Are We on the Right Way for Evaluating Large Vision-Language Models?
2403.20330
2
0

Abstract
Large vision-language models (LVLMs) have recently achieved rapid progress, sparking numerous studies to evaluate their multi-modal capabilities. However, we dig into current evaluation works and identify two primary issues: 1) Visual content is unnecessary for many samples. The answers can be directly inferred from the questions and options, or the world knowledge embedded in LLMs. This phenomenon is prevalent across current benchmarks. For instance, GeminiPro achieves 42.9% on the MMMU benchmark without any visual input, and outperforms the random choice baseline across six benchmarks over 24% on average. 2) Unintentional data leakage exists in LLM and LVLM training. LLM and LVLM could still answer some visual-necessary questions without visual content, indicating the memorizing of these samples within large-scale training data. For example, Sphinx-X-MoE gets 43.6% on MMMU without accessing images, surpassing its LLM backbone with 17.9%. Both problems lead to misjudgments of actual multi-modal gains and potentially misguide the study of LVLM. To this end, we present MMStar, an elite vision-indispensable multi-modal benchmark comprising 1,500 samples meticulously selected by humans. MMStar benchmarks 6 core capabilities and 18 detailed axes, aiming to evaluate LVLMs' multi-modal capacities with carefully balanced and purified samples. These samples are first roughly selected from current benchmarks with an automated pipeline, human review is then involved to ensure each curated sample exhibits visual dependency, minimal data leakage, and requires advanced multi-modal capabilities. Moreover, two metrics are developed to measure data leakage and actual performance gain in multi-modal training. We evaluate 16 leading LVLMs on MMStar to assess their multi-modal capabilities, and on 7 benchmarks with the proposed metrics to investigate their data leakage and actual multi-modal gain.
Create account to get full access
Overview
- The paper discusses issues with the current approaches to evaluating large vision-language models (LVLMs).
- It highlights two overlooked issues that may be undermining the validity of LVLM evaluations.
- The authors argue that these issues need to be addressed to ensure accurate and meaningful assessments of these powerful models.
Plain English Explanation
Large vision-language models (LVLMs) are artificial intelligence systems that can understand and generate both visual and textual information. They have demonstrated remarkable capabilities in tasks like image captioning, visual question answering, and multimodal reasoning.
However, the authors suggest that the way these models are currently being evaluated may not be providing a complete or accurate picture of their true abilities. They identify two key issues that have been overlooked:
-
Biases in Evaluation Datasets: Many of the datasets used to assess LVLMs are biased, containing stereotypes or limited representations of the real world. This can lead to models performing well on these datasets, but failing to generalize to more diverse or realistic scenarios.
-
Lack of Contextual Understanding: LVLMs may be able to perform well on individual tasks, but struggle to maintain a coherent understanding of the broader context. The authors argue that evaluations need to better assess a model's ability to reason about and integrate information across different contexts.
By addressing these issues, the authors believe researchers and developers can obtain a more comprehensive and reliable understanding of the true capabilities and limitations of large vision-language models. This, in turn, can help guide the development of more robust and trustworthy AI systems.
Technical Explanation
The paper begins by outlining the rapid progress in large vision-language models (LVLMs), which have demonstrated impressive performance on a wide range of multimodal tasks. However, the authors argue that the current approaches to evaluating these models may be flawed, potentially leading to an overestimation of their capabilities.
The first issue they discuss is the problem of biases in evaluation datasets. Many of the datasets used to assess LVLMs, such as image captioning benchmarks, are curated and may contain biases related to gender, race, or cultural representations. This can result in models performing well on these datasets, but failing to generalize to more diverse or realistic scenarios.
The second issue is the lack of contextual understanding exhibited by LVLMs. While these models can excel at individual tasks, the authors suggest that they may struggle to maintain a coherent understanding of the broader context. Evaluations often focus on narrow, decontextualized tasks, rather than assessing a model's ability to reason about and integrate information across different contexts.
To address these issues, the authors recommend several approaches, including the development of more diverse and representative evaluation datasets, as well as the introduction of contextual reasoning tasks that require models to demonstrate a deeper understanding of the relationships between visual and textual information.
Critical Analysis
The issues raised in the paper are valid and important considerations for the field of large vision-language models. The authors make a compelling case that the current evaluation practices may be overlooking fundamental limitations in the capabilities of these models.
However, the paper does not provide detailed solutions or specific recommendations for how to address these problems. While the authors suggest the need for more diverse datasets and contextual reasoning tasks, they do not offer concrete examples or guidelines for how to implement these improvements.
Additionally, the paper does not discuss the challenges and trade-offs involved in developing more robust evaluation methods. Curating diverse datasets and designing appropriate contextual tasks may be resource-intensive and technically challenging. The authors could have explored these practical considerations in more depth.
Furthermore, the paper does not address the broader implications of these evaluation issues, such as the potential impact on the real-world deployment of LVLMs or the ethical considerations surrounding the use of biased or limited datasets.
Overall, the paper raises important concerns that deserve further attention and research. Addressing the biases and contextual limitations in LVLM evaluations could lead to the development of more reliable and trustworthy AI systems. However, the solutions proposed in the paper lack the level of detail and practical considerations needed to guide the implementation of these improvements.
Conclusion
The paper highlights two overlooked issues in the current approaches to evaluating large vision-language models (LVLMs): biases in evaluation datasets and the lack of contextual understanding. These issues may be undermining the validity of LVLM assessments, potentially leading to an overestimation of their capabilities.
By addressing these concerns, the authors argue that researchers and developers can obtain a more comprehensive and realistic understanding of the strengths and limitations of these powerful AI systems. This, in turn, can inform the development of more robust and trustworthy LVLMs that can be deployed with greater confidence in real-world applications.
Overall, the paper makes a valuable contribution to the ongoing discussion around the evaluation of large multimodal models, and the importance of ensuring that these assessments are accurate and meaningful. Further research and practical solutions are needed to address the issues raised, but the authors have highlighted a critical area that deserves greater attention in the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

A Review of Multi-Modal Large Language and Vision Models
Kilian Carolan, Laura Fennelly, Alan F. Smeaton
0
0
Large Language Models (LLMs) have recently emerged as a focal point of research and application, driven by their unprecedented ability to understand and generate text with human-like quality. Even more recently, LLMs have been extended into multi-modal large language models (MM-LLMs) which extends their capabilities to deal with image, video and audio information, in addition to text. This opens up applications like text-to-video generation, image captioning, text-to-speech, and more and is achieved either by retro-fitting an LLM with multi-modal capabilities, or building a MM-LLM from scratch. This paper provides an extensive review of the current state of those LLMs with multi-modal capabilities as well as the very recent MM-LLMs. It covers the historical development of LLMs especially the advances enabled by transformer-based architectures like OpenAI's GPT series and Google's BERT, as well as the role of attention mechanisms in enhancing model performance. The paper includes coverage of the major and most important of the LLMs and MM-LLMs and also covers the techniques of model tuning, including fine-tuning and prompt engineering, which tailor pre-trained models to specific tasks or domains. Ethical considerations and challenges, such as data bias and model misuse, are also analysed to underscore the importance of responsible AI development and deployment. Finally, we discuss the implications of open-source versus proprietary models in AI research. Through this review, we provide insights into the transformative potential of MM-LLMs in various applications.
4/3/2024
💬
Explaining Multi-modal Large Language Models by Analyzing their Vision Perception
Loris Giulivi, Giacomo Boracchi
0
0
Multi-modal Large Language Models (MLLMs) have demonstrated remarkable capabilities in understanding and generating content across various modalities, such as images and text. However, their interpretability remains a challenge, hindering their adoption in critical applications. This research proposes a novel approach to enhance the interpretability of MLLMs by focusing on the image embedding component. We combine an open-world localization model with a MLLM, thus creating a new architecture able to simultaneously produce text and object localization outputs from the same vision embedding. The proposed architecture greatly promotes interpretability, enabling us to design a novel saliency map to explain any output token, to identify model hallucinations, and to assess model biases through semantic adversarial perturbations.
5/29/2024
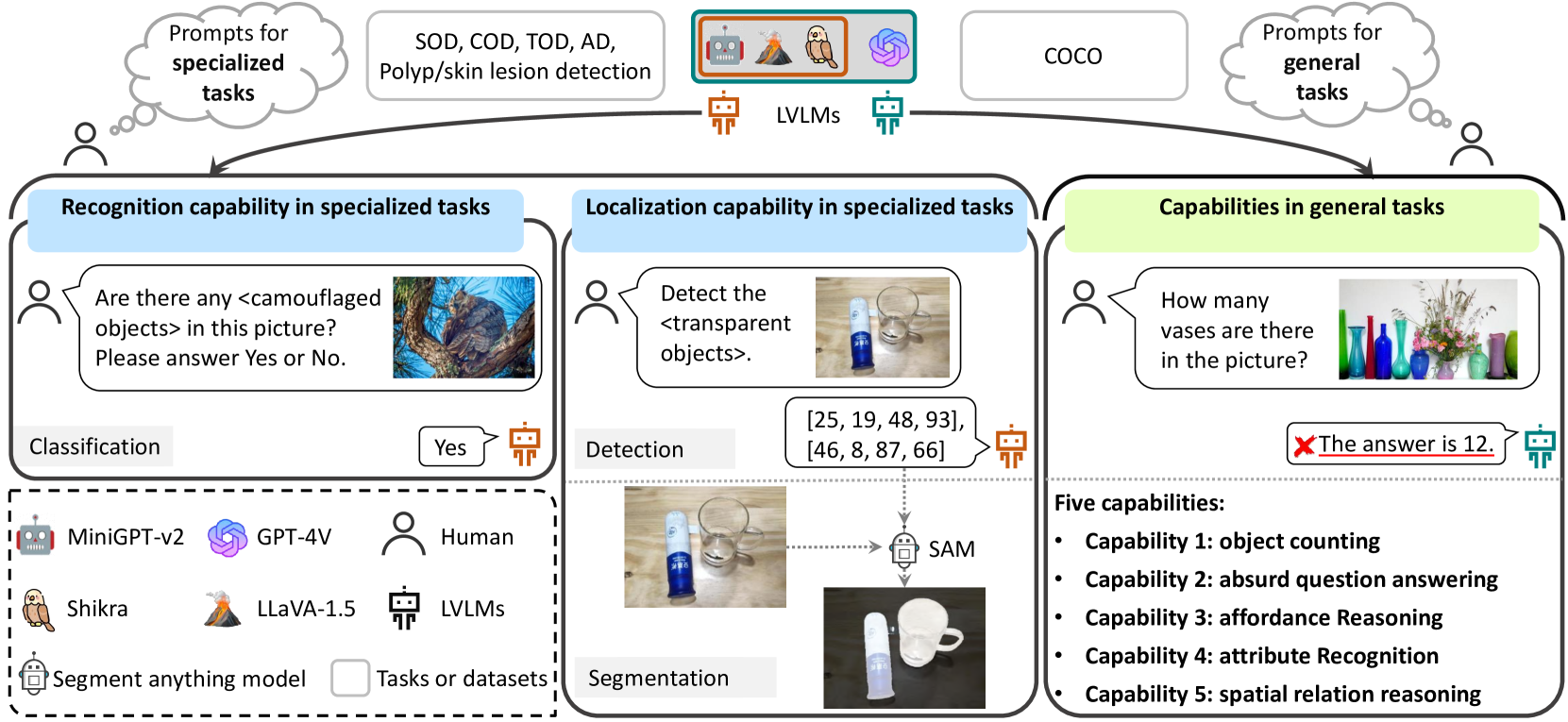
Effectiveness Assessment of Recent Large Vision-Language Models
Yao Jiang, Xinyu Yan, Ge-Peng Ji, Keren Fu, Meijun Sun, Huan Xiong, Deng-Ping Fan, Fahad Shahbaz Khan
0
0
The advent of large vision-language models (LVLMs) represents a remarkable advance in the quest for artificial general intelligence. However, the model's effectiveness in both specialized and general tasks warrants further investigation. This paper endeavors to evaluate the competency of popular LVLMs in specialized and general tasks, respectively, aiming to offer a comprehensive understanding of these novel models. To gauge their effectiveness in specialized tasks, we employ six challenging tasks in three different application scenarios: natural, healthcare, and industrial. These six tasks include salient/camouflaged/transparent object detection, as well as polyp detection, skin lesion detection, and industrial anomaly detection. We examine the performance of three recent open-source LVLMs, including MiniGPT-v2, LLaVA-1.5, and Shikra, on both visual recognition and localization in these tasks. Moreover, we conduct empirical investigations utilizing the aforementioned LVLMs together with GPT-4V, assessing their multi-modal understanding capabilities in general tasks including object counting, absurd question answering, affordance reasoning, attribute recognition, and spatial relation reasoning. Our investigations reveal that these LVLMs demonstrate limited proficiency not only in specialized tasks but also in general tasks. We delve deep into this inadequacy and uncover several potential factors, including limited cognition in specialized tasks, object hallucination, text-to-image interference, and decreased robustness in complex problems. We hope that this study can provide useful insights for the future development of LVLMs, helping researchers improve LVLMs for both general and specialized applications.
6/12/2024

Behind the Magic, MERLIM: Multi-modal Evaluation Benchmark for Large Image-Language Models
Andr'es Villa, Juan Carlos Le'on Alc'azar, Alvaro Soto, Bernard Ghanem
0
0
Large Vision and Language Models have enabled significant advances in fully supervised and zero-shot visual tasks. These large architectures serve as the baseline to what is currently known as Instruction Tuning Large Vision and Language models (IT-LVLMs). IT-LVLMs are general-purpose multi-modal assistants whose responses are modulated by natural language instructions and visual data. Despite this versatility, IT-LVLM effectiveness in fundamental computer vision problems remains unclear, primarily due to the absence of a standardized evaluation benchmark. This paper introduces a Multi-modal Evaluation Benchmark named MERLIM, a scalable test-bed to assess the capabilities of IT-LVLMs on fundamental computer vision tasks. MERLIM contains over 300K image-question pairs and has a strong focus on detecting cross-modal hallucination events in IT-LVLMs. Our results bring important insights on the performance of state-of-the-art IT-LVMLs including limitations at identifying fine-grained visual concepts, object hallucinations across tasks, and biases towards the language query. Our findings also suggest that these models have weak visual grounding, but manage to make adequate guesses from global visual patterns or language biases contained in the LLM component.
6/13/2024