Large Knowledge Model: Perspectives and Challenges
2312.02706
0
0

Abstract
Humankind's understanding of the world is fundamentally linked to our perception and cognition, with emph{human languages} serving as one of the major carriers of emph{world knowledge}. In this vein, emph{Large Language Models} (LLMs) like ChatGPT epitomize the pre-training of extensive, sequence-based world knowledge into neural networks, facilitating the processing and manipulation of this knowledge in a parametric space. This article explores large models through the lens of knowledge. We initially investigate the role of symbolic knowledge such as Knowledge Graphs (KGs) in enhancing LLMs, covering aspects like knowledge-augmented language model, structure-inducing pre-training, knowledgeable prompts, structured CoT, knowledge editing, semantic tools for LLM and knowledgeable AI agents. Subsequently, we examine how LLMs can boost traditional symbolic knowledge bases, encompassing aspects like using LLM as KG builder and controller, structured knowledge pretraining, and LLM-enhanced symbolic reasoning. Considering the intricate nature of human knowledge, we advocate for the creation of emph{Large Knowledge Models} (LKM), specifically engineered to manage diversified spectrum of knowledge structures. This promising undertaking would entail several key challenges, such as disentangling knowledge base from language models, cognitive alignment with human knowledge, integration of perception and cognition, and building large commonsense models for interacting with physical world, among others. We finally propose a five-A principle to distinguish the concept of LKM.
Create account to get full access
Overview
- The paper discusses the perspectives and challenges of large knowledge models, which are powerful machine learning systems that can understand and generate human language.
- It explores the differences between language models and knowledge graphs, and how large language models can better capture world knowledge.
- The paper also highlights the need for new challenges and benchmarks to push the boundaries of these models and ensure they are aligned with human values.
Plain English Explanation
Large knowledge models are advanced AI systems that can understand and generate human language. They are different from traditional language models in that they can better capture and reason about real-world knowledge.
For example, a large language model can better understand the relationship between "dog" and "pet" because it has learned about the general concepts of animals and domestication, not just the statistical patterns of language.
However, these models still have limitations. They may struggle with tasks that require deeper reasoning or alignment with human values. The paper argues that we need to develop new benchmarks and challenges to push these models to their full potential and ensure they behave in ways that are beneficial to society.
Technical Explanation
The paper explores the differences between language models and knowledge graphs. Language models are trained on large corpora of text to predict the next word in a sequence, while knowledge graphs are structured databases of facts and relationships.
The authors argue that large language models can better capture world knowledge by learning from the vast amount of text data they are trained on. This allows them to understand concepts and relationships beyond just the statistical patterns of language. They provide examples of how large language models can better comprehend the connection between "dog" and "pet".
However, the paper also highlights the need for new challenges and benchmarks to further develop these models. Current language model evaluations may not adequately test for deeper reasoning or value alignment. The authors suggest exploring areas like commonsense reasoning, multi-task learning, and societal impact to push the boundaries of large knowledge models.
Critical Analysis
The paper makes a compelling case for the potential of large knowledge models, but also acknowledges their current limitations. While these models can capture more world knowledge than traditional language models, they still struggle with tasks that require deeper reasoning or alignment with human values.
The authors rightly point out the need for new benchmarks and challenges to drive further progress. However, it remains to be seen how these new evaluation criteria can be designed and implemented in a way that truly tests the models' capabilities and ensures they behave in a way that is beneficial to society.
Additionally, the paper does not delve into the potential risks and ethical considerations of deploying large language models, such as the spread of misinformation or the amplification of biases. These are important issues that will need to be addressed as these models become more prevalent.
Conclusion
This paper provides a thought-provoking exploration of the perspectives and challenges surrounding large knowledge models. It highlights the potential of these systems to better capture and reason about real-world knowledge, while also acknowledging their current limitations and the need for new benchmarks and challenges to drive further progress.
As these models continue to advance, it will be crucial to ensure they are developed and deployed in a way that is aligned with human values and beneficial to society. This will require ongoing research, innovation, and a critical examination of the ethical implications of these powerful technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
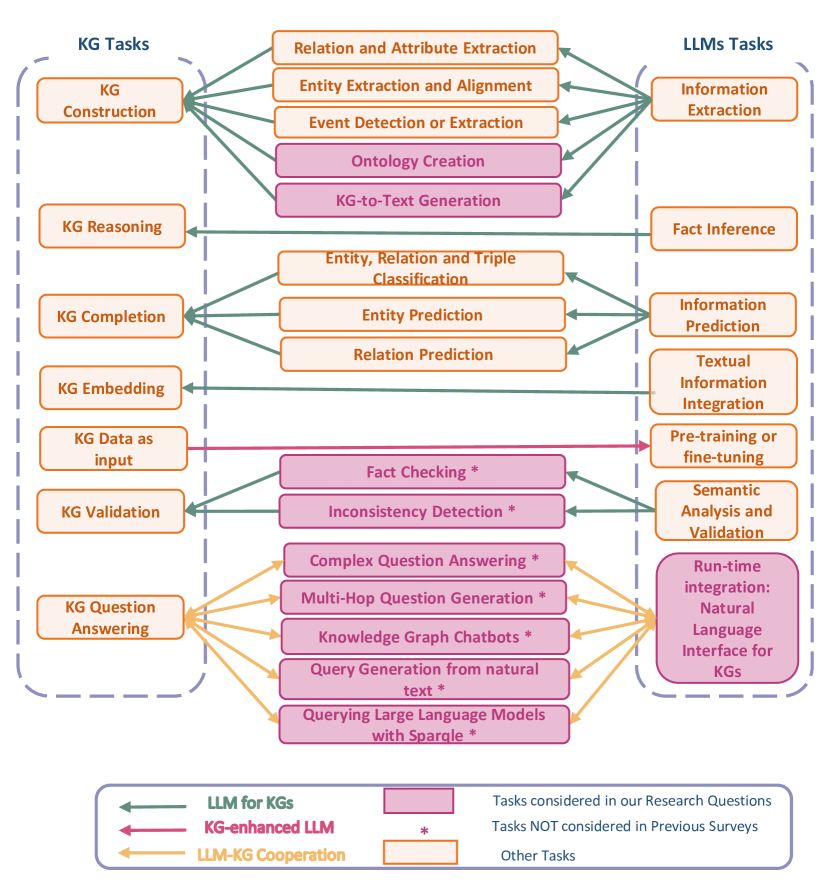
Research Trends for the Interplay between Large Language Models and Knowledge Graphs
Hanieh Khorashadizadeh, Fatima Zahra Amara, Morteza Ezzabady, Fr'ed'eric Ieng, Sanju Tiwari, Nandana Mihindukulasooriya, Jinghua Groppe, Soror Sahri, Farah Benamara, Sven Groppe
0
0
This survey investigates the synergistic relationship between Large Language Models (LLMs) and Knowledge Graphs (KGs), which is crucial for advancing AI's capabilities in understanding, reasoning, and language processing. It aims to address gaps in current research by exploring areas such as KG Question Answering, ontology generation, KG validation, and the enhancement of KG accuracy and consistency through LLMs. The paper further examines the roles of LLMs in generating descriptive texts and natural language queries for KGs. Through a structured analysis that includes categorizing LLM-KG interactions, examining methodologies, and investigating collaborative uses and potential biases, this study seeks to provide new insights into the combined potential of LLMs and KGs. It highlights the importance of their interaction for improving AI applications and outlines future research directions.
6/13/2024
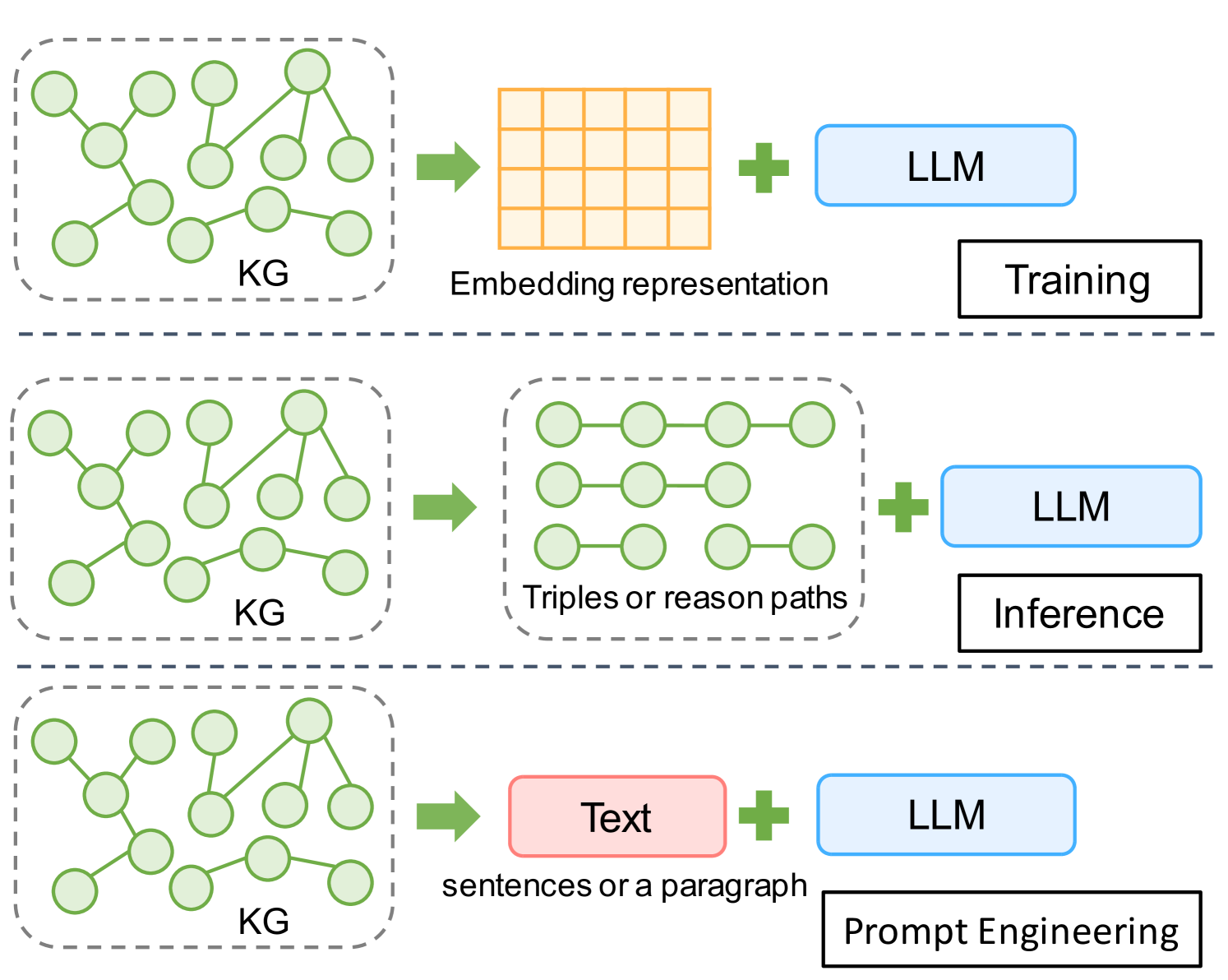
Counter-intuitive: Large Language Models Can Better Understand Knowledge Graphs Than We Thought
Xinbang Dai, Yuncheng Hua, Tongtong Wu, Yang Sheng, Qiu Ji, Guilin Qi
0
0
As the parameter scale of large language models (LLMs) grows, jointly training knowledge graph (KG) embeddings with model parameters to enhance LLM capabilities becomes increasingly costly. Consequently, the community has shown interest in developing prompt strategies that effectively integrate KG information into LLMs. However, the format for incorporating KGs into LLMs lacks standardization; for instance, KGs can be transformed into linearized triples or natural language (NL) text. Current prompting methods often rely on a trial-and-error approach, leaving researchers with an incomplete understanding of which KG input format best facilitates LLM comprehension of KG content. To elucidate this, we design a series of experiments to explore LLMs' understanding of different KG input formats within the context of prompt engineering. Our analysis examines both literal and attention distribution levels. Through extensive experiments, we indicate a counter-intuitive phenomenon: when addressing fact-related questions, unordered linearized triples are more effective for LLMs' understanding of KGs compared to fluent NL text. Furthermore, noisy, incomplete, or marginally relevant subgraphs can still enhance LLM performance. Finally, different LLMs have distinct preferences for different formats of organizing unordered triples.
6/18/2024

Quo Vadis ChatGPT? From Large Language Models to Large Knowledge Models
Venkat Venkatasubramanian, Arijit Chakraborty
0
0
The startling success of ChatGPT and other large language models (LLMs) using transformer-based generative neural network architecture in applications such as natural language processing and image synthesis has many researchers excited about potential opportunities in process systems engineering (PSE). The almost human-like performance of LLMs in these areas is indeed very impressive, surprising, and a major breakthrough. Their capabilities are very useful in certain tasks, such as writing first drafts of documents, code writing assistance, text summarization, etc. However, their success is limited in highly scientific domains as they cannot yet reason, plan, or explain due to their lack of in-depth domain knowledge. This is a problem in domains such as chemical engineering as they are governed by fundamental laws of physics and chemistry (and biology), constitutive relations, and highly technical knowledge about materials, processes, and systems. Although purely data-driven machine learning has its immediate uses, the long-term success of AI in scientific and engineering domains would depend on developing hybrid AI systems that use first principles and technical knowledge effectively. We call these hybrid AI systems Large Knowledge Models (LKMs), as they will not be limited to only NLP-based techniques or NLP-like applications. In this paper, we discuss the challenges and opportunities in developing such systems in chemical engineering.
5/31/2024
💬
Large Human Language Models: A Need and the Challenges
Nikita Soni, H. Andrew Schwartz, Jo~ao Sedoc, Niranjan Balasubramanian
0
0
As research in human-centered NLP advances, there is a growing recognition of the importance of incorporating human and social factors into NLP models. At the same time, our NLP systems have become heavily reliant on LLMs, most of which do not model authors. To build NLP systems that can truly understand human language, we must better integrate human contexts into LLMs. This brings to the fore a range of design considerations and challenges in terms of what human aspects to capture, how to represent them, and what modeling strategies to pursue. To address these, we advocate for three positions toward creating large human language models (LHLMs) using concepts from psychological and behavioral sciences: First, LM training should include the human context. Second, LHLMs should recognize that people are more than their group(s). Third, LHLMs should be able to account for the dynamic and temporally-dependent nature of the human context. We refer to relevant advances and present open challenges that need to be addressed and their possible solutions in realizing these goals.
5/10/2024