Assessing and Enhancing Large Language Models in Rare Disease Question-answering

0

Sign in to get full access
Overview
- ReDis-QA is a new dataset for evaluating large language models (LLMs) on rare disease diagnosis and question answering.
- The dataset contains over 20,000 rare disease-related questions and answers, sourced from medical experts and online forums.
- It is designed to test an LLM's ability to understand and reason about rare diseases, which are often underrepresented in existing medical datasets.
Plain English Explanation
ReDis-QA: A Rare Disease Dataset for LLM Diagnosis introduces a new dataset to help evaluate how well large language models (LLMs) can understand and diagnose rare medical conditions. Rare diseases are those that affect a small number of people, and they can be challenging for LLMs to learn about since there is less data available.
The ReDis-QA dataset contains over 20,000 questions and answers about rare diseases, collected from medical experts and online discussions. This allows researchers to test how well an LLM can answer questions, provide diagnoses, and reason about these uncommon conditions. By having a dedicated dataset focused on rare diseases, the authors aim to better understand the strengths and limitations of LLMs in the medical domain.
Technical Explanation
The ReDis-QA: A Rare Disease Dataset for LLM Diagnosis paper introduces a new dataset designed to evaluate the performance of large language models (LLMs) on rare disease diagnosis and question answering.
The dataset contains over 20,000 questions and answers related to rare diseases, sourced from medical experts, online forums, and other authoritative sources. The questions cover a wide range of rare disease topics, including symptoms, causes, treatments, and prognosis.
The authors structured the dataset to test an LLM's ability to understand the nuances of rare diseases, which are often underrepresented in existing medical datasets. By focusing on this important but understudied area, the ReDis-QA dataset aims to provide a more comprehensive evaluation of an LLM's medical reasoning and knowledge capabilities.
Critical Analysis
The ReDis-QA: A Rare Disease Dataset for LLM Diagnosis paper presents a valuable contribution to the field of medical language modeling. By creating a dataset focused on rare diseases, the authors address an important gap in existing benchmarks, which tend to emphasize more common conditions.
One potential limitation of the dataset is the reliance on online forums and other user-generated content, which may introduce noise or inaccuracies. The authors acknowledge this and note that they carefully curated the data to ensure quality. However, further validation of the dataset's accuracy and comprehensiveness could be beneficial.
Additionally, the paper does not provide extensive details on the demographic and geographic diversity of the dataset. Ensuring that the rare disease questions and answers reflect a wide range of patient backgrounds and experiences could enhance the dataset's utility for evaluating the fairness and inclusiveness of LLM-based medical systems.
Conclusion
The ReDis-QA: A Rare Disease Dataset for LLM Diagnosis paper introduces an important new dataset for evaluating the performance of large language models (LLMs) in the medical domain. By focusing on rare diseases, which are often underrepresented in existing benchmarks, the ReDis-QA dataset aims to provide a more comprehensive assessment of an LLM's ability to understand, diagnose, and reason about these challenging medical conditions.
The dataset's potential to drive advancements in LLM-based medical systems could have significant implications for improving rare disease diagnosis and care, ultimately benefiting patients and healthcare providers alike. As AI and language models become more integrated into the medical field, datasets like ReDis-QA will be crucial for ensuring that these technologies are effective, fair, and reliable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Assessing and Enhancing Large Language Models in Rare Disease Question-answering
Guanchu Wang, Junhao Ran, Ruixiang Tang, Chia-Yuan Chang, Chia-Yuan Chang, Yu-Neng Chuang, Zirui Liu, Vladimir Braverman, Zhandong Liu, Xia Hu
Despite the impressive capabilities of Large Language Models (LLMs) in general medical domains, questions remain about their performance in diagnosing rare diseases. To answer this question, we aim to assess the diagnostic performance of LLMs in rare diseases, and explore methods to enhance their effectiveness in this area. In this work, we introduce a rare disease question-answering (ReDis-QA) dataset to evaluate the performance of LLMs in diagnosing rare diseases. Specifically, we collected 1360 high-quality question-answer pairs within the ReDis-QA dataset, covering 205 rare diseases. Additionally, we annotated meta-data for each question, facilitating the extraction of subsets specific to any given disease and its property. Based on the ReDis-QA dataset, we benchmarked several open-source LLMs, revealing that diagnosing rare diseases remains a significant challenge for these models. To facilitate retrieval augmentation generation for rare disease diagnosis, we collect the first rare diseases corpus (ReCOP), sourced from the National Organization for Rare Disorders (NORD) database. Specifically, we split the report of each rare disease into multiple chunks, each representing a different property of the disease, including their overview, symptoms, causes, effects, related disorders, diagnosis, and standard therapies. This structure ensures that the information within each chunk aligns consistently with a question. Experiment results demonstrate that ReCOP can effectively improve the accuracy of LLMs on the ReDis-QA dataset by an average of 8%. Moreover, it significantly guides LLMs to generate trustworthy answers and explanations that can be traced back to existing literature.
Read more8/19/2024
0
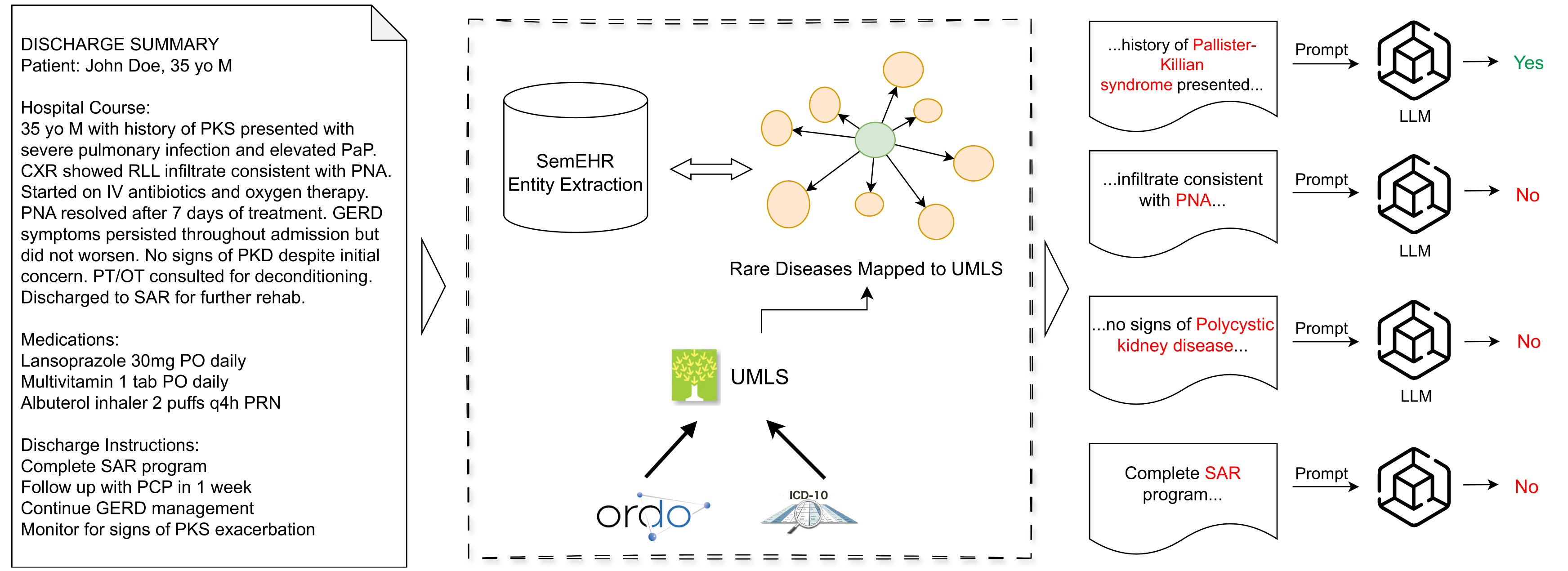
Retrieving and Refining: A Hybrid Framework with Large Language Models for Rare Disease Identification
Jinge Wu, Hang Dong, Zexi Li, Arijit Patra, Honghan Wu
The infrequency and heterogeneity of clinical presentations in rare diseases often lead to underdiagnosis and their exclusion from structured datasets. This necessitates the utilization of unstructured text data for comprehensive analysis. However, the manual identification from clinical reports is an arduous and intrinsically subjective task. This study proposes a novel hybrid approach that synergistically combines a traditional dictionary-based natural language processing (NLP) tool with the powerful capabilities of large language models (LLMs) to enhance the identification of rare diseases from unstructured clinical notes. We comprehensively evaluate various prompting strategies on six large language models (LLMs) of varying sizes and domains (general and medical). This evaluation encompasses zero-shot, few-shot, and retrieval-augmented generation (RAG) techniques to enhance the LLMs' ability to reason about and understand contextual information in patient reports. The results demonstrate effectiveness in rare disease identification, highlighting the potential for identifying underdiagnosed patients from clinical notes.
Read more5/20/2024
⛏️
0
RareBench: Can LLMs Serve as Rare Diseases Specialists?
Xuanzhong Chen, Xiaohao Mao, Qihan Guo, Lun Wang, Shuyang Zhang, Ting Chen
Generalist Large Language Models (LLMs), such as GPT-4, have shown considerable promise in various domains, including medical diagnosis. Rare diseases, affecting approximately 300 million people worldwide, often have unsatisfactory clinical diagnosis rates primarily due to a lack of experienced physicians and the complexity of differentiating among many rare diseases. In this context, recent news such as ChatGPT correctly diagnosed a 4-year-old's rare disease after 17 doctors failed underscore LLMs' potential, yet underexplored, role in clinically diagnosing rare diseases. To bridge this research gap, we introduce RareBench, a pioneering benchmark designed to systematically evaluate the capabilities of LLMs on 4 critical dimensions within the realm of rare diseases. Meanwhile, we have compiled the largest open-source dataset on rare disease patients, establishing a benchmark for future studies in this domain. To facilitate differential diagnosis of rare diseases, we develop a dynamic few-shot prompt methodology, leveraging a comprehensive rare disease knowledge graph synthesized from multiple knowledge bases, significantly enhancing LLMs' diagnostic performance. Moreover, we present an exhaustive comparative study of GPT-4's diagnostic capabilities against those of specialist physicians. Our experimental findings underscore the promising potential of integrating LLMs into the clinical diagnostic process for rare diseases. This paves the way for exciting possibilities in future advancements in this field.
Read more7/8/2024

0
Large Language Models for Disease Diagnosis: A Scoping Review
Shuang Zhou, Zidu Xu, Mian Zhang, Chunpu Xu, Yawen Guo, Zaifu Zhan, Sirui Ding, Jiashuo Wang, Kaishuai Xu, Yi Fang, Liqiao Xia, Jeremy Yeung, Daochen Zha, Genevieve B. Melton, Mingquan Lin, Rui Zhang
Automatic disease diagnosis has become increasingly valuable in clinical practice. The advent of large language models (LLMs) has catalyzed a paradigm shift in artificial intelligence, with growing evidence supporting the efficacy of LLMs in diagnostic tasks. Despite the increasing attention in this field, a holistic view is still lacking. Many critical aspects remain unclear, such as the diseases and clinical data to which LLMs have been applied, the LLM techniques employed, and the evaluation methods used. In this article, we perform a comprehensive review of LLM-based methods for disease diagnosis. Our review examines the existing literature across various dimensions, including disease types and associated clinical specialties, clinical data, LLM techniques, and evaluation methods. Additionally, we offer recommendations for applying and evaluating LLMs for diagnostic tasks. Furthermore, we assess the limitations of current research and discuss future directions. To our knowledge, this is the first comprehensive review for LLM-based disease diagnosis.
Read more9/20/2024