ASR Error Correction using Large Language Models

0

Sign in to get full access
Overview
- Automatic speech recognition (ASR) systems often make mistakes, and correcting these errors is an important task.
- This paper explores using large language models (LLMs) to correct ASR errors.
- The researchers investigate different approaches, including supervised training and zero-shot prompting.
- The findings provide insights into the capabilities of LLMs for improving ASR accuracy.
Plain English Explanation
Speech recognition systems, which convert audio into text, can make mistakes. Correcting these errors is important for improving the quality of the transcripts. This paper looks at using large language models - powerful AI systems trained on vast amounts of text - to fix these mistakes.
The researchers tested different methods for using language models to correct ASR errors. In one approach, they trained the language model directly on transcripts with errors and their corrected versions. In another, they used the language model in a "zero-shot" way, where it was not explicitly trained on error correction, but could still identify and fix mistakes.
The results provide insight into the strengths and limitations of language models for this task. The models were able to significantly improve the accuracy of the speech transcripts, suggesting they could be a powerful tool for improving ASR. However, the paper also discusses some challenges and areas for further research.
Technical Explanation
The paper explores two main approaches for using large language models (LLMs) to correct errors in automatic speech recognition (ASR) transcripts:
-
Supervised Training: In this approach, the researchers fine-tuned the LLM on a dataset of ASR transcripts paired with their corrected versions. This allowed the model to learn the patterns of common ASR errors and how to fix them.
-
Zero-Shot Prompting: Here, the LLM was not explicitly trained on error correction. Instead, the researchers used natural language prompts to guide the model to identify and correct mistakes, leveraging its general language understanding capabilities.
The experiments were conducted on two English ASR datasets. The researchers evaluated the models' performance using metrics like word error rate (WER) reduction.
The results showed that both supervised training and zero-shot prompting could significantly improve ASR accuracy, reducing WER by over 20% in some cases. The paper provides insights into the strengths and limitations of each approach, as well as how factors like prompt design and dataset quality can impact performance.
Overall, the findings demonstrate the potential of large language models for ASR error correction, but also highlight areas for further research, such as improving the robustness of the correction process.
Critical Analysis
The paper presents a thorough exploration of using LLMs for ASR error correction and provides valuable insights. However, there are a few potential limitations and areas for further research:
-
Dataset Quality: The performance of the supervised training approach is heavily dependent on the quality and representativeness of the dataset used for fine-tuning. The paper acknowledges this and suggests that more robust data filtering techniques could be beneficial.
-
Generalization: While the zero-shot prompting approach shows promise, the paper does not fully explore the model's ability to generalize to a wide range of ASR errors and domains. Additional research is needed to understand the limits of this approach.
-
Multi-Modal Integration: The paper focuses solely on text-based error correction. Exploring ways to integrate visual, acoustic, or other modalities could potentially lead to further improvements in ASR accuracy.
-
Real-World Deployment: The paper evaluates the models on standard benchmarks, but more research is needed to understand their performance in real-world, production-level ASR systems, where factors like speaker diversity, background noise, and latency requirements may play a role.
Despite these potential areas for further investigation, the paper makes a valuable contribution to the field of ASR and demonstrates the promising capabilities of large language models for this task.
Conclusion
This paper presents an in-depth exploration of using large language models to correct errors in automatic speech recognition (ASR) transcripts. The researchers investigate two main approaches - supervised training and zero-shot prompting - and provide insights into the strengths and limitations of each.
The findings suggest that LLMs can significantly improve ASR accuracy, reducing word error rates by over 20% in some cases. This highlights the potential of these powerful language models for enhancing the quality and usability of speech recognition systems.
While the paper identifies areas for further research, such as improving dataset quality and exploring multimodal integration, it represents an important step forward in the field of ASR error correction. As language models continue to advance, their applications for improving speech recognition and other language-related tasks are likely to become increasingly valuable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ASR Error Correction using Large Language Models
Rao Ma, Mengjie Qian, Mark Gales, Kate Knill
Error correction (EC) models play a crucial role in refining Automatic Speech Recognition (ASR) transcriptions, enhancing the readability and quality of transcriptions. Without requiring access to the underlying code or model weights, EC can improve performance and provide domain adaptation for black-box ASR systems. This work investigates the use of large language models (LLMs) for error correction across diverse scenarios. 1-best ASR hypotheses are commonly used as the input to EC models. We propose building high-performance EC models using ASR N-best lists which should provide more contextual information for the correction process. Additionally, the generation process of a standard EC model is unrestricted in the sense that any output sequence can be generated. For some scenarios, such as unseen domains, this flexibility may impact performance. To address this, we introduce a constrained decoding approach based on the N-best list or an ASR lattice. Finally, most EC models are trained for a specific ASR system requiring retraining whenever the underlying ASR system is changed. This paper explores the ability of EC models to operate on the output of different ASR systems. This concept is further extended to zero-shot error correction using LLMs, such as ChatGPT. Experiments on three standard datasets demonstrate the efficacy of our proposed methods for both Transducer and attention-based encoder-decoder ASR systems. In addition, the proposed method can serve as an effective method for model ensembling.
Read more9/17/2024

0
Multi-stage Large Language Model Correction for Speech Recognition
Jie Pu, Thai-Son Nguyen, Sebastian Stuker
In this paper, we investigate the usage of large language models (LLMs) to improve the performance of competitive speech recognition systems. Different from previous LLM-based ASR error correction methods, we propose a novel multi-stage approach that utilizes uncertainty estimation of ASR outputs and reasoning capability of LLMs. Specifically, the proposed approach has two stages: the first stage is about ASR uncertainty estimation and exploits N-best list hypotheses to identify less reliable transcriptions; The second stage works on these identified transcriptions and performs LLM-based corrections. This correction task is formulated as a multi-step rule-based LLM reasoning process, which uses explicitly written rules in prompts to decompose the task into concrete reasoning steps. Our experimental results demonstrate the effectiveness of the proposed method by showing 10% ~ 20% relative improvement in WER over competitive ASR systems -- across multiple test domains and in zero-shot settings.
Read more6/18/2024

0
Full-text Error Correction for Chinese Speech Recognition with Large Language Model
Zhiyuan Tang, Dong Wang, Shen Huang, Shidong Shang
Large Language Models (LLMs) have demonstrated substantial potential for error correction in Automatic Speech Recognition (ASR). However, most research focuses on utterances from short-duration speech recordings, which are the predominant form of speech data for supervised ASR training. This paper investigates the effectiveness of LLMs for error correction in full-text generated by ASR systems from longer speech recordings, such as transcripts from podcasts, news broadcasts, and meetings. First, we develop a Chinese dataset for full-text error correction, named ChFT, utilizing a pipeline that involves text-to-speech synthesis, ASR, and error-correction pair extractor. This dataset enables us to correct errors across contexts, including both full-text and segment, and to address a broader range of error types, such as punctuation restoration and inverse text normalization, thus making the correction process comprehensive. Second, we fine-tune a pre-trained LLM on the constructed dataset using a diverse set of prompts and target formats, and evaluate its performance on full-text error correction. Specifically, we design prompts based on full-text and segment, considering various output formats, such as directly corrected text and JSON-based error-correction pairs. Through various test settings, including homogeneous, up-to-date, and hard test sets, we find that the fine-tuned LLMs perform well in the full-text setting with different prompts, each presenting its own strengths and weaknesses. This establishes a promising baseline for further research. The dataset is available on the website.
Read more9/14/2024
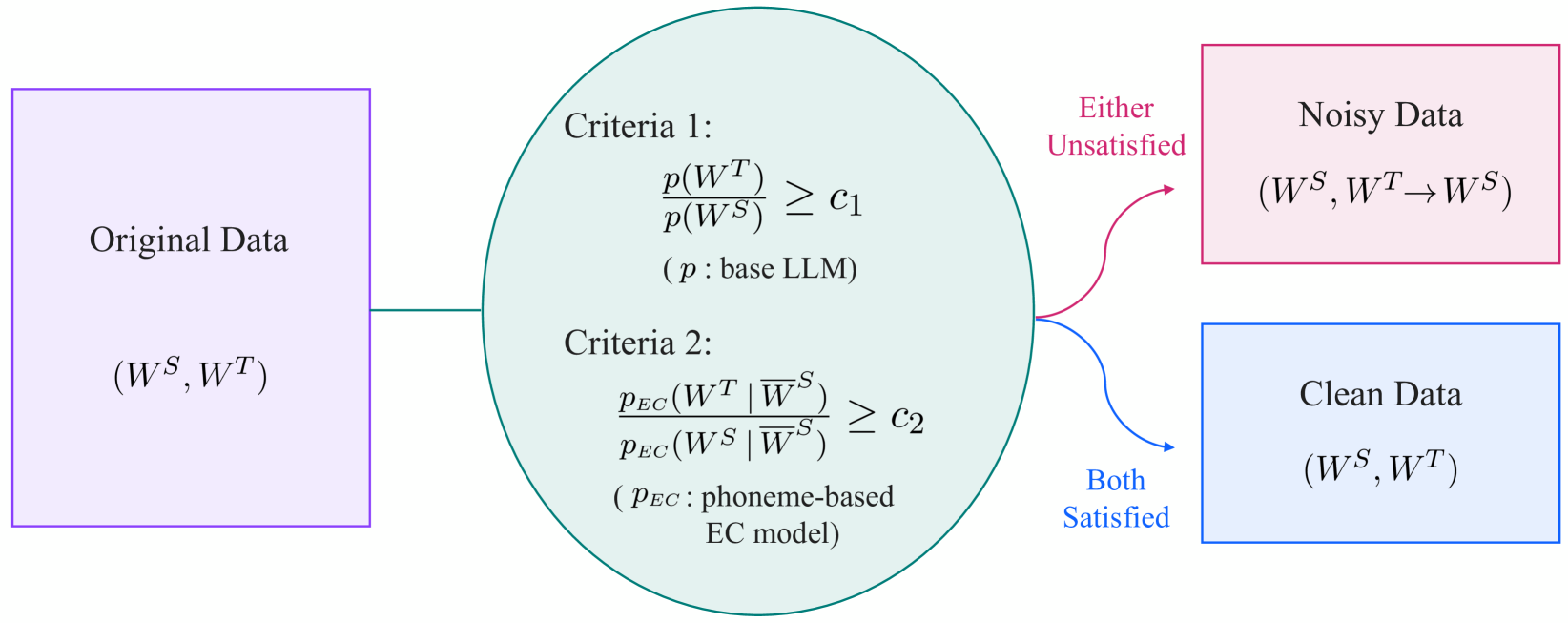
0
Robust ASR Error Correction with Conservative Data Filtering
Takuma Udagawa, Masayuki Suzuki, Masayasu Muraoka, Gakuto Kurata
Error correction (EC) based on large language models is an emerging technology to enhance the performance of automatic speech recognition (ASR) systems. Generally, training data for EC are collected by automatically pairing a large set of ASR hypotheses (as sources) and their gold references (as targets). However, the quality of such pairs is not guaranteed, and we observed various types of noise which can make the EC models brittle, e.g. inducing overcorrection in out-of-domain (OOD) settings. In this work, we propose two fundamental criteria that EC training data should satisfy: namely, EC targets should (1) improve linguistic acceptability over sources and (2) be inferable from the available context (e.g. source phonemes). Through these criteria, we identify low-quality EC pairs and train the models not to make any correction in such cases, the process we refer to as conservative data filtering. In our experiments, we focus on Japanese ASR using a strong Conformer-CTC as the baseline and finetune Japanese LLMs for EC. Through our evaluation on a suite of 21 internal benchmarks, we demonstrate that our approach can significantly reduce overcorrection and improve both the accuracy and quality of ASR results in the challenging OOD settings.
Read more7/19/2024