Large Language Models for Time Series: A Survey
2402.01801
0
0
Abstract
Large Language Models (LLMs) have seen significant use in domains such as natural language processing and computer vision. Going beyond text, image and graphics, LLMs present a significant potential for analysis of time series data, benefiting domains such as climate, IoT, healthcare, traffic, audio and finance. This survey paper provides an in-depth exploration and a detailed taxonomy of the various methodologies employed to harness the power of LLMs for time series analysis. We address the inherent challenge of bridging the gap between LLMs' original text data training and the numerical nature of time series data, and explore strategies for transferring and distilling knowledge from LLMs to numerical time series analysis. We detail various methodologies, including (1) direct prompting of LLMs, (2) time series quantization, (3) aligning techniques, (4) utilization of the vision modality as a bridging mechanism, and (5) the combination of LLMs with tools. Additionally, this survey offers a comprehensive overview of the existing multimodal time series and text datasets and delves into the challenges and future opportunities of this emerging field. We maintain an up-to-date Github repository which includes all the papers and datasets discussed in the survey.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper provides a comprehensive survey of the use of large language models (LLMs) for time series analysis and forecasting.
- The authors explore the potential of LLMs to address various challenges in time series modeling, such as handling complex temporal patterns, incorporating contextual information, and improving forecast accuracy.
- The paper discusses the current state of the art in LLM-based time series techniques, including evaluating large language models for time series feature engineering, using multi-modal LLMs for time series prediction, and leveraging LLMs as virtual annotators for time series data.
- The survey also covers the application of LLMs in educational settings for time series analysis and explores the potential for generalizing time series foundation models.
Plain English Explanation
This paper looks at how large language models (LLMs) can be used to work with time series data, which is data that changes over time, such as stock prices or weather patterns. The authors explore the benefits of using LLMs for this task, as they can help handle complex patterns in the data, incorporate additional context, and improve the accuracy of forecasts.
The paper discusses the different ways researchers are using LLMs for time series analysis, including using them to extract useful features from the data, combining them with other data sources like images, and using them to annotate or label time series data. The authors also cover how LLMs are being used in educational settings for time series analysis and the potential for developing more general "foundation models" that can be adapted to a wide range of time series problems.
Overall, the paper provides a comprehensive overview of the current state of the art in using LLMs for time series analysis and forecasting, highlighting the promise of this approach as well as some of the ongoing challenges and areas for further research.
Technical Explanation
The paper begins by providing background on time series analysis and the potential benefits of using large language models (LLMs) for this task. The authors explain that traditional time series models often struggle to capture complex temporal patterns and incorporate contextual information, which LLMs may be able to address more effectively.
The paper then presents a taxonomy of LLM-based time series techniques, including:
-
Evaluating large language models for time series feature engineering: Researchers have explored using LLMs to extract useful features from time series data to improve the performance of downstream forecasting models.
-
Using multi-modal LLMs for time series prediction: By combining LLMs with other data sources, such as images or text, researchers have developed models that can leverage a richer set of contextual information for time series forecasting.
-
Leveraging LLMs as virtual annotators for time series data: LLMs can be used to automatically label or annotate time series data, which can be useful for tasks like anomaly detection or segmentation.
The paper also covers the application of LLMs in educational settings for time series analysis and explores the potential for generalizing time series foundation models that can be adapted to a wide range of time series problems.
Critical Analysis
The paper provides a thorough and well-structured survey of the current research on using LLMs for time series analysis. The authors acknowledge some of the limitations and challenges of this approach, such as the need for large, high-quality training datasets and the potential for overfitting or biased outputs.
One area that could have been explored in more depth is the interpretability and explainability of LLM-based time series models. As these models become more complex, it may become increasingly difficult to understand the reasoning behind their predictions, which could be a concern in sensitive applications like finance or healthcare.
Additionally, the paper does not delve into the computational and resource requirements of LLM-based time series models, which could be a significant barrier to their widespread adoption, especially in resource-constrained environments.
Overall, the paper provides a comprehensive and insightful overview of the state of the art in using LLMs for time series analysis, highlighting both the promise and the challenges of this emerging field.
Conclusion
This survey paper presents a detailed exploration of the use of large language models (LLMs) for time series analysis and forecasting. The authors demonstrate the potential of LLMs to address key challenges in traditional time series modeling, such as handling complex temporal patterns and incorporating contextual information.
The paper covers a wide range of LLM-based time series techniques, including feature engineering, multi-modal modeling, and virtual annotation. It also discusses the application of LLMs in educational settings and the potential for developing more general "foundation models" that can be adapted to a variety of time series problems.
While the paper acknowledges some of the limitations and challenges of using LLMs for time series analysis, it provides a comprehensive and insightful overview of the current state of the art in this rapidly evolving field. As LLMs continue to advance and become more widely adopted, the insights and techniques presented in this survey are likely to have a significant impact on the future of time series modeling and forecasting.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Evaluating Large Language Models on Time Series Feature Understanding: A Comprehensive Taxonomy and Benchmark
Elizabeth Fons, Rachneet Kaur, Soham Palande, Zhen Zeng, Svitlana Vyetrenko, Tucker Balch
0
0
Large Language Models (LLMs) offer the potential for automatic time series analysis and reporting, which is a critical task across many domains, spanning healthcare, finance, climate, energy, and many more. In this paper, we propose a framework for rigorously evaluating the capabilities of LLMs on time series understanding, encompassing both univariate and multivariate forms. We introduce a comprehensive taxonomy of time series features, a critical framework that delineates various characteristics inherent in time series data. Leveraging this taxonomy, we have systematically designed and synthesized a diverse dataset of time series, embodying the different outlined features. This dataset acts as a solid foundation for assessing the proficiency of LLMs in comprehending time series. Our experiments shed light on the strengths and limitations of state-of-the-art LLMs in time series understanding, revealing which features these models readily comprehend effectively and where they falter. In addition, we uncover the sensitivity of LLMs to factors including the formatting of the data, the position of points queried within a series and the overall time series length.
4/26/2024

A Review of Multi-Modal Large Language and Vision Models
Kilian Carolan, Laura Fennelly, Alan F. Smeaton
0
0
Large Language Models (LLMs) have recently emerged as a focal point of research and application, driven by their unprecedented ability to understand and generate text with human-like quality. Even more recently, LLMs have been extended into multi-modal large language models (MM-LLMs) which extends their capabilities to deal with image, video and audio information, in addition to text. This opens up applications like text-to-video generation, image captioning, text-to-speech, and more and is achieved either by retro-fitting an LLM with multi-modal capabilities, or building a MM-LLM from scratch. This paper provides an extensive review of the current state of those LLMs with multi-modal capabilities as well as the very recent MM-LLMs. It covers the historical development of LLMs especially the advances enabled by transformer-based architectures like OpenAI's GPT series and Google's BERT, as well as the role of attention mechanisms in enhancing model performance. The paper includes coverage of the major and most important of the LLMs and MM-LLMs and also covers the techniques of model tuning, including fine-tuning and prompt engineering, which tailor pre-trained models to specific tasks or domains. Ethical considerations and challenges, such as data bias and model misuse, are also analysed to underscore the importance of responsible AI development and deployment. Finally, we discuss the implications of open-source versus proprietary models in AI research. Through this review, we provide insights into the transformative potential of MM-LLMs in various applications.
4/3/2024
💬
A Comprehensive Survey of Large Language Models and Multimodal Large Language Models in Medicine
Hanguang Xiao, Feizhong Zhou, Xingyue Liu, Tianqi Liu, Zhipeng Li, Xin Liu, Xiaoxuan Huang
0
0
Since the release of ChatGPT and GPT-4, large language models (LLMs) and multimodal large language models (MLLMs) have garnered significant attention due to their powerful and general capabilities in understanding, reasoning, and generation, thereby offering new paradigms for the integration of artificial intelligence with medicine. This survey comprehensively overviews the development background and principles of LLMs and MLLMs, as well as explores their application scenarios, challenges, and future directions in medicine. Specifically, this survey begins by focusing on the paradigm shift, tracing the evolution from traditional models to LLMs and MLLMs, summarizing the model structures to provide detailed foundational knowledge. Subsequently, the survey details the entire process from constructing and evaluating to using LLMs and MLLMs with a clear logic. Following this, to emphasize the significant value of LLMs and MLLMs in healthcare, we survey and summarize 6 promising applications in healthcare. Finally, the survey discusses the challenges faced by medical LLMs and MLLMs and proposes a feasible approach and direction for the subsequent integration of artificial intelligence with medicine. Thus, this survey aims to provide researchers with a valuable and comprehensive reference guide from the perspectives of the background, principles, and clinical applications of LLMs and MLLMs.
5/15/2024
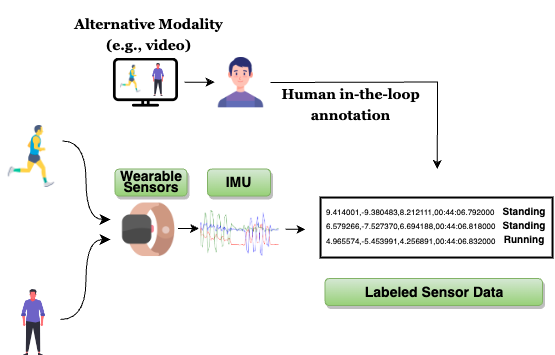
Evaluating Large Language Models as Virtual Annotators for Time-series Physical Sensing Data
Aritra Hota, Soumyajit Chatterjee, Sandip Chakraborty
0
0
Traditional human-in-the-loop-based annotation for time-series data like inertial data often requires access to alternate modalities like video or audio from the environment. These alternate sources provide the necessary information to the human annotator, as the raw numeric data is often too obfuscated even for an expert. However, this traditional approach has many concerns surrounding overall cost, efficiency, storage of additional modalities, time, scalability, and privacy. Interestingly, recent large language models (LLMs) are also trained with vast amounts of publicly available alphanumeric data, which allows them to comprehend and perform well on tasks beyond natural language processing. Naturally, this opens up a potential avenue to explore LLMs as virtual annotators where the LLMs will be directly provided the raw sensor data for annotation instead of relying on any alternate modality. Naturally, this could mitigate the problems of the traditional human-in-the-loop approach. Motivated by this observation, we perform a detailed study in this paper to assess whether the state-of-the-art (SOTA) LLMs can be used as virtual annotators for labeling time-series physical sensing data. To perform this in a principled manner, we segregate the study into two major phases. In the first phase, we investigate the challenges an LLM like GPT-4 faces in comprehending raw sensor data. Considering the observations from phase 1, in the next phase, we investigate the possibility of encoding the raw sensor data using SOTA SSL approaches and utilizing the projected time-series data to get annotations from the LLM. Detailed evaluation with four benchmark HAR datasets shows that SSL-based encoding and metric-based guidance allow the LLM to make more reasonable decisions and provide accurate annotations without requiring computationally expensive fine-tuning or sophisticated prompt engineering.
4/16/2024