution for classifying large-scale datasets with over 50,000 categories using a hybrid approach that combines traditional computer vision techniques and modern machine learning methods. By optimizing the time and memory consumption of the traditional CV techniques, the authors demonstrate that it is possible to train a classification model on a large-scale dataset using only a standard computer.
The key contributions of this research are the analysis of the problems faced when working with large-scale datasets and the presentation of feasible solutions to address these challenges. The proposed hybrid approach, which integrates feature extraction, Bag of Visual Words, statistical learning, and neural networks, offers a promising direction for tackling the computational and storage constraints associated with large-scale classification tasks.
This work has the potential to impact a wide range of computer vision applications, from species identification to fine-grained visual recognition, by providing a scalable and resource-efficient solution for classifying images into a large number of categories. As the demand for large-scale visual classification continues to grow, this research highlights the value of combining established and emerging techniques to push the boundaries of what is possible with limited computational resources.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
0
Approaches of large-scale images recognition with more than 50,000 categoris
Wanhong Huang, Rui Geng
Though current CV models have been able to achieve high levels of accuracy on small-scale images classification dataset with hundreds or thousands of categories, many models become infeasible in computational or space consumption when it comes to large-scale dataset with more than 50,000 categories. In this paper, we provide a viable solution for classifying large-scale species datasets using traditional CV techniques such as.features extraction and processing, BOVW(Bag of Visual Words) and some statistical learning technics like Mini-Batch K-Means,SVM which are used in our works. And then mixed with a neural network model. When applying these techniques, we have done some optimization in time and memory consumption, so that it can be feasible for large-scale dataset. And we also use some technics to reduce the impact of mislabeling data. We use a dataset with more than 50, 000 categories, and all operations are done on common computer with l 6GB RAM and a CPU of 3. OGHz. Our contributions are: 1) analysis what problems may meet in the training processes, and presents several feasible ways to solve these problems. 2) Make traditional CV models combined with neural network models provide some feasible scenarios for training large-scale classified datasets within the constraints of time and spatial resources.
Read more7/10/2024
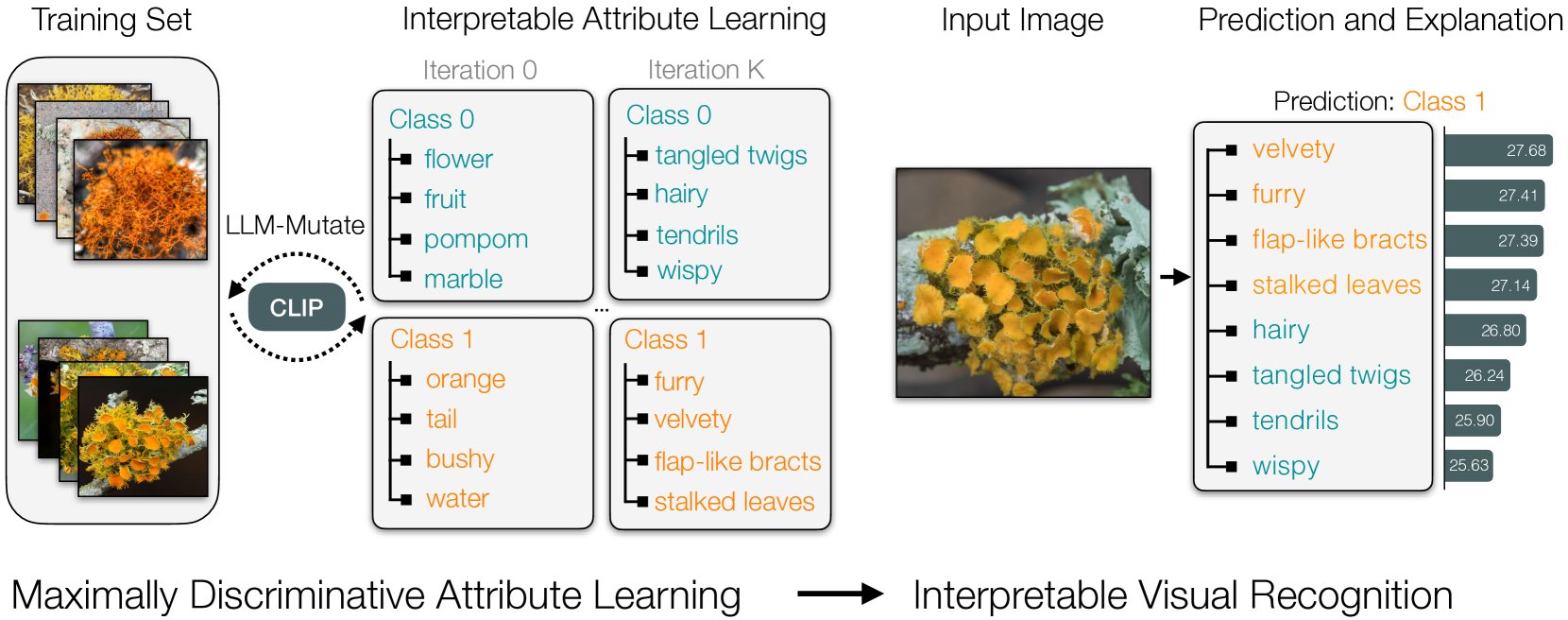
0
Evolving Interpretable Visual Classifiers with Large Language Models
Mia Chiquier, Utkarsh Mall, Carl Vondrick
Multimodal pre-trained models, such as CLIP, are popular for zero-shot classification due to their open-vocabulary flexibility and high performance. However, vision-language models, which compute similarity scores between images and class labels, are largely black-box, with limited interpretability, risk for bias, and inability to discover new visual concepts not written down. Moreover, in practical settings, the vocabulary for class names and attributes of specialized concepts will not be known, preventing these methods from performing well on images uncommon in large-scale vision-language datasets. To address these limitations, we present a novel method that discovers interpretable yet discriminative sets of attributes for visual recognition. We introduce an evolutionary search algorithm that uses a large language model and its in-context learning abilities to iteratively mutate a concept bottleneck of attributes for classification. Our method produces state-of-the-art, interpretable fine-grained classifiers. We outperform the latest baselines by 18.4% on five fine-grained iNaturalist datasets and by 22.2% on two KikiBouba datasets, despite the baselines having access to privileged information about class names.
Read more4/16/2024

0
Growing Deep Neural Network Considering with Similarity between Neurons
Taigo Sakai, Kazuhiro Hotta
Deep learning has excelled in image recognition tasks through neural networks inspired by the human brain. However, the necessity for large models to improve prediction accuracy introduces significant computational demands and extended training times.Conventional methods such as fine-tuning, knowledge distillation, and pruning have the limitations like potential accuracy drops. Drawing inspiration from human neurogenesis, where neuron formation continues into adulthood, we explore a novel approach of progressively increasing neuron numbers in compact models during training phases, thereby managing computational costs effectively. We propose a method that reduces feature extraction biases and neuronal redundancy by introducing constraints based on neuron similarity distributions. This approach not only fosters efficient learning in new neurons but also enhances feature extraction relevancy for given tasks. Results on CIFAR-10 and CIFAR-100 datasets demonstrated accuracy improvement, and our method pays more attention to whole object to be classified in comparison with conventional method through Grad-CAM visualizations. These results suggest that our method's potential to decision-making processes.
Read more8/27/2024

0
Achieving Data Efficient Neural Networks with Hybrid Concept-based Models
Tobias A. Opsahl, Vegard Antun
Most datasets used for supervised machine learning consist of a single label per data point. However, in cases where more information than just the class label is available, would it be possible to train models more efficiently? We introduce two novel model architectures, which we call hybrid concept-based models, that train using both class labels and additional information in the dataset referred to as concepts. In order to thoroughly assess their performance, we introduce ConceptShapes, an open and flexible class of datasets with concept labels. We show that the hybrid concept-based models outperform standard computer vision models and previously proposed concept-based models with respect to accuracy, especially in sparse data settings. We also introduce an algorithm for performing adversarial concept attacks, where an image is perturbed in a way that does not change a concept-based model's concept predictions, but changes the class prediction. The existence of such adversarial examples raises questions about the interpretable qualities promised by concept-based models.
Read more8/15/2024