Assessing the Level of Toxicity Against Distinct Groups in Bangla Social Media Comments: A Comprehensive Investigation

0

Sign in to get full access
Overview
- Examines the level of toxicity in Bangla social media comments towards different demographic groups
- Aims to develop a comprehensive framework for identifying and analyzing toxic content
- Utilizes machine learning models to detect and assess toxicity across various target groups
Plain English Explanation
This research paper focuses on assessing the level of toxicity in Bangla social media comments towards different demographic groups. The goal is to develop a comprehensive framework for identifying and analyzing toxic content online.
The researchers use machine learning models to detect and assess the toxicity of comments across various target groups, such as by gender, age, religion, and ethnicity. This allows them to better understand the prevalence and patterns of toxic behavior directed at specific communities.
By mapping the landscape of online violence and analyzing toxicity across different topics, the researchers aim to provide insights that can inform the development of more effective moderation tools and policies to address hateful and toxic content on social media platforms.
Technical Explanation
The researchers first collected a large dataset of Bangla social media comments from various online platforms. They then developed machine learning models to automatically detect and classify the level of toxicity in each comment, based on the presence of hateful, abusive, or discriminatory language.
The models were trained on a demographically-enriched dataset that included information about the target of the toxic content, such as gender, age, religion, and ethnicity. This allowed the researchers to analyze the toxicity levels directed towards different demographic groups.
The researchers used a variety of techniques, including natural language processing and deep learning architectures, to build robust models for identifying and quantifying the toxicity in the Bangla social media comments.
Critical Analysis
While the research provides valuable insights into the patterns of toxic behavior on Bangla social media, it is important to note that the dataset and models used in the study may have inherent biases or limitations. The researchers acknowledge that their approach may not capture the full complexity of online toxicity, and they encourage further research to validate and build upon their findings.
Additionally, the ethical implications of this type of research should be carefully considered, as the identification and categorization of toxic content can have significant impacts on the affected communities. The researchers emphasize the need for responsible and transparent development and deployment of such tools to ensure they are not misused or abused.
Conclusion
This research represents an important step in understanding and addressing the problem of online toxicity, particularly in the context of Bangla social media. By developing a comprehensive framework for detecting and analyzing toxic content, the researchers provide valuable insights that can inform the development of more effective moderation strategies and policies. However, further research and careful consideration of the ethical implications are necessary to ensure that these tools are used responsibly and effectively to create safer and more inclusive online spaces.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Assessing the Level of Toxicity Against Distinct Groups in Bangla Social Media Comments: A Comprehensive Investigation
Mukaffi Bin Moin, Pronay Debnath, Usafa Akther Rifa, Rijeet Bin Anis
Social media platforms have a vital role in the modern world, serving as conduits for communication, the exchange of ideas, and the establishment of networks. However, the misuse of these platforms through toxic comments, which can range from offensive remarks to hate speech, is a concerning issue. This study focuses on identifying toxic comments in the Bengali language targeting three specific groups: transgender people, indigenous people, and migrant people, from multiple social media sources. The study delves into the intricate process of identifying and categorizing toxic language while considering the varying degrees of toxicity: high, medium, and low. The methodology involves creating a dataset, manual annotation, and employing pre-trained transformer models like Bangla-BERT, bangla-bert-base, distil-BERT, and Bert-base-multilingual-cased for classification. Diverse assessment metrics such as accuracy, recall, precision, and F1-score are employed to evaluate the model's effectiveness. The experimental findings reveal that Bangla-BERT surpasses alternative models, achieving an F1-score of 0.8903. This research exposes the complexity of toxicity in Bangla social media dialogues, revealing its differing impacts on diverse demographic groups.
Read more9/26/2024
🐍
0
Mapping Violence: Developing an Extensive Framework to Build a Bangla Sectarian Expression Dataset from Social Media Interactions
Nazia Tasnim, Sujan Sen Gupta, Md. Istiak Hossain Shihab, Fatiha Islam Juee, Arunima Tahsin, Pritom Ghum, Kanij Fatema, Marshia Haque, Wasema Farzana, Prionti Nasir, Ashique KhudaBukhsh, Farig Sadeque, Asif Sushmit
Communal violence in online forums has become extremely prevalent in South Asia, where many communities of different cultures coexist and share resources. These societies exhibit a phenomenon characterized by strong bonds within their own groups and animosity towards others, leading to conflicts that frequently escalate into violent confrontations. To address this issue, we have developed the first comprehensive framework for the automatic detection of communal violence markers in online Bangla content accompanying the largest collection (13K raw sentences) of social media interactions that fall under the definition of four major violence class and their 16 coarse expressions. Our workflow introduces a 7-step expert annotation process incorporating insights from social scientists, linguists, and psychologists. By presenting data statistics and benchmarking performance using this dataset, we have determined that, aside from the category of Non-communal violence, Religio-communal violence is particularly pervasive in Bangla text. Moreover, we have substantiated the effectiveness of fine-tuning language models in identifying violent comments by conducting preliminary benchmarking on the state-of-the-art Bangla deep learning model.
Read more4/19/2024

0
Deciphering Hate: Identifying Hateful Memes and Their Targets
Eftekhar Hossain, Omar Sharif, Mohammed Moshiul Hoque, Sarah M. Preum
Internet memes have become a powerful means for individuals to express emotions, thoughts, and perspectives on social media. While often considered as a source of humor and entertainment, memes can also disseminate hateful content targeting individuals or communities. Most existing research focuses on the negative aspects of memes in high-resource languages, overlooking the distinctive challenges associated with low-resource languages like Bengali (also known as Bangla). Furthermore, while previous work on Bengali memes has focused on detecting hateful memes, there has been no work on detecting their targeted entities. To bridge this gap and facilitate research in this arena, we introduce a novel multimodal dataset for Bengali, BHM (Bengali Hateful Memes). The dataset consists of 7,148 memes with Bengali as well as code-mixed captions, tailored for two tasks: (i) detecting hateful memes, and (ii) detecting the social entities they target (i.e., Individual, Organization, Community, and Society). To solve these tasks, we propose DORA (Dual cO attention fRAmework), a multimodal deep neural network that systematically extracts the significant modality features from the memes and jointly evaluates them with the modality-specific features to understand the context better. Our experiments show that DORA is generalizable on other low-resource hateful meme datasets and outperforms several state-of-the-art rivaling baselines.
Read more9/24/2024
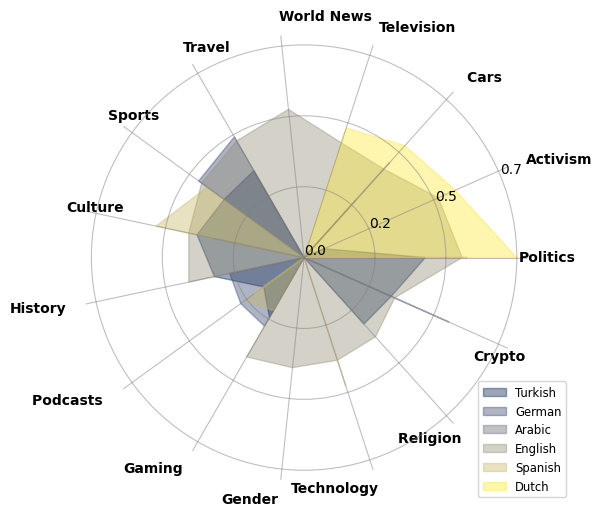
0
The Constant in HATE: Analyzing Toxicity in Reddit across Topics and Languages
Wondimagegnhue Tsegaye Tufa, Ilia Markov, Piek Vossen
Toxic language remains an ongoing challenge on social media platforms, presenting significant issues for users and communities. This paper provides a cross-topic and cross-lingual analysis of toxicity in Reddit conversations. We collect 1.5 million comment threads from 481 communities in six languages: English, German, Spanish, Turkish,Arabic, and Dutch, covering 80 topics such as Culture, Politics, and News. We thoroughly analyze how toxicity spikes within different communities in relation to specific topics. We observe consistent patterns of increased toxicity across languages for certain topics, while also noting significant variations within specific language communities.
Read more4/30/2024