AssistantBench: Can Web Agents Solve Realistic and Time-Consuming Tasks?

0

Sign in to get full access
Overview
- The provided paper investigates whether web agents can solve realistic and time-consuming tasks.
- It introduces a new benchmark called AssistantBench to evaluate the capabilities of web agents.
- The paper compares the performance of different web agents on a range of tasks and provides insights into their strengths and limitations.
Plain English Explanation
The research paper examines whether AI agents, or "web agents," can effectively complete practical and time-intensive tasks on the internet. The researchers developed a new testing framework called AssistantBench to assess the capabilities of these agents.
The key idea is to see how well web agents can perform real-world tasks that would typically require human effort, such as online research, writing, and problem-solving. This is an important question, as developing AI systems that can autonomously navigate and interact with the web could lead to significant productivity gains and new applications.
The paper compares the performance of different web agent models on a variety of AssistantBench tasks. This allows the researchers to identify the strengths and weaknesses of current web agent technology. For example, the agents may excel at rapid information lookup but struggle with more open-ended problem-solving.
Overall, the AssistantBench framework provides a way to rigorously evaluate the real-world capabilities of web agents and chart progress in this important area of AI research.
Technical Explanation
The AssistantBench benchmark consists of a suite of tasks that assess a web agent's ability to perform practical, time-consuming activities on the internet. These tasks span a range of domains, including information lookup, writing, math problem-solving, and open-ended reasoning.
To test web agents, the researchers developed a simulated web environment that mimics realistic web browsing and interaction. This includes challenges like dealing with noisy or incomplete information, navigating between pages, and handling unexpected situations.
The paper evaluates the performance of several different web agent models on the AssistantBench tasks. These models vary in their underlying architectures, training approaches, and capabilities. The results provide insights into the strengths and limitations of current web agent technology.
For example, the agents may excel at rapid information retrieval but struggle with more open-ended problem-solving that requires reasoning across multiple sources. The paper also identifies areas where web agents could benefit from further research and development, such as improving their ability to handle unexpected situations and maintain contextual awareness across extended tasks.
Critical Analysis
The AssistantBench framework represents an important step in evaluating the real-world capabilities of web agents. By simulating a realistic web environment and assessing agents on practical, time-consuming tasks, the researchers are able to uncover valuable insights that go beyond traditional AI benchmarks.
However, the paper also acknowledges several limitations of the current study. For instance, the simulated web environment may not fully capture the complexity and unpredictability of the actual internet. Additionally, the set of tasks, while diverse, may not be comprehensive enough to fully characterize an agent's web-based capabilities.
Further research could explore ways to make the simulated environment even more realistic, perhaps by incorporating more dynamic and adversarial elements. Expanding the range of tasks, or even allowing agents to propose their own tasks, could also lead to a more comprehensive understanding of their abilities.
Additionally, the paper does not delve deeply into the ethical implications of developing highly capable web agents. As these systems become more advanced, it will be crucial to consider potential issues around privacy, bias, and the displacement of human labor.
Conclusion
The AssistantBench framework represents an important step forward in evaluating the real-world capabilities of web agents. By testing these agents on practical, time-consuming tasks within a simulated web environment, the researchers are able to gain valuable insights into the strengths and limitations of current technology.
The findings suggest that while web agents can excel at certain tasks, such as rapid information retrieval, they still struggle with more open-ended problem-solving and maintaining contextual awareness over extended interactions. Continued research and development in this area could lead to significant productivity gains and new applications, but it will also require careful consideration of the ethical implications.
Overall, the AssistantBench benchmark provides a valuable tool for tracking the progress of web agent technology and identifying key areas for future improvement.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AssistantBench: Can Web Agents Solve Realistic and Time-Consuming Tasks?
Ori Yoran, Samuel Joseph Amouyal, Chaitanya Malaviya, Ben Bogin, Ofir Press, Jonathan Berant
Language agents, built on top of language models (LMs), are systems that can interact with complex environments, such as the open web. In this work, we examine whether such agents can perform realistic and time-consuming tasks on the web, e.g., monitoring real-estate markets or locating relevant nearby businesses. We introduce AssistantBench, a challenging new benchmark consisting of 214 realistic tasks that can be automatically evaluated, covering different scenarios and domains. We find that AssistantBench exposes the limitations of current systems, including language models and retrieval-augmented language models, as no model reaches an accuracy of more than 25 points. While closed-book LMs perform well, they exhibit low precision since they tend to hallucinate facts. State-of-the-art web agents reach a score of near zero. Additionally, we introduce SeePlanAct (SPA), a new web agent that significantly outperforms previous agents, and an ensemble of SPA and closed-book models reaches the best overall performance. Moreover, we analyze failures of current systems and highlight that web navigation remains a major challenge.
Read more7/23/2024
⚙️
0
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, Graham Neubig
With advances in generative AI, there is now potential for autonomous agents to manage daily tasks via natural language commands. However, current agents are primarily created and tested in simplified synthetic environments, leading to a disconnect with real-world scenarios. In this paper, we build an environment for language-guided agents that is highly realistic and reproducible. Specifically, we focus on agents that perform tasks on the web, and create an environment with fully functional websites from four common domains: e-commerce, social forum discussions, collaborative software development, and content management. Our environment is enriched with tools (e.g., a map) and external knowledge bases (e.g., user manuals) to encourage human-like task-solving. Building upon our environment, we release a set of benchmark tasks focusing on evaluating the functional correctness of task completions. The tasks in our benchmark are diverse, long-horizon, and designed to emulate tasks that humans routinely perform on the internet. We experiment with several baseline agents, integrating recent techniques such as reasoning before acting. The results demonstrate that solving complex tasks is challenging: our best GPT-4-based agent only achieves an end-to-end task success rate of 14.41%, significantly lower than the human performance of 78.24%. These results highlight the need for further development of robust agents, that current state-of-the-art large language models are far from perfect performance in these real-life tasks, and that WebArena can be used to measure such progress.
Read more4/17/2024
💬
0
Large Language Models Can Self-Improve At Web Agent Tasks
Ajay Patel, Markus Hofmarcher, Claudiu Leoveanu-Condrei, Marius-Constantin Dinu, Chris Callison-Burch, Sepp Hochreiter
Training models to act as agents that can effectively navigate and perform actions in a complex environment, such as a web browser, has typically been challenging due to lack of training data. Large language models (LLMs) have recently demonstrated some capability to navigate novel environments as agents in a zero-shot or few-shot fashion, purely guided by natural language instructions as prompts. Recent research has also demonstrated LLMs have the capability to exceed their base performance through self-improvement, i.e. fine-tuning on data generated by the model itself. In this work, we explore the extent to which LLMs can self-improve their performance as agents in long-horizon tasks in a complex environment using the WebArena benchmark. In WebArena, an agent must autonomously navigate and perform actions on web pages to achieve a specified objective. We explore fine-tuning on three distinct synthetic training data mixtures and achieve a 31% improvement in task completion rate over the base model on the WebArena benchmark through a self-improvement procedure. We additionally contribute novel evaluation metrics for assessing the performance, robustness, capabilities, and quality of trajectories of our fine-tuned agent models to a greater degree than simple, aggregate-level benchmark scores currently used to measure self-improvement.
Read more5/31/2024
0
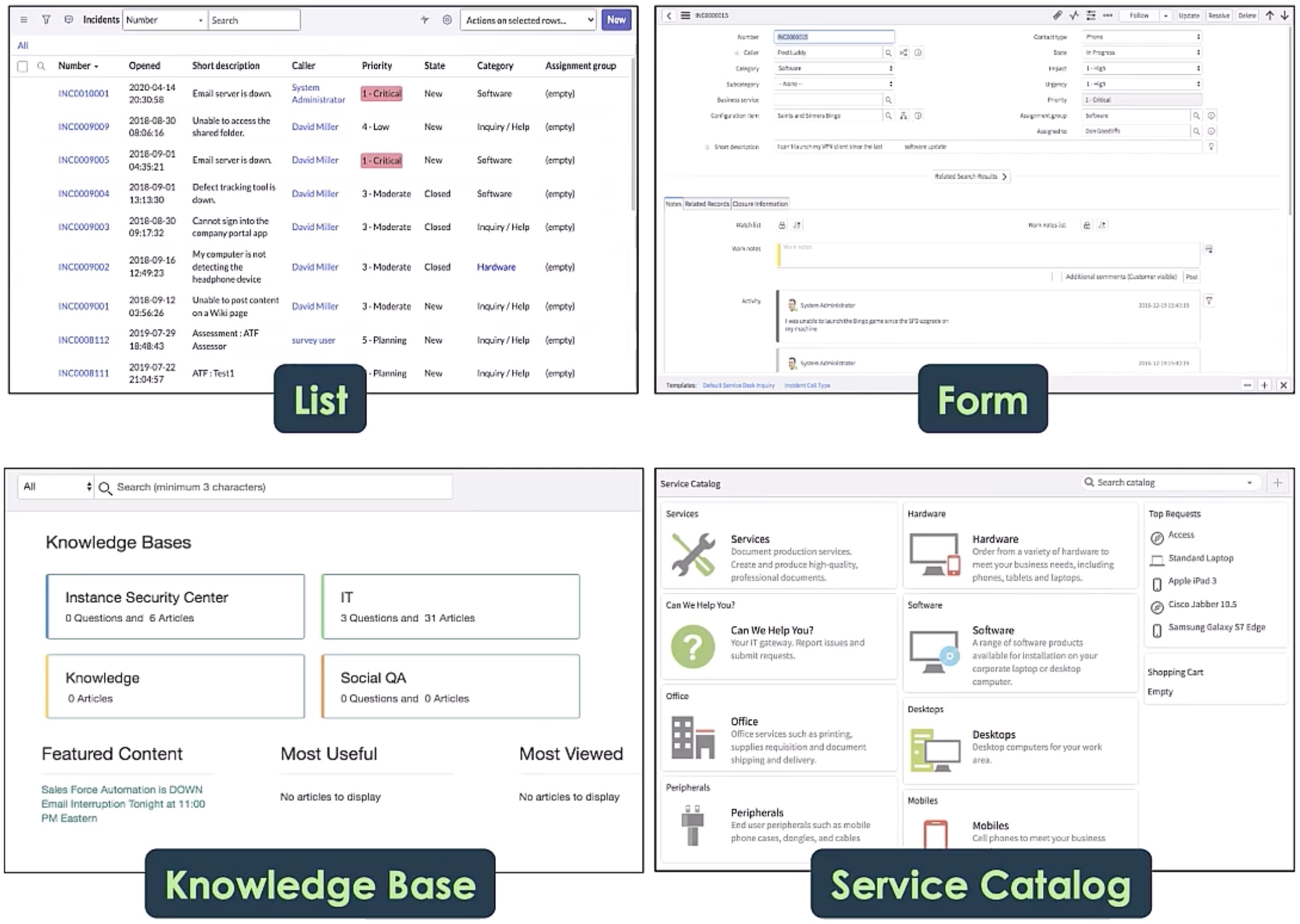
WorkArena: How Capable Are Web Agents at Solving Common Knowledge Work Tasks?
Alexandre Drouin, Maxime Gasse, Massimo Caccia, Issam H. Laradji, Manuel Del Verme, Tom Marty, L'eo Boisvert, Megh Thakkar, Quentin Cappart, David Vazquez, Nicolas Chapados, Alexandre Lacoste
We study the use of large language model-based agents for interacting with software via web browsers. Unlike prior work, we focus on measuring the agents' ability to perform tasks that span the typical daily work of knowledge workers utilizing enterprise software systems. To this end, we propose WorkArena, a remote-hosted benchmark of 33 tasks based on the widely-used ServiceNow platform. We also introduce BrowserGym, an environment for the design and evaluation of such agents, offering a rich set of actions as well as multimodal observations. Our empirical evaluation reveals that while current agents show promise on WorkArena, there remains a considerable gap towards achieving full task automation. Notably, our analysis uncovers a significant performance disparity between open and closed-source LLMs, highlighting a critical area for future exploration and development in the field.
Read more7/24/2024