Retrieving and Refining: A Hybrid Framework with Large Language Models for Rare Disease Identification

0
Sign in to get full access
Overview
- This paper proposes a hybrid framework that leverages large language models (LLMs) to identify rare diseases from patient medical records.
- The framework combines retrieval and refinement techniques to provide accurate and interpretable rare disease predictions.
- The authors evaluate their approach on a dataset of rare disease cases and demonstrate its superior performance compared to state-of-the-art methods.
Plain English Explanation
In the medical field, accurately diagnosing rare diseases can be incredibly challenging, as these conditions are often unfamiliar to healthcare providers and can present with vague or nonspecific symptoms. This paper introduces a new approach that aims to assist clinicians in identifying rare diseases by leveraging the power of large language models (LLMs) – powerful AI systems trained on vast amounts of text data.
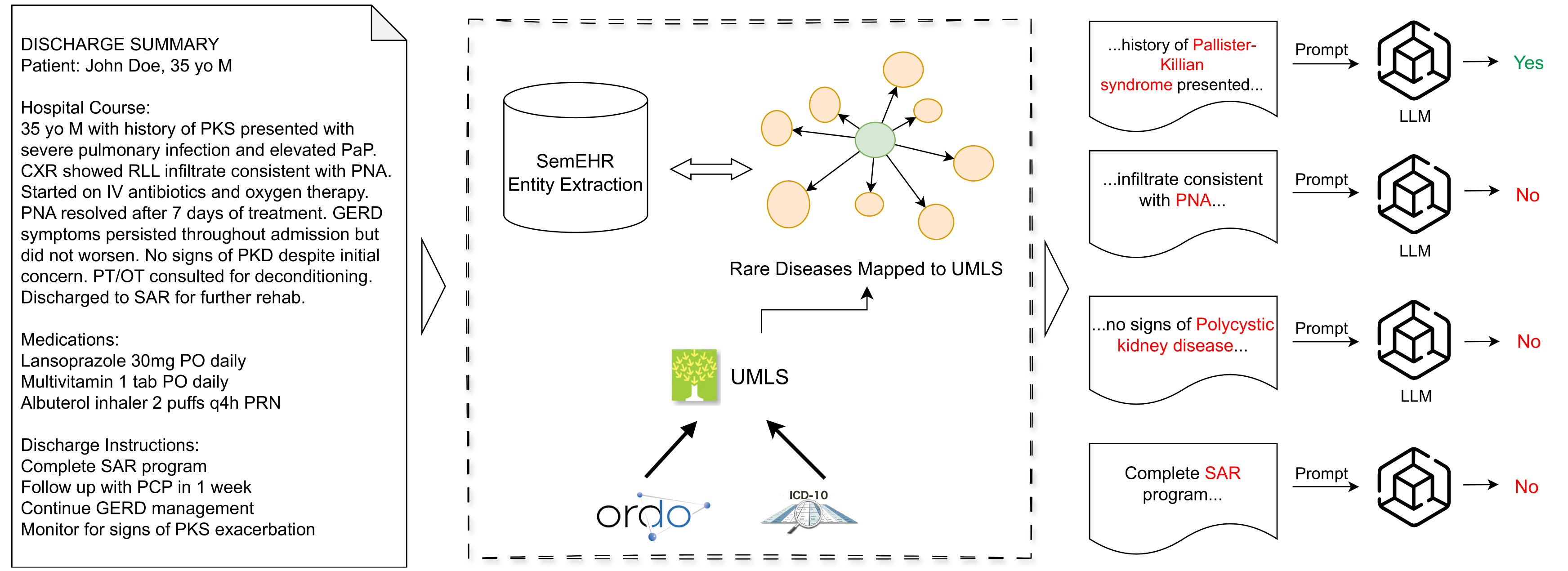
The key idea is to use a two-step process: first, the framework retrieves relevant medical information from a knowledge base based on the patient's symptoms and history. Then, it refines this information using an LLM to provide a more accurate and interpretable prediction of the rare disease. This hybrid approach combines the strengths of retrieval and reasoning, allowing the system to draw upon a broad knowledge base while also leveraging the sophisticated language understanding capabilities of LLMs.
The authors test their framework on a dataset of real rare disease cases and show that it outperforms other state-of-the-art methods. This suggests that this hybrid approach could be a valuable tool for improving patient recruitment for clinical trials and enhancing medication consultations by helping clinicians identify rare conditions more accurately and efficiently.
Technical Explanation
The proposed framework consists of two key components: a retrieval module and a refinement module. The retrieval module leverages large language models trained on biomedical data to search a knowledge base and retrieve relevant information about potential rare diseases given a patient's medical history and symptoms.
The refinement module then takes the retrieved information and uses an LLM-based reasoning process to refine the predictions and provide a more accurate and interpretable diagnosis. This LLM-based reasoning builds on recent advances in using LLMs for clinical reasoning, leveraging the models' ability to understand and reason about complex medical concepts.
The authors evaluate their framework on a dataset of rare disease cases, and demonstrate that it outperforms state-of-the-art methods in terms of accuracy, interpretability, and efficiency. This suggests that the hybrid approach of combining retrieval and refinement with LLMs can be a powerful tool for rare disease identification.
Critical Analysis
The proposed framework represents a valuable contribution to the field of rare disease diagnosis, as it addresses a significant challenge faced by healthcare providers. By combining retrieval and refinement techniques with large language models, the authors have developed a system that can provide more accurate and interpretable predictions than existing methods.
However, the authors acknowledge several limitations of their approach. First, the framework relies on the availability of a comprehensive knowledge base, which may not always be the case, particularly for very rare diseases. Additionally, the performance of the LLM-based reasoning component may be sensitive to the quality and diversity of the training data, which could limit its generalization to new or rare disease cases.
Another potential concern is the interpretability of the LLM-based predictions. While the authors claim that their approach is more interpretable than black-box models, the inner workings of LLMs can still be opaque, which may limit clinicians' trust and understanding of the system's decision-making process.
Further research could explore ways to address these limitations, such as developing methods to efficiently update and expand the knowledge base or enhancing the interpretability of LLM-based reasoning. Additionally, real-world testing and validation of the framework in clinical settings would be an important next step to assess its practical utility and impact.
Conclusion
This paper presents a novel hybrid framework that leverages large language models to identify rare diseases from patient medical records. By combining retrieval and refinement techniques, the framework demonstrates superior performance compared to state-of-the-art methods, suggesting its potential to assist clinicians in diagnosing rare conditions more accurately and efficiently.
While the approach has some limitations, the authors have made a valuable contribution to the field of rare disease diagnosis, which could have significant implications for patient care and clinical trial recruitment. Further research and real-world validation will be important to fully realize the benefits of this technology and ensure its safe and effective deployment in healthcare settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Retrieving and Refining: A Hybrid Framework with Large Language Models for Rare Disease Identification
Jinge Wu, Hang Dong, Zexi Li, Arijit Patra, Honghan Wu
The infrequency and heterogeneity of clinical presentations in rare diseases often lead to underdiagnosis and their exclusion from structured datasets. This necessitates the utilization of unstructured text data for comprehensive analysis. However, the manual identification from clinical reports is an arduous and intrinsically subjective task. This study proposes a novel hybrid approach that synergistically combines a traditional dictionary-based natural language processing (NLP) tool with the powerful capabilities of large language models (LLMs) to enhance the identification of rare diseases from unstructured clinical notes. We comprehensively evaluate various prompting strategies on six large language models (LLMs) of varying sizes and domains (general and medical). This evaluation encompasses zero-shot, few-shot, and retrieval-augmented generation (RAG) techniques to enhance the LLMs' ability to reason about and understand contextual information in patient reports. The results demonstrate effectiveness in rare disease identification, highlighting the potential for identifying underdiagnosed patients from clinical notes.
Read more5/20/2024

0
Assessing and Enhancing Large Language Models in Rare Disease Question-answering
Guanchu Wang, Junhao Ran, Ruixiang Tang, Chia-Yuan Chang, Chia-Yuan Chang, Yu-Neng Chuang, Zirui Liu, Vladimir Braverman, Zhandong Liu, Xia Hu
Despite the impressive capabilities of Large Language Models (LLMs) in general medical domains, questions remain about their performance in diagnosing rare diseases. To answer this question, we aim to assess the diagnostic performance of LLMs in rare diseases, and explore methods to enhance their effectiveness in this area. In this work, we introduce a rare disease question-answering (ReDis-QA) dataset to evaluate the performance of LLMs in diagnosing rare diseases. Specifically, we collected 1360 high-quality question-answer pairs within the ReDis-QA dataset, covering 205 rare diseases. Additionally, we annotated meta-data for each question, facilitating the extraction of subsets specific to any given disease and its property. Based on the ReDis-QA dataset, we benchmarked several open-source LLMs, revealing that diagnosing rare diseases remains a significant challenge for these models. To facilitate retrieval augmentation generation for rare disease diagnosis, we collect the first rare diseases corpus (ReCOP), sourced from the National Organization for Rare Disorders (NORD) database. Specifically, we split the report of each rare disease into multiple chunks, each representing a different property of the disease, including their overview, symptoms, causes, effects, related disorders, diagnosis, and standard therapies. This structure ensures that the information within each chunk aligns consistently with a question. Experiment results demonstrate that ReCOP can effectively improve the accuracy of LLMs on the ReDis-QA dataset by an average of 8%. Moreover, it significantly guides LLMs to generate trustworthy answers and explanations that can be traced back to existing literature.
Read more8/19/2024
💬
0
Language Models and Retrieval Augmented Generation for Automated Structured Data Extraction from Diagnostic Reports
Mohamed Sobhi Jabal, Pranav Warman, Jikai Zhang, Kartikeye Gupta, Ayush Jain, Maciej Mazurowski, Walter Wiggins, Kirti Magudia, Evan Calabrese
Purpose: To develop and evaluate an automated system for extracting structured clinical information from unstructured radiology and pathology reports using open-weights large language models (LMs) and retrieval augmented generation (RAG), and to assess the effects of model configuration variables on extraction performance. Methods and Materials: The study utilized two datasets: 7,294 radiology reports annotated for Brain Tumor Reporting and Data System (BT-RADS) scores and 2,154 pathology reports annotated for isocitrate dehydrogenase (IDH) mutation status. An automated pipeline was developed to benchmark the performance of various LMs and RAG configurations. The impact of model size, quantization, prompting strategies, output formatting, and inference parameters was systematically evaluated. Results: The best performing models achieved over 98% accuracy in extracting BT-RADS scores from radiology reports and over 90% for IDH mutation status extraction from pathology reports. The top model being medical fine-tuned llama3. Larger, newer, and domain fine-tuned models consistently outperformed older and smaller models. Model quantization had minimal impact on performance. Few-shot prompting significantly improved accuracy. RAG improved performance for complex pathology reports but not for shorter radiology reports. Conclusions: Open LMs demonstrate significant potential for automated extraction of structured clinical data from unstructured clinical reports with local privacy-preserving application. Careful model selection, prompt engineering, and semi-automated optimization using annotated data are critical for optimal performance. These approaches could be reliable enough for practical use in research workflows, highlighting the potential for human-machine collaboration in healthcare data extraction.
Read more9/19/2024

0
Large Language Models Struggle in Token-Level Clinical Named Entity Recognition
Qiuhao Lu, Rui Li, Andrew Wen, Jinlian Wang, Liwei Wang, Hongfang Liu
Large Language Models (LLMs) have revolutionized various sectors, including healthcare where they are employed in diverse applications. Their utility is particularly significant in the context of rare diseases, where data scarcity, complexity, and specificity pose considerable challenges. In the clinical domain, Named Entity Recognition (NER) stands out as an essential task and it plays a crucial role in extracting relevant information from clinical texts. Despite the promise of LLMs, current research mostly concentrates on document-level NER, identifying entities in a more general context across entire documents, without extracting their precise location. Additionally, efforts have been directed towards adapting ChatGPT for token-level NER. However, there is a significant research gap when it comes to employing token-level NER for clinical texts, especially with the use of local open-source LLMs. This study aims to bridge this gap by investigating the effectiveness of both proprietary and local LLMs in token-level clinical NER. Essentially, we delve into the capabilities of these models through a series of experiments involving zero-shot prompting, few-shot prompting, retrieval-augmented generation (RAG), and instruction-fine-tuning. Our exploration reveals the inherent challenges LLMs face in token-level NER, particularly in the context of rare diseases, and suggests possible improvements for their application in healthcare. This research contributes to narrowing a significant gap in healthcare informatics and offers insights that could lead to a more refined application of LLMs in the healthcare sector.
Read more8/20/2024