ViM-UNet: Vision Mamba for Biomedical Segmentation
2404.07705
0
0
Abstract
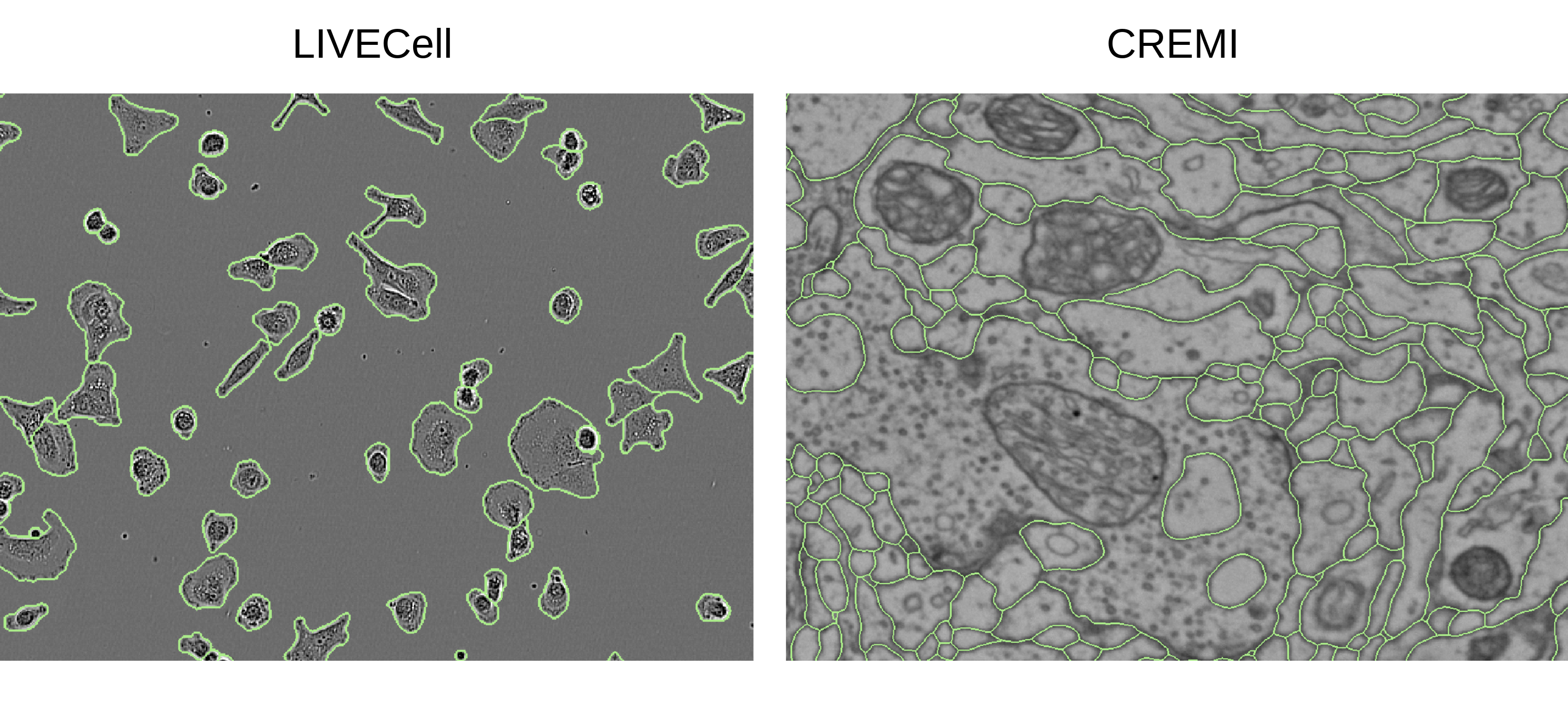
CNNs, most notably the UNet, are the default architecture for biomedical segmentation. Transformer-based approaches, such as UNETR, have been proposed to replace them, benefiting from a global field of view, but suffering from larger runtimes and higher parameter counts. The recent Vision Mamba architecture offers a compelling alternative to transformers, also providing a global field of view, but at higher efficiency. Here, we introduce ViM-UNet, a novel segmentation architecture based on it and compare it to UNet and UNETR for two challenging microscopy instance segmentation tasks. We find that it performs similarly or better than UNet, depending on the task, and outperforms UNETR while being more efficient. Our code is open source and documented at https://github.com/constantinpape/torch-em/blob/main/vimunet.md.
Create account to get full access
Overview
- Introduces a new deep learning model called ViM-UNet (Vision Mamba for Biomedical Segmentation) for medical image segmentation tasks
- Leverages the Vision Mamba architecture and UNet for improved performance on biomedical segmentation problems
- Evaluates the model on various medical imaging datasets and compares it to other state-of-the-art methods
Plain English Explanation
The paper presents a new deep learning model called ViM-UNet that is designed for segmenting medical images. Medical image segmentation is the process of dividing an image into distinct regions, such as organs or tumors, which is an important task for diagnosis and treatment planning.
ViM-UNet builds upon two existing techniques: Vision Mamba, a powerful architecture for modeling visual information, and UNet, a popular model for medical image segmentation. By combining these approaches, the researchers aim to create a more effective model for biomedical segmentation tasks.
The paper evaluates ViM-UNet on several medical imaging datasets and compares its performance to other state-of-the-art methods. The results suggest that ViM-UNet can achieve improved segmentation accuracy compared to existing techniques, which could have important implications for medical applications.
Technical Explanation
The paper introduces a new deep learning model called ViM-UNet (Vision Mamba for Biomedical Segmentation) that is designed for medical image segmentation tasks. ViM-UNet combines two existing approaches: the Vision Mamba architecture and the popular UNet model for medical image segmentation.
The Vision Mamba architecture is a powerful technique for modeling visual information, and the researchers hypothesize that incorporating it into a UNet-based model could lead to improved performance on biomedical segmentation tasks. The UNet model is well-suited for medical image segmentation due to its ability to capture both local and global information in the image.
The paper describes the architecture of the ViM-UNet model, which consists of an encoder-decoder structure with skip connections, similar to the original UNet. However, the encoder and decoder blocks use the Vision Mamba architecture, which includes a novel visual state space modeling approach and attention mechanisms.
The researchers evaluate ViM-UNet on several medical imaging datasets, including brain MRI, chest X-ray, and retinal fundus image segmentation tasks. They compare the performance of ViM-UNet to other state-of-the-art segmentation models, such as MedMaMba and CV-Attention-UNet.
The results show that ViM-UNet achieves improved segmentation accuracy compared to the other methods, demonstrating the potential benefits of combining the Vision Mamba architecture with the UNet model for biomedical image segmentation tasks.
Critical Analysis
The paper presents a well-designed and thoroughly evaluated deep learning model for medical image segmentation. The combination of the Vision Mamba architecture and the UNet model appears to be a promising approach, as evidenced by the improved performance on the evaluated datasets.
However, the paper does not provide a detailed analysis of the limitations or potential drawbacks of the ViM-UNet model. For example, it would be useful to understand the computational complexity and training time requirements of the model, as these factors can be important considerations for real-world medical applications.
Additionally, the paper could have explored the interpretability and explainability of the ViM-UNet model, as this is an important aspect of deploying AI systems in medical settings. Understanding how the model makes decisions and what features it is focusing on could help build trust and facilitate the integration of the technology into clinical workflows.
Further research could also investigate the generalizability of the ViM-UNet model, as the paper only evaluates it on a limited set of medical imaging datasets. Expanding the evaluation to a broader range of modalities and tasks could provide a more comprehensive understanding of the model's capabilities and limitations.
Conclusion
The ViM-UNet model presented in this paper represents a promising advancement in the field of medical image segmentation. By combining the strengths of the Vision Mamba architecture and the UNet model, the researchers have developed a deep learning approach that can outperform existing state-of-the-art methods on various biomedical segmentation tasks.
The improved segmentation accuracy demonstrated by ViM-UNet could have significant implications for medical applications, such as more accurate diagnosis, treatment planning, and disease monitoring. As the adoption of AI-based technologies continues to grow in the healthcare sector, innovations like ViM-UNet will play an increasingly important role in improving patient outcomes and supporting clinicians in their decision-making processes.
While the paper highlights the technical merits of the ViM-UNet model, further research is needed to address potential limitations and explore its broader applicability. Ongoing advancements in this area will likely contribute to the continued progress of AI-powered tools for medical image analysis and their successful integration into clinical workflows.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Rotate to Scan: UNet-like Mamba with Triplet SSM Module for Medical Image Segmentation
Hao Tang, Lianglun Cheng, Guoheng Huang, Zhengguang Tan, Junhao Lu, Kaihong Wu
0
0
Image segmentation holds a vital position in the realms of diagnosis and treatment within the medical domain. Traditional convolutional neural networks (CNNs) and Transformer models have made significant advancements in this realm, but they still encounter challenges because of limited receptive field or high computing complexity. Recently, State Space Models (SSMs), particularly Mamba and its variants, have demonstrated notable performance in the field of vision. However, their feature extraction methods may not be sufficiently effective and retain some redundant structures, leaving room for parameter reduction. Motivated by previous spatial and channel attention methods, we propose Triplet Mamba-UNet. The method leverages residual VSS Blocks to extract intensive contextual features, while Triplet SSM is employed to fuse features across spatial and channel dimensions. We conducted experiments on ISIC17, ISIC18, CVC-300, CVC-ClinicDB, Kvasir-SEG, CVC-ColonDB, and Kvasir-Instrument datasets, demonstrating the superior segmentation performance of our proposed TM-UNet. Additionally, compared to the previous VM-UNet, our model achieves a one-third reduction in parameters.
5/6/2024
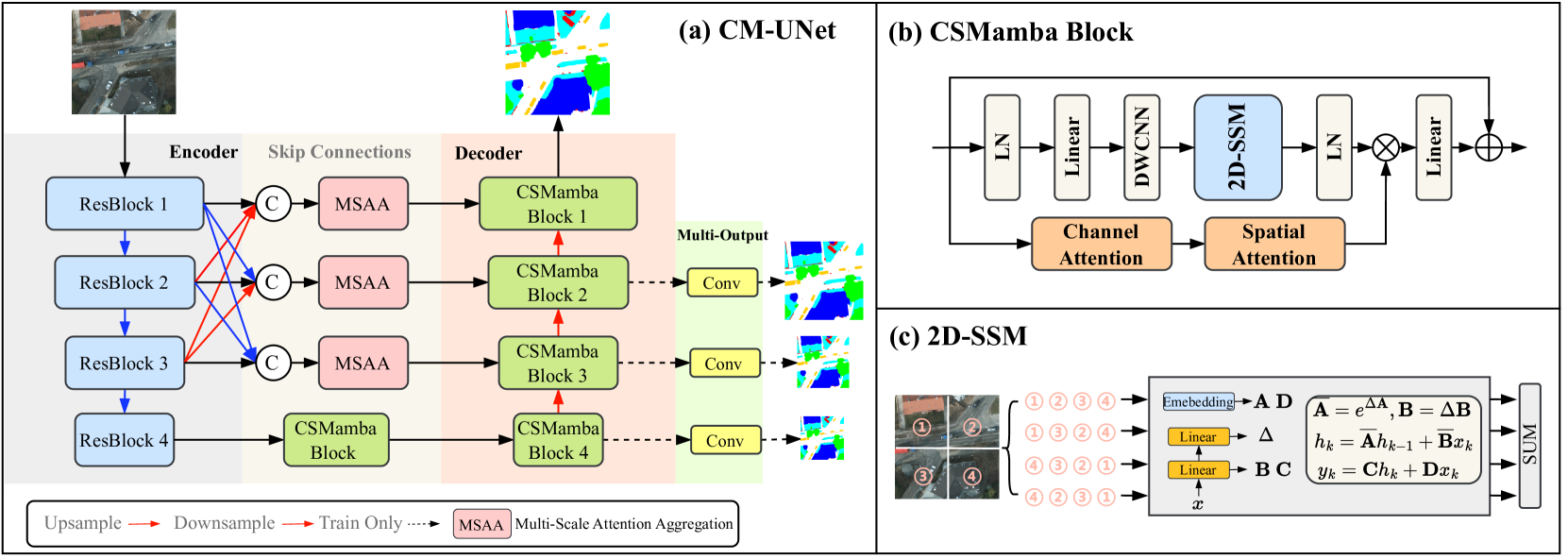
CM-UNet: Hybrid CNN-Mamba UNet for Remote Sensing Image Semantic Segmentation
Mushui Liu, Jun Dan, Ziqian Lu, Yunlong Yu, Yingming Li, Xi Li
0
0
Due to the large-scale image size and object variations, current CNN-based and Transformer-based approaches for remote sensing image semantic segmentation are suboptimal for capturing the long-range dependency or limited to the complex computational complexity. In this paper, we propose CM-UNet, comprising a CNN-based encoder for extracting local image features and a Mamba-based decoder for aggregating and integrating global information, facilitating efficient semantic segmentation of remote sensing images. Specifically, a CSMamba block is introduced to build the core segmentation decoder, which employs channel and spatial attention as the gate activation condition of the vanilla Mamba to enhance the feature interaction and global-local information fusion. Moreover, to further refine the output features from the CNN encoder, a Multi-Scale Attention Aggregation (MSAA) module is employed to merge the different scale features. By integrating the CSMamba block and MSAA module, CM-UNet effectively captures the long-range dependencies and multi-scale global contextual information of large-scale remote-sensing images. Experimental results obtained on three benchmarks indicate that the proposed CM-UNet outperforms existing methods in various performance metrics. The codes are available at https://github.com/XiaoBuL/CM-UNet.
5/20/2024

UltraLight VM-UNet: Parallel Vision Mamba Significantly Reduces Parameters for Skin Lesion Segmentation
Renkai Wu, Yinghao Liu, Pengchen Liang, Qing Chang
0
0
Traditionally for improving the segmentation performance of models, most approaches prefer to use adding more complex modules. And this is not suitable for the medical field, especially for mobile medical devices, where computationally loaded models are not suitable for real clinical environments due to computational resource constraints. Recently, state-space models (SSMs), represented by Mamba, have become a strong competitor to traditional CNNs and Transformers. In this paper, we deeply explore the key elements of parameter influence in Mamba and propose an UltraLight Vision Mamba UNet (UltraLight VM-UNet) based on this. Specifically, we propose a method for processing features in parallel Vision Mamba, named PVM Layer, which achieves excellent performance with the lowest computational load while keeping the overall number of processing channels constant. We conducted comparisons and ablation experiments with several state-of-the-art lightweight models on three skin lesion public datasets and demonstrated that the UltraLight VM-UNet exhibits the same strong performance competitiveness with parameters of only 0.049M and GFLOPs of 0.060. In addition, this study deeply explores the key elements of parameter influence in Mamba, which will lay a theoretical foundation for Mamba to possibly become a new mainstream module for lightweighting in the future. The code is available from https://github.com/wurenkai/UltraLight-VM-UNet .
4/10/2024
👀
Are Vision xLSTM Embedded UNet More Reliable in Medical 3D Image Segmentation?
Pallabi Dutta, Soham Bose, Swalpa Kumar Roy, Sushmita Mitra
0
0
The advancement of developing efficient medical image segmentation has evolved from initial dependence on Convolutional Neural Networks (CNNs) to the present investigation of hybrid models that combine CNNs with Vision Transformers. Furthermore, there is an increasing focus on creating architectures that are both high-performing in medical image segmentation tasks and computationally efficient to be deployed on systems with limited resources. Although transformers have several advantages like capturing global dependencies in the input data, they face challenges such as high computational and memory complexity. This paper investigates the integration of CNNs and Vision Extended Long Short-Term Memory (Vision-xLSTM) models by introducing a novel approach called UVixLSTM. The Vision-xLSTM blocks captures temporal and global relationships within the patches extracted from the CNN feature maps. The convolutional feature reconstruction path upsamples the output volume from the Vision-xLSTM blocks to produce the segmentation output. Our primary objective is to propose that Vision-xLSTM forms a reliable backbone for medical image segmentation tasks, offering excellent segmentation performance and reduced computational complexity. UVixLSTM exhibits superior performance compared to state-of-the-art networks on the publicly-available Synapse dataset. Code is available at: https://github.com/duttapallabi2907/UVixLSTM
6/26/2024