Are Vision xLSTM Embedded UNet More Reliable in Medical 3D Image Segmentation?
2406.16993
0
0
👀
Abstract
The advancement of developing efficient medical image segmentation has evolved from initial dependence on Convolutional Neural Networks (CNNs) to the present investigation of hybrid models that combine CNNs with Vision Transformers. Furthermore, there is an increasing focus on creating architectures that are both high-performing in medical image segmentation tasks and computationally efficient to be deployed on systems with limited resources. Although transformers have several advantages like capturing global dependencies in the input data, they face challenges such as high computational and memory complexity. This paper investigates the integration of CNNs and Vision Extended Long Short-Term Memory (Vision-xLSTM) models by introducing a novel approach called UVixLSTM. The Vision-xLSTM blocks captures temporal and global relationships within the patches extracted from the CNN feature maps. The convolutional feature reconstruction path upsamples the output volume from the Vision-xLSTM blocks to produce the segmentation output. Our primary objective is to propose that Vision-xLSTM forms a reliable backbone for medical image segmentation tasks, offering excellent segmentation performance and reduced computational complexity. UVixLSTM exhibits superior performance compared to state-of-the-art networks on the publicly-available Synapse dataset. Code is available at: https://github.com/duttapallabi2907/UVixLSTM
Create account to get full access
Overview
- This paper provides guidelines for authors on how to format their responses to peer reviews for submissions to arXiv, a popular open-access preprint repository for scientific papers.
- The guidelines cover key aspects such as response length, formatting, and the structure of the response.
- By following these guidelines, authors can ensure their responses are clear, concise, and easy for reviewers to navigate.
Plain English Explanation
When you submit a research paper to arXiv, the online preprint repository, the editors may ask you to respond to feedback from peer reviewers. This paper outlines some helpful guidelines to ensure your response is effective.
First, it discusses how long your response should be. The recommendation is to keep it concise, focusing on the key points rather than writing an excessively long document. [link to relevant section]
Next, the paper provides guidance on the formatting of your response. This includes using clear section headings, proper citation formatting, and ensuring your response is easy to read and navigate. [link to relevant section]
The guidelines also suggest a structure for your response, with sections to introduce the feedback, provide a technical explanation, offer a critical analysis, and conclude with the key takeaways. This structure helps you address all the important aspects in a logical flow. [links to relevant sections]
Overall, these guidelines are designed to help you craft a thoughtful, well-organized response that effectively communicates with the editors and reviewers. By following the recommendations, you can increase the clarity and impact of your work.
Technical Explanation
The paper outlines specific guidelines for authors to format their responses to peer reviews when submitting a paper to arXiv.
In the "Response Length" section, the guidelines recommend keeping the response concise, suggesting a target length of around 1-2 pages. This helps ensure the response is focused on the key points rather than becoming overly lengthy. [link to section 1.1]
The "Formatting your Response" section provides detailed instructions on the formatting, including using clear section headings, properly formatting citations, and ensuring the response is easy to read and navigate. This includes recommendations on font size, spacing, and other typesetting details. [link to section 2]
The guidelines also suggest a specific structure for the response, with the following sections:
- Introduction: Briefly acknowledge the feedback and outline the structure of the response.
- Technical Explanation: Provide a detailed technical response to the reviewer comments, referencing relevant parts of the paper.
- Critical Analysis: Discuss any limitations or caveats in the research, as well as areas for potential future work.
- Conclusion: Summarize the key takeaways and their significance.
[links to relevant sections]
This structured approach helps ensure the response addresses all the important aspects in a clear and logical manner, making it easier for reviewers to understand.
Critical Analysis
The guidelines provided in this paper offer a helpful framework for authors to effectively respond to peer review feedback when submitting to arXiv. The recommendations on response length and formatting are sensible, helping to ensure the response is concise and easy to navigate.
One potential limitation is that the guidelines do not provide much flexibility in the structure of the response. While the suggested four-part structure (introduction, technical explanation, critical analysis, conclusion) is logical, some authors may prefer a slightly different organizational approach. Additionally, the guidelines do not address how to handle situations where the feedback is extensive or covers a wide range of issues.
Further research could explore variations in response structure or provide guidance on managing large volumes of feedback. Additionally, the guidelines could be expanded to include tips on the tone and language to use when responding to reviewers, as this can also be an important factor in effective communication.
Overall, however, these guidelines provide a solid foundation for authors to craft high-quality responses that address reviewer comments in a clear and comprehensive manner. By following these recommendations, authors can increase the likelihood of a successful resubmission to arXiv.
Conclusion
The LaTeX Guidelines for Author Response outlined in this paper provide a valuable resource for researchers submitting papers to arXiv. By following the recommendations on response length, formatting, and structure, authors can ensure their responses are clear, concise, and easy for reviewers to understand.
The guidelines' emphasis on a focused, well-organized approach helps authors effectively address the key points raised by reviewers, increasing the chances of a successful resubmission. While the guidelines could be expanded in certain areas, they nevertheless offer a strong framework for authors to communicate their responses in a professional and impactful manner.
Ultimately, these guidelines can help strengthen the peer review process and contribute to the overall quality and transparency of research shared on preprint platforms like arXiv. By adopting these best practices, authors can optimize their interactions with editors and reviewers, leading to improved outcomes for their work.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🚀
Seg-LSTM: Performance of xLSTM for Semantic Segmentation of Remotely Sensed Images
Qinfeng Zhu, Yuanzhi Cai, Lei Fan
0
0
Recent advancements in autoregressive networks with linear complexity have driven significant research progress, demonstrating exceptional performance in large language models. A representative model is the Extended Long Short-Term Memory (xLSTM), which incorporates gating mechanisms and memory structures, performing comparably to Transformer architectures in long-sequence language tasks. Autoregressive networks such as xLSTM can utilize image serialization to extend their application to visual tasks such as classification and segmentation. Although existing studies have demonstrated Vision-LSTM's impressive results in image classification, its performance in image semantic segmentation remains unverified. Our study represents the first attempt to evaluate the effectiveness of Vision-LSTM in the semantic segmentation of remotely sensed images. This evaluation is based on a specifically designed encoder-decoder architecture named Seg-LSTM, and comparisons with state-of-the-art segmentation networks. Our study found that Vision-LSTM's performance in semantic segmentation was limited and generally inferior to Vision-Transformers-based and Vision-Mamba-based models in most comparative tests. Future research directions for enhancing Vision-LSTM are recommended. The source code is available from https://github.com/zhuqinfeng1999/Seg-LSTM.
6/21/2024
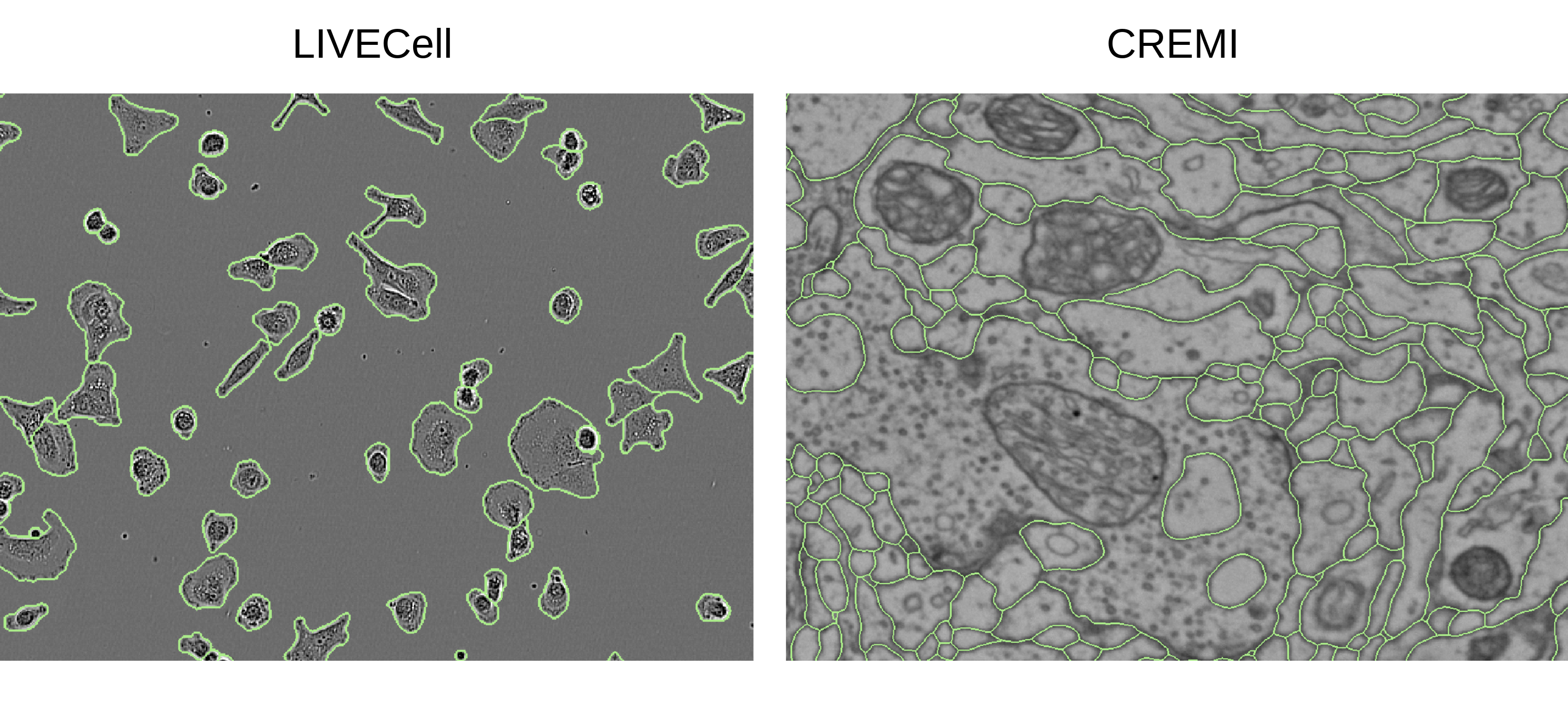
ViM-UNet: Vision Mamba for Biomedical Segmentation
Anwai Archit, Constantin Pape
0
0
CNNs, most notably the UNet, are the default architecture for biomedical segmentation. Transformer-based approaches, such as UNETR, have been proposed to replace them, benefiting from a global field of view, but suffering from larger runtimes and higher parameter counts. The recent Vision Mamba architecture offers a compelling alternative to transformers, also providing a global field of view, but at higher efficiency. Here, we introduce ViM-UNet, a novel segmentation architecture based on it and compare it to UNet and UNETR for two challenging microscopy instance segmentation tasks. We find that it performs similarly or better than UNet, depending on the task, and outperforms UNETR while being more efficient. Our code is open source and documented at https://github.com/constantinpape/torch-em/blob/main/vimunet.md.
5/16/2024
📈
LiteNeXt: A Novel Lightweight ConvMixer-based Model with Self-embedding Representation Parallel for Medical Image Segmentation
Ngoc-Du Tran, Thi-Thao Tran, Quang-Huy Nguyen, Manh-Hung Vu, Van-Truong Pham
0
0
The emergence of deep learning techniques has advanced the image segmentation task, especially for medical images. Many neural network models have been introduced in the last decade bringing the automated segmentation accuracy close to manual segmentation. However, cutting-edge models like Transformer-based architectures rely on large scale annotated training data, and are generally designed with densely consecutive layers in the encoder, decoder, and skip connections resulting in large number of parameters. Additionally, for better performance, they often be pretrained on a larger data, thus requiring large memory size and increasing resource expenses. In this study, we propose a new lightweight but efficient model, namely LiteNeXt, based on convolutions and mixing modules with simplified decoder, for medical image segmentation. The model is trained from scratch with small amount of parameters (0.71M) and Giga Floating Point Operations Per Second (0.42). To handle boundary fuzzy as well as occlusion or clutter in objects especially in medical image regions, we propose the Marginal Weight Loss that can help effectively determine the marginal boundary between object and background. Furthermore, we propose the Self-embedding Representation Parallel technique, that can help augment the data in a self-learning manner. Experiments on public datasets including Data Science Bowls, GlaS, ISIC2018, PH2, and Sunnybrook data show promising results compared to other state-of-the-art CNN-based and Transformer-based architectures. Our code will be published at: https://github.com/tranngocduvnvp/LiteNeXt.
5/28/2024
🖼️
MaxViT-UNet: Multi-Axis Attention for Medical Image Segmentation
Abdul Rehman Khan, Asifullah Khan
0
0
Since their emergence, Convolutional Neural Networks (CNNs) have made significant strides in medical image analysis. However, the local nature of the convolution operator may pose a limitation for capturing global and long-range interactions in CNNs. Recently, Transformers have gained popularity in the computer vision community and also in medical image segmentation due to their ability to process global features effectively. The scalability issues of the self-attention mechanism and lack of the CNN-like inductive bias may have limited their adoption. Therefore, hybrid Vision transformers (CNN-Transformer), exploiting the advantages of both Convolution and Self-attention Mechanisms, have gained importance. In this work, we present MaxViT-UNet, a new Encoder-Decoder based UNet type hybrid vision transformer (CNN-Transformer) for medical image segmentation. The proposed Hybrid Decoder is designed to harness the power of both the convolution and self-attention mechanisms at each decoding stage with a nominal memory and computational burden. The inclusion of multi-axis self-attention, within each decoder stage, significantly enhances the discriminating capacity between the object and background regions, thereby helping in improving the segmentation efficiency. In the Hybrid Decoder, a new block is also proposed. The fusion process commences by integrating the upsampled lower-level decoder features, obtained through transpose convolution, with the skip-connection features derived from the hybrid encoder. Subsequently, the fused features undergo refinement through the utilization of a multi-axis attention mechanism. The proposed decoder block is repeated multiple times to segment the nuclei regions progressively. Experimental results on MoNuSeg18 and MoNuSAC20 datasets demonstrate the effectiveness of the proposed technique.
4/1/2024