Robust ASR Error Correction with Conservative Data Filtering

0
Sign in to get full access
Overview
- This paper introduces a novel approach to improving the accuracy of automatic speech recognition (ASR) systems by leveraging conservative data filtering techniques.
- The proposed method aims to correct errors in the output of ASR systems, making the transcripts more reliable and useful for downstream applications.
- The researchers explore the use of various data filtering strategies to selectively include or exclude data samples during the training process, with the goal of enhancing the robustness of the ASR error correction model.
Plain English Explanation
The paper discusses a way to improve the accuracy of speech recognition systems, which are used to convert spoken words into text. The researchers developed a new method that focuses on correcting errors in the text output by these systems, making the transcripts more reliable and useful for other applications.
The key idea is to use a selective data filtering approach during the training of the error correction model. By carefully choosing which data samples to include or exclude, the researchers were able to make the model more robust and better able to handle errors in the speech recognition output.
This is important because speech recognition systems are not perfect and can sometimes make mistakes, resulting in inaccurate transcripts. By having a reliable error correction system in place, these mistakes can be caught and corrected, improving the overall quality of the transcripts and making them more useful for tasks like [internal link: https://aimodels.fyi/papers/arxiv/crossmodal-asr-error-correction-discrete-speech-units]cross-modal applications[/internal link], [internal link: https://aimodels.fyi/papers/arxiv/error-correction-by-paying-attention-to-both]error correction[/internal link], [internal link: https://aimodels.fyi/papers/arxiv/denoising-lm-pushing-limits-error-correction-models]language modeling[/internal link], and [internal link: https://aimodels.fyi/papers/arxiv/error-preserving-automatic-speech-recognition-young-english]speech recognition for non-native speakers[/internal link].
Technical Explanation
The paper presents a novel approach to improving the accuracy of ASR systems by developing a robust error correction model that leverages conservative data filtering techniques. The researchers explore various data filtering strategies, such as [internal link: https://aimodels.fyi/papers/arxiv/ag-lsec-audio-grounded-lexical-speaker-error]speaker-aware filtering[/internal link], to selectively include or exclude data samples during the training process.
The proposed method involves using a two-stage training process. In the first stage, the researchers train a base ASR model using a large corpus of speech data. In the second stage, they train an error correction model on the output of the base ASR model, using the conservative data filtering techniques to improve the model's ability to identify and correct errors.
The researchers evaluate the performance of their approach on several benchmark ASR datasets and compare it to various baseline methods. Their results demonstrate that the proposed conservative data filtering approach can significantly improve the accuracy of the ASR error correction model, outperforming other state-of-the-art techniques.
Critical Analysis
The paper presents a well-designed and thorough study, with a clear focus on improving the reliability of ASR systems through robust error correction. The researchers have explored a range of data filtering strategies and provided a comprehensive evaluation of their approach.
One potential limitation of the study is that it only considers a limited set of data filtering techniques. There may be other filtering strategies or combinations of approaches that could further enhance the performance of the error correction model. Additionally, the paper does not explore the computational complexity or inference time of the proposed method, which could be important considerations for real-world applications.
It would also be interesting to see how the error correction model performs on more diverse datasets, such as those with speakers from different backgrounds or in different acoustic environments. This could help to assess the generalizability of the approach and its ability to handle a wider range of ASR challenges.
Overall, the paper makes a valuable contribution to the field of ASR error correction and provides a solid foundation for further research in this area. The conservative data filtering techniques demonstrated in this study could be a promising direction for improving the reliability and usability of speech recognition systems.
Conclusion
This paper presents a novel approach to improving the accuracy of automatic speech recognition (ASR) systems by leveraging conservative data filtering techniques to train a robust error correction model. The proposed method aims to selectively include or exclude data samples during the training process, with the goal of enhancing the model's ability to identify and correct errors in the output of the base ASR system.
The researchers have demonstrated the effectiveness of their approach through extensive experiments on benchmark ASR datasets, showing that the conservative data filtering techniques can significantly improve the performance of the error correction model compared to other state-of-the-art methods. This work has important implications for the development of reliable and practical speech recognition systems, which are increasingly important for a wide range of applications, from [internal link: https://aimodels.fyi/papers/arxiv/crossmodal-asr-error-correction-discrete-speech-units]cross-modal tasks[/internal link] to [internal link: https://aimodels.fyi/papers/arxiv/error-correction-by-paying-attention-to-both]error correction[/internal link] and [internal link: https://aimodels.fyi/papers/arxiv/denoising-lm-pushing-limits-error-correction-models]language modeling[/internal link].
The insights and techniques presented in this paper provide a valuable contribution to the ongoing research efforts in the field of ASR error correction and could inspire further advancements in this important area of study.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Robust ASR Error Correction with Conservative Data Filtering
Takuma Udagawa, Masayuki Suzuki, Masayasu Muraoka, Gakuto Kurata
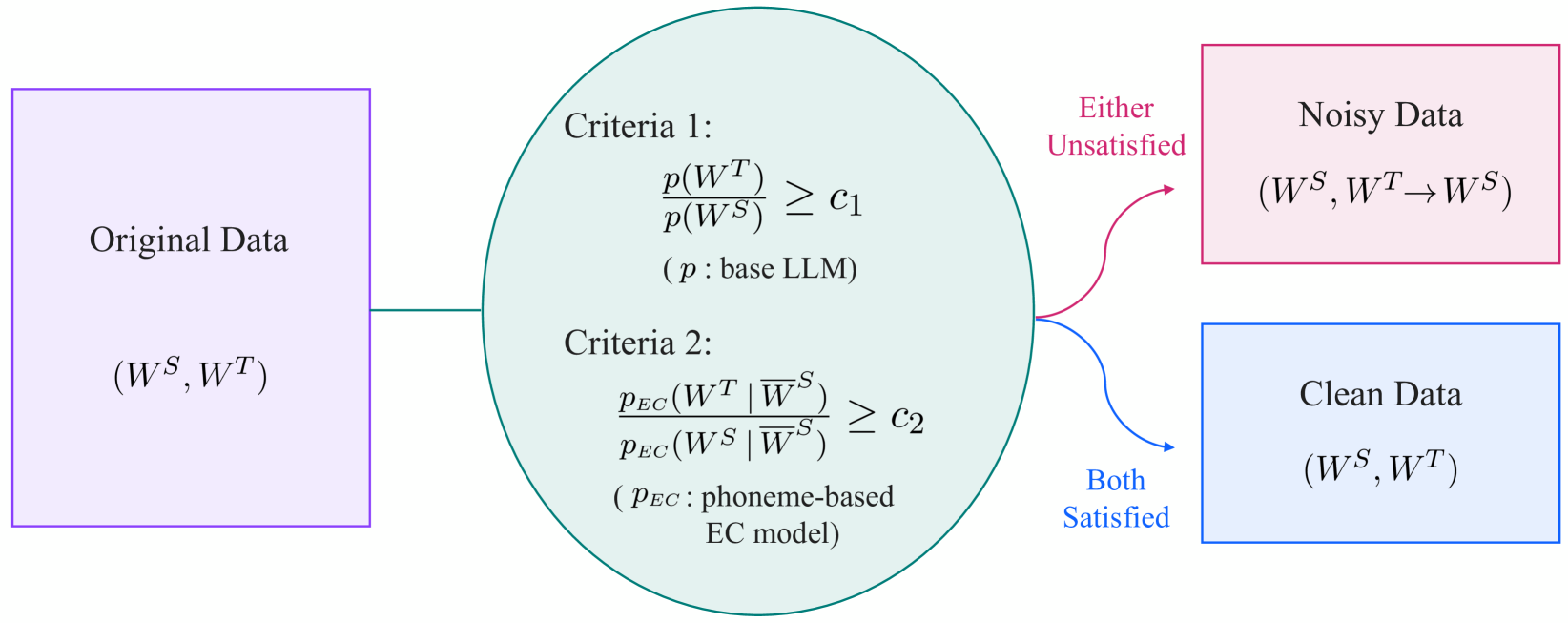
Error correction (EC) based on large language models is an emerging technology to enhance the performance of automatic speech recognition (ASR) systems. Generally, training data for EC are collected by automatically pairing a large set of ASR hypotheses (as sources) and their gold references (as targets). However, the quality of such pairs is not guaranteed, and we observed various types of noise which can make the EC models brittle, e.g. inducing overcorrection in out-of-domain (OOD) settings. In this work, we propose two fundamental criteria that EC training data should satisfy: namely, EC targets should (1) improve linguistic acceptability over sources and (2) be inferable from the available context (e.g. source phonemes). Through these criteria, we identify low-quality EC pairs and train the models not to make any correction in such cases, the process we refer to as conservative data filtering. In our experiments, we focus on Japanese ASR using a strong Conformer-CTC as the baseline and finetune Japanese LLMs for EC. Through our evaluation on a suite of 21 internal benchmarks, we demonstrate that our approach can significantly reduce overcorrection and improve both the accuracy and quality of ASR results in the challenging OOD settings.
Read more7/19/2024

0
New!ASR Error Correction using Large Language Models
Rao Ma, Mengjie Qian, Mark Gales, Kate Knill
Error correction (EC) models play a crucial role in refining Automatic Speech Recognition (ASR) transcriptions, enhancing the readability and quality of transcriptions. Without requiring access to the underlying code or model weights, EC can improve performance and provide domain adaptation for black-box ASR systems. This work investigates the use of large language models (LLMs) for error correction across diverse scenarios. 1-best ASR hypotheses are commonly used as the input to EC models. We propose building high-performance EC models using ASR N-best lists which should provide more contextual information for the correction process. Additionally, the generation process of a standard EC model is unrestricted in the sense that any output sequence can be generated. For some scenarios, such as unseen domains, this flexibility may impact performance. To address this, we introduce a constrained decoding approach based on the N-best list or an ASR lattice. Finally, most EC models are trained for a specific ASR system requiring retraining whenever the underlying ASR system is changed. This paper explores the ability of EC models to operate on the output of different ASR systems. This concept is further extended to zero-shot error correction using LLMs, such as ChatGPT. Experiments on three standard datasets demonstrate the efficacy of our proposed methods for both Transducer and attention-based encoder-decoder ASR systems. In addition, the proposed method can serve as an effective method for model ensembling.
Read more9/17/2024

0
Crossmodal ASR Error Correction with Discrete Speech Units
Yuanchao Li, Pinzhen Chen, Peter Bell, Catherine Lai
ASR remains unsatisfactory in scenarios where the speaking style diverges from that used to train ASR systems, resulting in erroneous transcripts. To address this, ASR Error Correction (AEC), a post-ASR processing approach, is required. In this work, we tackle an understudied issue: the Low-Resource Out-of-Domain (LROOD) problem, by investigating crossmodal AEC on very limited downstream data with 1-best hypothesis transcription. We explore pre-training and fine-tuning strategies and uncover an ASR domain discrepancy phenomenon, shedding light on appropriate training schemes for LROOD data. Moreover, we propose the incorporation of discrete speech units to align with and enhance the word embeddings for improving AEC quality. Results from multiple corpora and several evaluation metrics demonstrate the feasibility and efficacy of our proposed AEC approach on LROOD data as well as its generalizability and superiority on large-scale data. Finally, a study on speech emotion recognition confirms that our model produces ASR error-robust transcripts suitable for downstream applications.
Read more9/16/2024

0
Error Correction by Paying Attention to Both Acoustic and Confidence References for Automatic Speech Recognition
Yuchun Shu, Bo Hu, Yifeng He, Hao Shi, Longbiao Wang, Jianwu Dang
Accurately finding the wrong words in the automatic speech recognition (ASR) hypothesis and recovering them well-founded is the goal of speech error correction. In this paper, we propose a non-autoregressive speech error correction method. A Confidence Module measures the uncertainty of each word of the N-best ASR hypotheses as the reference to find the wrong word position. Besides, the acoustic feature from the ASR encoder is also used to provide the correct pronunciation references. N-best candidates from ASR are aligned using the edit path, to confirm each other and recover some missing character errors. Furthermore, the cross-attention mechanism fuses the information between error correction references and the ASR hypothesis. The experimental results show that both the acoustic and confidence references help with error correction. The proposed system reduces the error rate by 21% compared with the ASR model.
Read more7/19/2024