Evolving Interpretable Visual Classifiers with Large Language Models
2404.09941
0
0
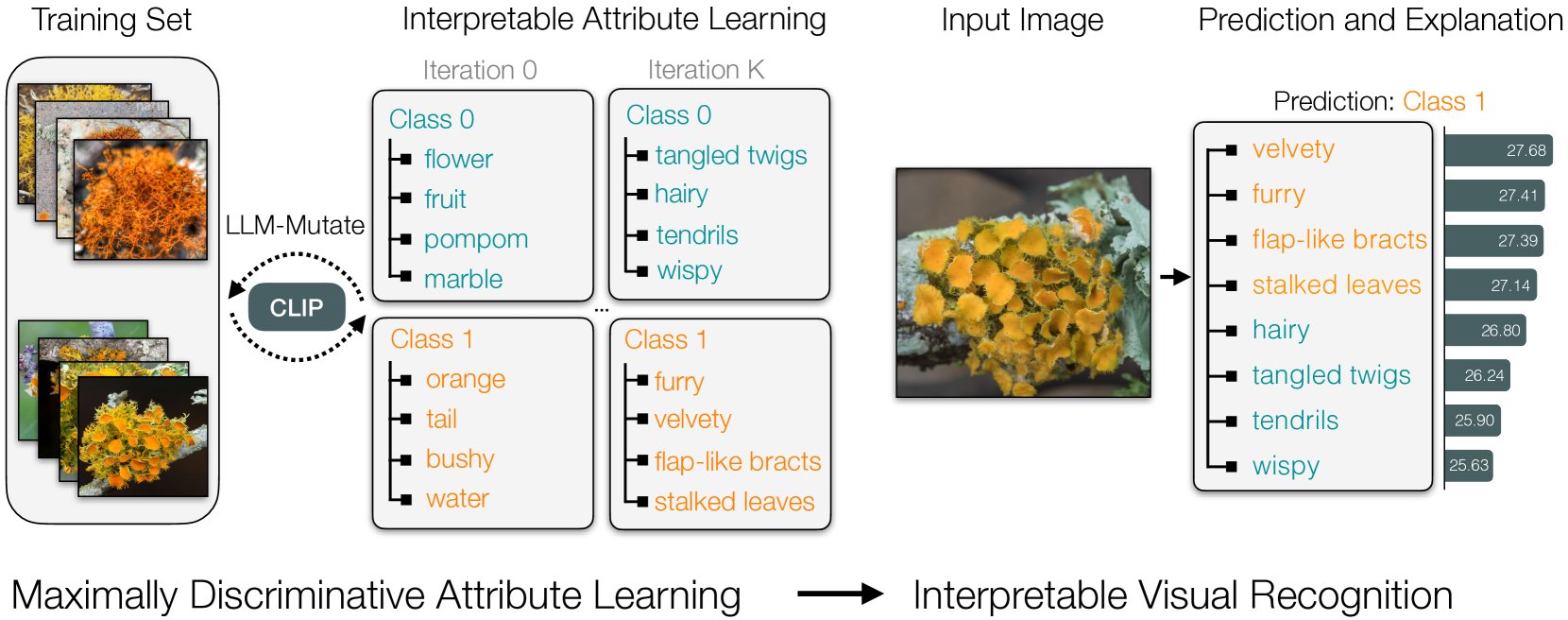
Abstract
Multimodal pre-trained models, such as CLIP, are popular for zero-shot classification due to their open-vocabulary flexibility and high performance. However, vision-language models, which compute similarity scores between images and class labels, are largely black-box, with limited interpretability, risk for bias, and inability to discover new visual concepts not written down. Moreover, in practical settings, the vocabulary for class names and attributes of specialized concepts will not be known, preventing these methods from performing well on images uncommon in large-scale vision-language datasets. To address these limitations, we present a novel method that discovers interpretable yet discriminative sets of attributes for visual recognition. We introduce an evolutionary search algorithm that uses a large language model and its in-context learning abilities to iteratively mutate a concept bottleneck of attributes for classification. Our method produces state-of-the-art, interpretable fine-grained classifiers. We outperform the latest baselines by 18.4% on five fine-grained iNaturalist datasets and by 22.2% on two KikiBouba datasets, despite the baselines having access to privileged information about class names.
Create account to get full access
Overview
- This paper explores using large language models to discover and evolve interpretable visual classifiers.
- The researchers developed a framework that combines the representational power of large language models with evolutionary algorithms to generate visual classifiers that are both accurate and interpretable.
- The approach leverages the language understanding capabilities of large language models to capture semantic concepts, which are then used to guide the evolution of visual classifiers.
Plain English Explanation
The paper discusses a new way to create visual classification models that are not only accurate, but also easy for people to understand. The researchers used large language models, which are AI systems trained on vast amounts of text data to understand language. By connecting these language models to evolutionary algorithms, which gradually improve solutions over many iterations, the team was able to develop visual classifiers that can recognize objects, scenes, and other visual elements while also explaining how they make their decisions.
This is valuable because many state-of-the-art AI vision models are "black boxes" - they can make accurate predictions, but it's difficult to understand the internal logic they use. The approach described in this paper aims to create more transparent and interpretable visual AI, which could lead to greater trust and understanding of these systems.
The key insight is to leverage the rich semantic knowledge encoded in large language models, like those discussed in this survey, to guide the evolution of visual classifiers. This allows the models to learn representations that are grounded in human-understandable concepts, rather than just raw pixel patterns.
Technical Explanation
The paper proposes a framework called LLEO (Large Language Evolved Optimization) that combines large language models with evolutionary algorithms to discover interpretable visual classifiers. The approach works as follows:
- A large language model, such as GPT-3, is used to encode visual concepts into a high-dimensional semantic space. This allows the model to capture rich, human-interpretable representations of visual elements.
- An evolutionary algorithm is then used to optimize a population of candidate visual classifiers. The fitness of each classifier is evaluated not just on accuracy, but also on how well its internal representations align with the semantic concepts from the language model, as measured by techniques like those discussed here.
- Over many generations, the evolutionary process gradually produces visual classifiers that are both accurate and aligned with human-understandable visual concepts, making them more interpretable.
The paper demonstrates the effectiveness of this approach on several benchmark visual recognition tasks, showing that the LLEO-evolved classifiers can achieve competitive accuracy while also providing explanations for their predictions that are grounded in semantic concepts.
Critical Analysis
The paper presents a promising approach for developing interpretable visual AI systems, which is an important challenge in the field. By leveraging the strengths of large language models and evolutionary algorithms, the researchers have shown how to generate classifiers that are both accurate and aligned with human-understandable concepts.
However, the paper does not address some potential limitations and avenues for future work. For example, the evolutionary process can be computationally intensive, and the reliance on language models means the approach may be limited by the biases and shortcomings of those models. Additionally, the paper does not explore how the interpretability of the evolved classifiers could be further improved or quantified.
Future research could investigate ways to make the evolutionary process more efficient, explore alternative methods for aligning visual representations with semantic concepts, and delve deeper into the interpretability and explainability of the resulting classifiers. Comparisons to other zero-shot and prompt-based approaches for bridging vision and language could also provide valuable insights.
Conclusion
This paper presents a novel framework for evolving interpretable visual classifiers by leveraging the power of large language models. The approach demonstrates how the rich semantic knowledge encoded in language models can be used to guide the optimization of visual AI systems, resulting in models that are both accurate and aligned with human-understandable concepts.
The potential impact of this work is significant, as it could lead to the development of more transparent and trustworthy computer vision systems. By making the internal representations and decision-making processes of these models more interpretable, the research paves the way for greater transparency and accountability in real-world applications of visual AI, from autonomous vehicles to medical diagnosis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Enhancing Fine-Grained Image Classifications via Cascaded Vision Language Models
Canshi Wei
0
0
Fine-grained image classification, particularly in zero/few-shot scenarios, presents a significant challenge for vision-language models (VLMs), such as CLIP. These models often struggle with the nuanced task of distinguishing between semantically similar classes due to limitations in their pre-trained recipe, which lacks supervision signals for fine-grained categorization. This paper introduces CascadeVLM, an innovative framework that overcomes the constraints of previous CLIP-based methods by effectively leveraging the granular knowledge encapsulated within large vision-language models (LVLMs). Experiments across various fine-grained image datasets demonstrate that CascadeVLM significantly outperforms existing models, specifically on the Stanford Cars dataset, achieving an impressive 85.6% zero-shot accuracy. Performance gain analysis validates that LVLMs produce more accurate predictions for challenging images that CLIPs are uncertain about, bringing the overall accuracy boost. Our framework sheds light on a holistic integration of VLMs and LVLMs for effective and efficient fine-grained image classification.
5/21/2024
🏷️
Embracing Diversity: Interpretable Zero-shot classification beyond one vector per class
Mazda Moayeri, Michael Rabbat, Mark Ibrahim, Diane Bouchacourt
0
0
Vision-language models enable open-world classification of objects without the need for any retraining. While this zero-shot paradigm marks a significant advance, even today's best models exhibit skewed performance when objects are dissimilar from their typical depiction. Real world objects such as pears appear in a variety of forms -- from diced to whole, on a table or in a bowl -- yet standard VLM classifiers map all instances of a class to a it{single vector based on the class label}. We argue that to represent this rich diversity within a class, zero-shot classification should move beyond a single vector. We propose a method to encode and account for diversity within a class using inferred attributes, still in the zero-shot setting without retraining. We find our method consistently outperforms standard zero-shot classification over a large suite of datasets encompassing hierarchies, diverse object states, and real-world geographic diversity, as well finer-grained datasets where intra-class diversity may be less prevalent. Importantly, our method is inherently interpretable, offering faithful explanations for each inference to facilitate model debugging and enhance transparency. We also find our method scales efficiently to a large number of attributes to account for diversity -- leading to more accurate predictions for atypical instances. Finally, we characterize a principled trade-off between overall and worst class accuracy, which can be tuned via a hyperparameter of our method. We hope this work spurs further research into the promise of zero-shot classification beyond a single class vector for capturing diversity in the world, and building transparent AI systems without compromising performance.
4/26/2024
🏷️
LLM meets Vision-Language Models for Zero-Shot One-Class Classification
Yassir Bendou, Giulia Lioi, Bastien Pasdeloup, Lukas Mauch, Ghouthi Boukli Hacene, Fabien Cardinaux, Vincent Gripon
0
0
We consider the problem of zero-shot one-class visual classification, extending traditional one-class classification to scenarios where only the label of the target class is available. This method aims to discriminate between positive and negative query samples without requiring examples from the target class. We propose a two-step solution that first queries large language models for visually confusing objects and then relies on vision-language pre-trained models (e.g., CLIP) to perform classification. By adapting large-scale vision benchmarks, we demonstrate the ability of the proposed method to outperform adapted off-the-shelf alternatives in this setting. Namely, we propose a realistic benchmark where negative query samples are drawn from the same original dataset as positive ones, including a granularity-controlled version of iNaturalist, where negative samples are at a fixed distance in the taxonomy tree from the positive ones. To our knowledge, we are the first to demonstrate the ability to discriminate a single category from other semantically related ones using only its label.
5/28/2024
Improved Zero-Shot Classification by Adapting VLMs with Text Descriptions
Oindrila Saha, Grant Van Horn, Subhransu Maji
0
0
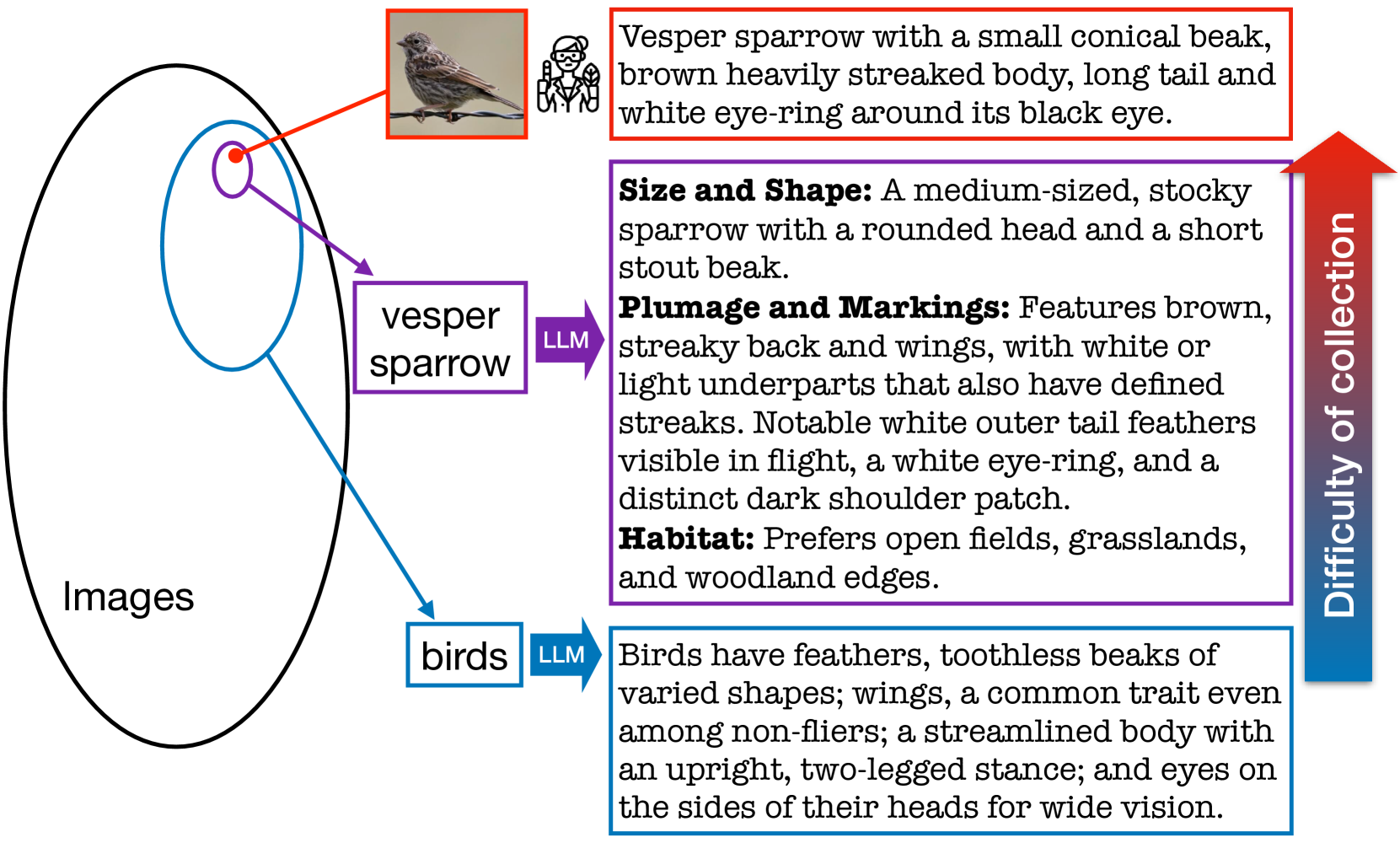
The zero-shot performance of existing vision-language models (VLMs) such as CLIP is limited by the availability of large-scale, aligned image and text datasets in specific domains. In this work, we leverage two complementary sources of information -- descriptions of categories generated by large language models (LLMs) and abundant, fine-grained image classification datasets -- to improve the zero-shot classification performance of VLMs across fine-grained domains. On the technical side, we develop methods to train VLMs with this bag-level image-text supervision. We find that simply using these attributes at test-time does not improve performance, but our training strategy, for example, on the iNaturalist dataset, leads to an average improvement of 4-5% in zero-shot classification accuracy for novel categories of birds and flowers. Similar improvements are observed in domains where a subset of the categories was used to fine-tune the model. By prompting LLMs in various ways, we generate descriptions that capture visual appearance, habitat, and geographic regions and pair them with existing attributes such as the taxonomic structure of the categories. We systematically evaluate their ability to improve zero-shot categorization in natural domains. Our findings suggest that geographic priors can be just as effective and are complementary to visual appearance. Our method also outperforms prior work on prompt-based tuning of VLMs. We release the benchmark, consisting of 14 datasets at https://github.com/cvl-umass/AdaptCLIPZS , which will contribute to future research in zero-shot recognition.
4/5/2024