Are Large Language Models the New Interface for Data Pipelines?
2406.06596
0
0
Abstract
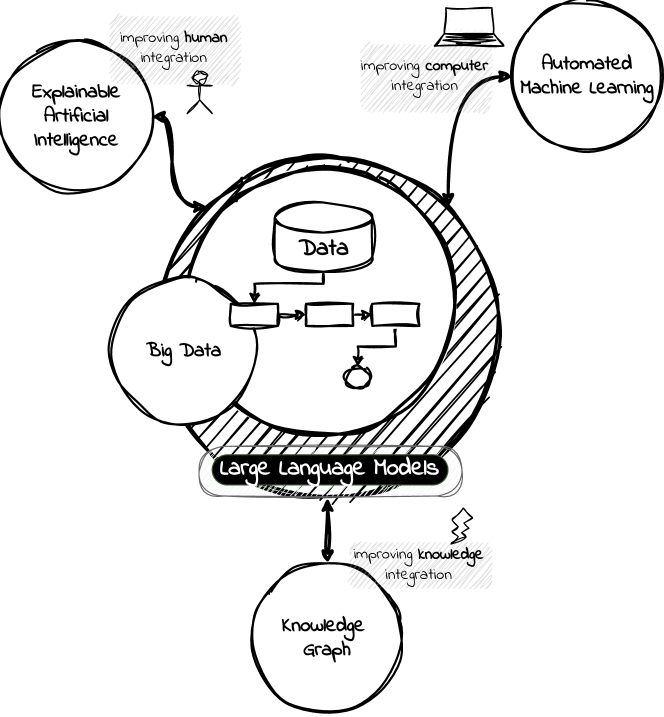
A Language Model is a term that encompasses various types of models designed to understand and generate human communication. Large Language Models (LLMs) have gained significant attention due to their ability to process text with human-like fluency and coherence, making them valuable for a wide range of data-related tasks fashioned as pipelines. The capabilities of LLMs in natural language understanding and generation, combined with their scalability, versatility, and state-of-the-art performance, enable innovative applications across various AI-related fields, including eXplainable Artificial Intelligence (XAI), Automated Machine Learning (AutoML), and Knowledge Graphs (KG). Furthermore, we believe these models can extract valuable insights and make data-driven decisions at scale, a practice commonly referred to as Big Data Analytics (BDA). In this position paper, we provide some discussions in the direction of unlocking synergies among these technologies, which can lead to more powerful and intelligent AI solutions, driving improvements in data pipelines across a wide range of applications and domains integrating humans, computers, and knowledge.
Create account to get full access
Overview
- This paper explores the potential of large language models (LLMs) to serve as a new interface for data pipelines, enabling more accessible and user-friendly data analysis and manipulation.
- LLMs have demonstrated remarkable capabilities in natural language processing, question answering, and general-purpose task completion, leading the authors to investigate their applicability in the context of data science workflows.
- The paper examines the current state of LLM-based data pipeline interfaces, their potential benefits, and the technical and practical challenges that need to be addressed.
Plain English Explanation
Large language models (LLMs) are a type of artificial intelligence that can understand and generate human-like text. <a href="https://aimodels.fyi/papers/arxiv/large-language-models-education-survey-outlook">These models have shown impressive abilities in various tasks, such as answering questions, summarizing documents, and even writing creatively</a>. This paper explores the idea of using LLMs as a new way to interact with and manage data pipelines - the processes that gather, clean, and analyze data.
The authors believe that LLMs could make data science more accessible to a wider audience. Rather than relying on complex coding and programming languages, people could potentially use natural language to describe the data they want to work with and the tasks they want to perform. The LLM would then translate these natural language instructions into the necessary data processing steps.
This could be particularly beneficial for users who are not familiar with traditional data analysis tools and programming. <a href="https://aimodels.fyi/papers/arxiv/large-language-models-medicine-survey">It could also open up new possibilities for domain experts, such as scientists or policymakers, to directly interact with and explore data relevant to their fields</a>.
However, the authors acknowledge that there are significant technical and practical challenges to overcome before LLM-based data pipelines become a reality. For example, ensuring the accuracy and reliability of the language-to-data translation, handling complex data structures, and addressing concerns about privacy and security.
Overall, the paper presents an intriguing vision for the future of data science, where LLMs could serve as a more intuitive and accessible interface for working with data, potentially democratizing access to data analysis and insights.
Technical Explanation
The paper starts by providing an overview of large language models (LLMs) and their remarkable capabilities in natural language processing, question answering, and general-purpose task completion. <a href="https://aimodels.fyi/papers/arxiv/large-language-models-time-series-survey">The authors argue that these capabilities could be leveraged to create a new interface for data pipelines, enabling more user-friendly and accessible data analysis and manipulation</a>.
The paper then delves into the current state of LLM-based data pipeline interfaces, highlighting the potential benefits of this approach. The authors suggest that by allowing users to interact with data using natural language, LLMs could lower the barriers to entry for data science, making it more accessible to a wider audience. This could be particularly valuable for domain experts, such as scientists or policymakers, who may not have extensive programming or data analysis skills but could directly engage with and explore data relevant to their fields.
However, the paper also acknowledges the significant technical and practical challenges that need to be addressed before LLM-based data pipelines become a reality. These include ensuring the accuracy and reliability of the language-to-data translation, handling complex data structures, and addressing concerns about privacy and security.
The authors also discuss the potential limitations of this approach, such as the risk of introducing biases or errors in the language-to-data translation process, and the need for robust governance and oversight to ensure the responsible use of these technologies.
Critical Analysis
The paper presents a compelling vision for the future of data science, where large language models (LLMs) could serve as a more intuitive and accessible interface for working with data. The authors make a strong case for the potential benefits of this approach, particularly in terms of democratizing access to data analysis and insights.
However, the paper also rightly acknowledges the significant technical and practical challenges that need to be addressed before LLM-based data pipelines become a reality. <a href="https://aimodels.fyi/papers/arxiv/apprentices-to-research-assistants-advancing-research-large">Ensuring the accuracy and reliability of the language-to-data translation, handling complex data structures, and addressing concerns about privacy and security will be crucial</a>.
Additionally, the paper could have explored the potential risks and limitations of this approach in more depth. For example, the authors could have delved deeper into the risk of introducing biases or errors in the language-to-data translation process, and the need for robust governance and oversight to ensure the responsible use of these technologies.
<a href="https://aimodels.fyi/papers/arxiv/survey-large-language-models-from-concept-to">Overall, the paper presents an intriguing and forward-looking vision for the future of data science, but more research and development will be needed to overcome the technical and practical hurdles identified by the authors</a>.
Conclusion
This paper explores the potential of large language models (LLMs) to serve as a new interface for data pipelines, enabling more accessible and user-friendly data analysis and manipulation. The authors argue that LLMs' remarkable capabilities in natural language processing could lower the barriers to entry for data science, making it more accessible to a wider audience, including domain experts who may not have extensive programming or data analysis skills.
However, the paper also acknowledges the significant technical and practical challenges that need to be addressed before LLM-based data pipelines become a reality. Ensuring the accuracy and reliability of the language-to-data translation, handling complex data structures, and addressing concerns about privacy and security are just a few of the key issues that will need to be resolved.
Overall, the paper presents an intriguing and forward-looking vision for the future of data science, where LLMs could serve as a more intuitive and accessible interface for working with data. While the technical and practical hurdles are substantial, the potential benefits of this approach, particularly in terms of democratizing access to data analysis and insights, make it a compelling area for further research and development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Large Language Models for Medicine: A Survey
Yanxin Zheng, Wensheng Gan, Zefeng Chen, Zhenlian Qi, Qian Liang, Philip S. Yu
0
0
To address challenges in the digital economy's landscape of digital intelligence, large language models (LLMs) have been developed. Improvements in computational power and available resources have significantly advanced LLMs, allowing their integration into diverse domains for human life. Medical LLMs are essential application tools with potential across various medical scenarios. In this paper, we review LLM developments, focusing on the requirements and applications of medical LLMs. We provide a concise overview of existing models, aiming to explore advanced research directions and benefit researchers for future medical applications. We emphasize the advantages of medical LLMs in applications, as well as the challenges encountered during their development. Finally, we suggest directions for technical integration to mitigate challenges and potential research directions for the future of medical LLMs, aiming to meet the demands of the medical field better.
5/24/2024
Large Language Models for Education: A Survey and Outlook
Shen Wang, Tianlong Xu, Hang Li, Chaoli Zhang, Joleen Liang, Jiliang Tang, Philip S. Yu, Qingsong Wen
0
0
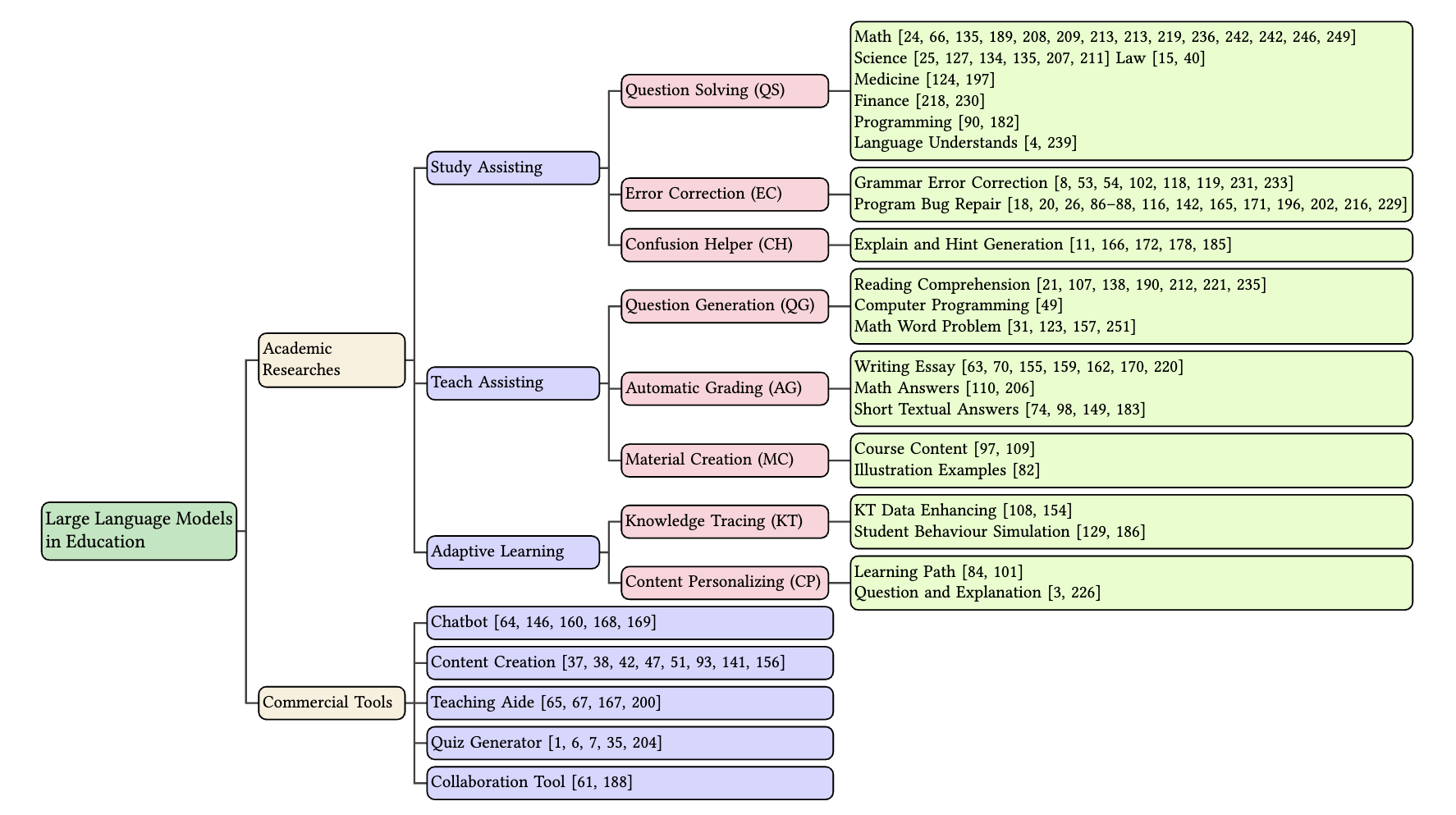
The advent of Large Language Models (LLMs) has brought in a new era of possibilities in the realm of education. This survey paper summarizes the various technologies of LLMs in educational settings from multifaceted perspectives, encompassing student and teacher assistance, adaptive learning, and commercial tools. We systematically review the technological advancements in each perspective, organize related datasets and benchmarks, and identify the risks and challenges associated with deploying LLMs in education. Furthermore, we outline future research opportunities, highlighting the potential promising directions. Our survey aims to provide a comprehensive technological picture for educators, researchers, and policymakers to harness the power of LLMs to revolutionize educational practices and foster a more effective personalized learning environment.
4/3/2024
Large Language Models for Time Series: A Survey
Xiyuan Zhang, Ranak Roy Chowdhury, Rajesh K. Gupta, Jingbo Shang
0
0
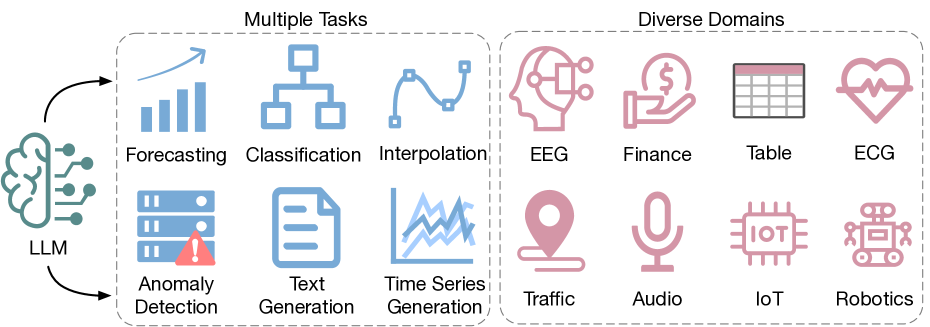
Large Language Models (LLMs) have seen significant use in domains such as natural language processing and computer vision. Going beyond text, image and graphics, LLMs present a significant potential for analysis of time series data, benefiting domains such as climate, IoT, healthcare, traffic, audio and finance. This survey paper provides an in-depth exploration and a detailed taxonomy of the various methodologies employed to harness the power of LLMs for time series analysis. We address the inherent challenge of bridging the gap between LLMs' original text data training and the numerical nature of time series data, and explore strategies for transferring and distilling knowledge from LLMs to numerical time series analysis. We detail various methodologies, including (1) direct prompting of LLMs, (2) time series quantization, (3) aligning techniques, (4) utilization of the vision modality as a bridging mechanism, and (5) the combination of LLMs with tools. Additionally, this survey offers a comprehensive overview of the existing multimodal time series and text datasets and delves into the challenges and future opportunities of this emerging field. We maintain an up-to-date Github repository which includes all the papers and datasets discussed in the survey.
5/8/2024

Large Knowledge Model: Perspectives and Challenges
Huajun Chen
0
0
Humankind's understanding of the world is fundamentally linked to our perception and cognition, with emph{human languages} serving as one of the major carriers of emph{world knowledge}. In this vein, emph{Large Language Models} (LLMs) like ChatGPT epitomize the pre-training of extensive, sequence-based world knowledge into neural networks, facilitating the processing and manipulation of this knowledge in a parametric space. This article explores large models through the lens of knowledge. We initially investigate the role of symbolic knowledge such as Knowledge Graphs (KGs) in enhancing LLMs, covering aspects like knowledge-augmented language model, structure-inducing pre-training, knowledgeable prompts, structured CoT, knowledge editing, semantic tools for LLM and knowledgeable AI agents. Subsequently, we examine how LLMs can boost traditional symbolic knowledge bases, encompassing aspects like using LLM as KG builder and controller, structured knowledge pretraining, and LLM-enhanced symbolic reasoning. Considering the intricate nature of human knowledge, we advocate for the creation of emph{Large Knowledge Models} (LKM), specifically engineered to manage diversified spectrum of knowledge structures. This promising undertaking would entail several key challenges, such as disentangling knowledge base from language models, cognitive alignment with human knowledge, integration of perception and cognition, and building large commonsense models for interacting with physical world, among others. We finally propose a five-A principle to distinguish the concept of LKM.
6/27/2024