Effectiveness Assessment of Recent Large Vision-Language Models
2403.04306
0
0
Abstract
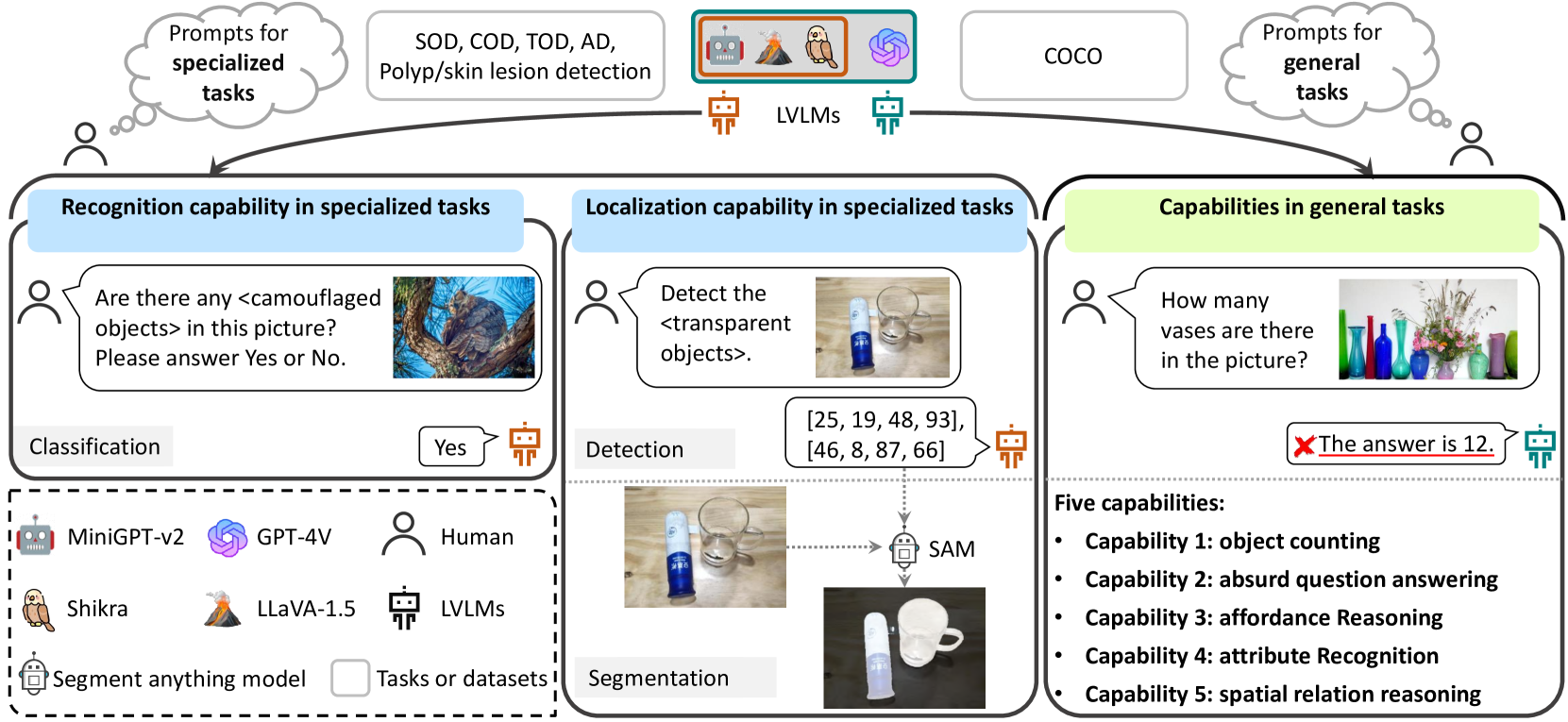
The advent of large vision-language models (LVLMs) represents a noteworthy advancement towards the pursuit of artificial general intelligence. However, the model efficacy across both specialized and general tasks warrants further investigation. This paper endeavors to evaluate the competency of popular LVLMs in specialized and general tasks, respectively, aiming to offer a comprehensive understanding of these novel models. To gauge their efficacy in specialized tasks, we employ six challenging tasks across three distinct application scenarios, namely natural, healthcare, and industrial ones. Such six tasks include salient/camouflaged/transparent object detection, as well as polyp detection, skin lesion detection, and industrial anomaly detection. We examine the performance of three recent open-source LVLMs, including MiniGPT-v2, LLaVA-1.5, and Shikra, on both visual recognition and localization under these tasks. Moreover, we conduct empirical investigations utilizing the aforementioned LVLMs together with GPT-4V, assessing their multi-modal understanding capabilities in general tasks including object counting, absurd question answering, affordance reasoning, attribute recognition, and spatial relation reasoning. Our investigations reveal that these LVLMs demonstrate limited proficiency not only in specialized tasks but also in general tasks. We delve deep into this inadequacy and uncover several potential factors, including limited cognition in specialized tasks, object hallucination, text-to-image interference, and decreased robustness in complex problems. We hope this study could provide useful insights for the future development of LVLMs, helping researchers improve LVLMs to cope with both general and specialized applications.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Examines the effectiveness of recent large vision-language models (LVLMs) in various specialized tasks
- Covers topics such as recognition via LVLMs, localization, and multi-modal understanding
- Also discusses hallucination in LVLMs and their application in medical report generation
Plain English Explanation
The paper examines the performance of recent large vision-language models (LVLMs) – AI systems that can understand both images and text – in specialized tasks. These tasks include object recognition (identifying what's in an image), object localization (finding where things are in an image), and multi-modal understanding (comprehending the relationship between images and text).
The researchers also look at how these LVLMs can sometimes "hallucinate" – generate incorrect or nonsensical information – and how they can be applied to generate medical reports from visual data. The goal is to assess the current capabilities and limitations of these powerful AI models, which have shown impressive results in areas like image captioning and visual question answering.
By understanding where LVLMs excel and where they struggle, the research can help guide the development of more robust and reliable vision-language AI systems in the future.
Technical Explanation
The paper presents a comprehensive evaluation of recent large vision-language models (LVLMs) across a variety of specialized tasks. These tasks include object recognition, localization, and multi-modal understanding.
The researchers examine the performance of state-of-the-art LVLMs on benchmark datasets for these tasks, leveraging both quantitative metrics and qualitative analysis. They also investigate the issue of hallucination in LVLMs, where the models generate incorrect or nonsensical information, and explore the application of these models in medical report generation from visual data.
The findings provide valuable insights into the current capabilities and limitations of large vision-language models, informing the ongoing development of these powerful AI systems.
Critical Analysis
The paper offers a thorough and systematic assessment of recent LVLMs, highlighting both their strengths and weaknesses across a range of specialized tasks. However, the authors acknowledge that the field is rapidly evolving, and the performance of these models may continue to improve with further advancements in architecture and training.
One potential concern raised is the issue of hallucination, where LVLMs can generate incorrect or nonsensical information, particularly in open-ended tasks. The authors suggest that further research is needed to better understand and mitigate this challenge.
Additionally, while the application of LVLMs in medical report generation is promising, the authors note that these models may require domain-specific fine-tuning and careful oversight to ensure reliable and trustworthy performance in high-stakes medical scenarios.
Overall, the research provides a valuable contribution to the ongoing discussion around the evaluation and practical deployment of large vision-language models, highlighting both their potential and the need for continued innovation and responsible development.
Conclusion
This paper offers a comprehensive assessment of the effectiveness of recent large vision-language models (LVLMs) in specialized tasks, including object recognition, localization, and multi-modal understanding. The findings provide valuable insights into the current capabilities and limitations of these powerful AI systems, informing ongoing research and development efforts.
The researchers identify key strengths, such as impressive performance on benchmark datasets, as well as persistent challenges, such as the issue of hallucination. They also explore the application of LVLMs in medical report generation, highlighting both the promise and the need for careful domain-specific adaptation and oversight.
Overall, this work contributes to the growing body of research aimed at understanding and advancing the state-of-the-art in vision-language AI, with the ultimate goal of developing more robust, reliable, and beneficial systems for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Exploring the Frontier of Vision-Language Models: A Survey of Current Methodologies and Future Directions
Akash Ghosh, Arkadeep Acharya, Sriparna Saha, Vinija Jain, Aman Chadha
0
0
The advent of Large Language Models (LLMs) has significantly reshaped the trajectory of the AI revolution. Nevertheless, these LLMs exhibit a notable limitation, as they are primarily adept at processing textual information. To address this constraint, researchers have endeavored to integrate visual capabilities with LLMs, resulting in the emergence of Vision-Language Models (VLMs). These advanced models are instrumental in tackling more intricate tasks such as image captioning and visual question answering. In our comprehensive survey paper, we delve into the key advancements within the realm of VLMs. Our classification organizes VLMs into three distinct categories: models dedicated to vision-language understanding, models that process multimodal inputs to generate unimodal (textual) outputs and models that both accept and produce multimodal inputs and outputs.This classification is based on their respective capabilities and functionalities in processing and generating various modalities of data.We meticulously dissect each model, offering an extensive analysis of its foundational architecture, training data sources, as well as its strengths and limitations wherever possible, providing readers with a comprehensive understanding of its essential components. We also analyzed the performance of VLMs in various benchmark datasets. By doing so, we aim to offer a nuanced understanding of the diverse landscape of VLMs. Additionally, we underscore potential avenues for future research in this dynamic domain, anticipating further breakthroughs and advancements.
4/16/2024
Beyond Human Vision: The Role of Large Vision Language Models in Microscope Image Analysis
Prateek Verma, Minh-Hao Van, Xintao Wu
0
0
Vision language models (VLMs) have recently emerged and gained the spotlight for their ability to comprehend the dual modality of image and textual data. VLMs such as LLaVA, ChatGPT-4, and Gemini have recently shown impressive performance on tasks such as natural image captioning, visual question answering (VQA), and spatial reasoning. Additionally, a universal segmentation model by Meta AI, Segment Anything Model (SAM) shows unprecedented performance at isolating objects from unforeseen images. Since medical experts, biologists, and materials scientists routinely examine microscopy or medical images in conjunction with textual information in the form of captions, literature, or reports, and draw conclusions of great importance and merit, it is indubitably essential to test the performance of VLMs and foundation models such as SAM, on these images. In this study, we charge ChatGPT, LLaVA, Gemini, and SAM with classification, segmentation, counting, and VQA tasks on a variety of microscopy images. We observe that ChatGPT and Gemini are impressively able to comprehend the visual features in microscopy images, while SAM is quite capable at isolating artefacts in a general sense. However, the performance is not close to that of a domain expert - the models are readily encumbered by the introduction of impurities, defects, artefact overlaps and diversity present in the images.
5/3/2024

Are We on the Right Way for Evaluating Large Vision-Language Models?
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, Feng Zhao
0
0
Large vision-language models (LVLMs) have recently achieved rapid progress, sparking numerous studies to evaluate their multi-modal capabilities. However, we dig into current evaluation works and identify two primary issues: 1) Visual content is unnecessary for many samples. The answers can be directly inferred from the questions and options, or the world knowledge embedded in LLMs. This phenomenon is prevalent across current benchmarks. For instance, GeminiPro achieves 42.9% on the MMMU benchmark without any visual input, and outperforms the random choice baseline across six benchmarks over 24% on average. 2) Unintentional data leakage exists in LLM and LVLM training. LLM and LVLM could still answer some visual-necessary questions without visual content, indicating the memorizing of these samples within large-scale training data. For example, Sphinx-X-MoE gets 43.6% on MMMU without accessing images, surpassing its LLM backbone with 17.9%. Both problems lead to misjudgments of actual multi-modal gains and potentially misguide the study of LVLM. To this end, we present MMStar, an elite vision-indispensable multi-modal benchmark comprising 1,500 samples meticulously selected by humans. MMStar benchmarks 6 core capabilities and 18 detailed axes, aiming to evaluate LVLMs' multi-modal capacities with carefully balanced and purified samples. These samples are first roughly selected from current benchmarks with an automated pipeline, human review is then involved to ensure each curated sample exhibits visual dependency, minimal data leakage, and requires advanced multi-modal capabilities. Moreover, two metrics are developed to measure data leakage and actual performance gain in multi-modal training. We evaluate 16 leading LVLMs on MMStar to assess their multi-modal capabilities, and on 7 benchmarks with the proposed metrics to investigate their data leakage and actual multi-modal gain.
4/10/2024

A Survey on Hallucination in Large Vision-Language Models
Hanchao Liu, Wenyuan Xue, Yifei Chen, Dapeng Chen, Xiutian Zhao, Ke Wang, Liping Hou, Rongjun Li, Wei Peng
0
0
Recent development of Large Vision-Language Models (LVLMs) has attracted growing attention within the AI landscape for its practical implementation potential. However, ``hallucination'', or more specifically, the misalignment between factual visual content and corresponding textual generation, poses a significant challenge of utilizing LVLMs. In this comprehensive survey, we dissect LVLM-related hallucinations in an attempt to establish an overview and facilitate future mitigation. Our scrutiny starts with a clarification of the concept of hallucinations in LVLMs, presenting a variety of hallucination symptoms and highlighting the unique challenges inherent in LVLM hallucinations. Subsequently, we outline the benchmarks and methodologies tailored specifically for evaluating hallucinations unique to LVLMs. Additionally, we delve into an investigation of the root causes of these hallucinations, encompassing insights from the training data and model components. We also critically review existing methods for mitigating hallucinations. The open questions and future directions pertaining to hallucinations within LVLMs are discussed to conclude this survey.
5/7/2024