Associate Everything Detected: Facilitating Tracking-by-Detection to the Unknown

0
Sign in to get full access
Overview
- Novel multi-object tracking approach that associates all detected objects, even those without prior knowledge
- Leverages attention mechanism to dynamically learn associations between objects
- Facilitates tracking-by-detection in scenarios with unknown objects
Plain English Explanation
In this paper, the researchers present a new way to track multiple objects, even if some of those objects are unknown or have never been seen before. Traditional multi-object tracking systems rely on having prior information about the objects they're trying to track. But in the real world, there are often new or unfamiliar objects that the system hasn't been trained on.
The researchers' approach, called "Associate Everything Detected" (AED), gets around this limitation by using an attention mechanism to dynamically learn associations between all the detected objects, regardless of whether they're familiar or not. The attention mechanism allows the system to focus on the relevant features and relationships between objects, rather than just relying on pre-defined object categories.
This makes AED more flexible and robust for real-world tracking scenarios where the set of objects being tracked can change or include unknown elements. By associating everything that's detected, the system is able to facilitate "tracking-by-detection" - keeping track of objects just based on detecting them, without needing to know what they are ahead of time.
Technical Explanation
The key innovation in the AED approach is the use of an attention mechanism to dynamically learn associations between detected objects, even those that are unfamiliar or unknown.
Rather than relying on predefined object categories or appearance models, the attention module allows the system to focus on the relevant visual and spatial features that can link detections together over time. This enables "tracking-by-detection" - keeping track of objects just based on detecting them, without needing to know what they are in advance.
The researchers evaluate AED on several multi-object tracking benchmarks, including scenarios with unknown objects. They find that AED outperforms prior state-of-the-art methods, particularly in these more challenging open-vocabulary settings. The attention-based association strategy allows AED to effectively handle a mix of known and unknown objects.
Critical Analysis
One potential limitation of the AED approach is that it still relies on having a robust object detection system to identify all the relevant objects in the first place. If the detection module misses or mislabels certain objects, that could negatively impact the tracking performance, even with the advanced association capabilities.
Additionally, while the attention mechanism provides flexibility for handling unknown objects, it's not clear how well the system would scale to very large and diverse object sets. The paper only evaluates on a few benchmark datasets - further research would be needed to understand AED's limitations at larger scales.
Overall, the AED framework represents an interesting and promising direction for advancing multi-object tracking, particularly in real-world settings with unknown elements. But as with any research, there are still open questions and areas for further exploration.
Conclusion
The "Associate Everything Detected" (AED) approach introduced in this paper advances the state-of-the-art in multi-object tracking by enabling effective "tracking-by-detection" even when some of the tracked objects are unfamiliar or unknown.
By leveraging an attention mechanism to dynamically learn object associations, AED overcomes the limitations of traditional tracking systems that rely on predefined object categories or appearance models. This flexibility makes AED more robust for real-world applications where the set of tracked objects can be unpredictable or change over time.
While there are still some open challenges, the strong performance of AED on benchmark evaluations suggests it represents an important step forward in making multi-object tracking systems more capable and adaptable to the complexities of the physical world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Associate Everything Detected: Facilitating Tracking-by-Detection to the Unknown
Zimeng Fang, Chao Liang, Xue Zhou, Shuyuan Zhu, Xi Li
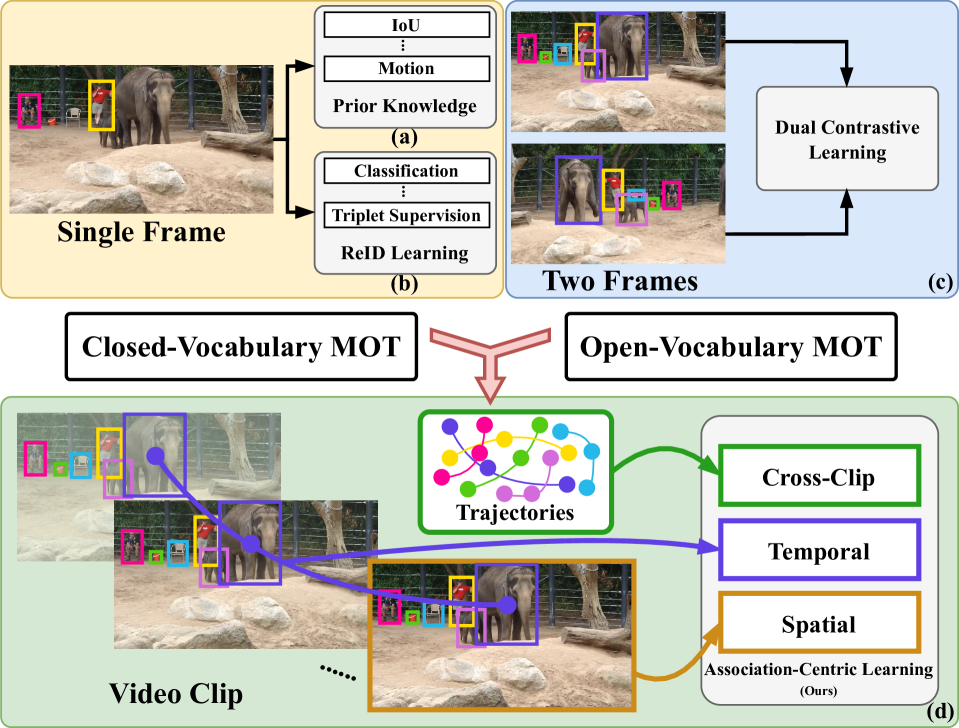
Multi-object tracking (MOT) emerges as a pivotal and highly promising branch in the field of computer vision. Classical closed-vocabulary MOT (CV-MOT) methods aim to track objects of predefined categories. Recently, some open-vocabulary MOT (OV-MOT) methods have successfully addressed the problem of tracking unknown categories. However, we found that the CV-MOT and OV-MOT methods each struggle to excel in the tasks of the other. In this paper, we present a unified framework, Associate Everything Detected (AED), that simultaneously tackles CV-MOT and OV-MOT by integrating with any off-the-shelf detector and supports unknown categories. Different from existing tracking-by-detection MOT methods, AED gets rid of prior knowledge (e.g. motion cues) and relies solely on highly robust feature learning to handle complex trajectories in OV-MOT tasks while keeping excellent performance in CV-MOT tasks. Specifically, we model the association task as a similarity decoding problem and propose a sim-decoder with an association-centric learning mechanism. The sim-decoder calculates similarities in three aspects: spatial, temporal, and cross-clip. Subsequently, association-centric learning leverages these threefold similarities to ensure that the extracted features are appropriate for continuous tracking and robust enough to generalize to unknown categories. Compared with existing powerful OV-MOT and CV-MOT methods, AED achieves superior performance on TAO, SportsMOT, and DanceTrack without any prior knowledge. Our code is available at https://github.com/balabooooo/AED.
Read more9/17/2024

0
ADA-Track: End-to-End Multi-Camera 3D Multi-Object Tracking with Alternating Detection and Association
Shuxiao Ding, Lukas Schneider, Marius Cordts, Juergen Gall
Many query-based approaches for 3D Multi-Object Tracking (MOT) adopt the tracking-by-attention paradigm, utilizing track queries for identity-consistent detection and object queries for identity-agnostic track spawning. Tracking-by-attention, however, entangles detection and tracking queries in one embedding for both the detection and tracking task, which is sub-optimal. Other approaches resemble the tracking-by-detection paradigm, detecting objects using decoupled track and detection queries followed by a subsequent association. These methods, however, do not leverage synergies between the detection and association task. Combining the strengths of both paradigms, we introduce ADA-Track, a novel end-to-end framework for 3D MOT from multi-view cameras. We introduce a learnable data association module based on edge-augmented cross-attention, leveraging appearance and geometric features. Furthermore, we integrate this association module into the decoder layer of a DETR-based 3D detector, enabling simultaneous DETR-like query-to-image cross-attention for detection and query-to-query cross-attention for data association. By stacking these decoder layers, queries are refined for the detection and association task alternately, effectively harnessing the task dependencies. We evaluate our method on the nuScenes dataset and demonstrate the advantage of our approach compared to the two previous paradigms. Code is available at https://github.com/dsx0511/ADA-Track.
Read more5/16/2024
🐍
0
Siamese-DETR for Generic Multi-Object Tracking
Qiankun Liu, Yichen Li, Yuqi Jiang, Ying Fu
The ability to detect and track the dynamic objects in different scenes is fundamental to real-world applications, e.g., autonomous driving and robot navigation. However, traditional Multi-Object Tracking (MOT) is limited to tracking objects belonging to the pre-defined closed-set categories. Recently, Open-Vocabulary MOT (OVMOT) and Generic MOT (GMOT) are proposed to track interested objects beyond pre-defined categories with the given text prompt and template image. However, the expensive well pre-trained (vision-)language model and fine-grained category annotations are required to train OVMOT models. In this paper, we focus on GMOT and propose a simple but effective method, Siamese-DETR, for GMOT. Only the commonly used detection datasets (e.g., COCO) are required for training. Different from existing GMOT methods, which train a Single Object Tracking (SOT) based detector to detect interested objects and then apply a data association based MOT tracker to get the trajectories, we leverage the inherent object queries in DETR variants. Specifically: 1) The multi-scale object queries are designed based on the given template image, which are effective for detecting different scales of objects with the same category as the template image; 2) A dynamic matching training strategy is introduced to train Siamese-DETR on commonly used detection datasets, which takes full advantage of provided annotations; 3) The online tracking pipeline is simplified through a tracking-by-query manner by incorporating the tracked boxes in previous frame as additional query boxes. The complex data association is replaced with the much simpler Non-Maximum Suppression (NMS). Extensive experimental results show that Siamese-DETR surpasses existing MOT methods on GMOT-40 dataset by a large margin.
Read more6/18/2024

0
New!SLAck: Semantic, Location, and Appearance Aware Open-Vocabulary Tracking
Siyuan Li, Lei Ke, Yung-Hsu Yang, Luigi Piccinelli, Mattia Seg`u, Martin Danelljan, Luc Van Gool
Open-vocabulary Multiple Object Tracking (MOT) aims to generalize trackers to novel categories not in the training set. Currently, the best-performing methods are mainly based on pure appearance matching. Due to the complexity of motion patterns in the large-vocabulary scenarios and unstable classification of the novel objects, the motion and semantics cues are either ignored or applied based on heuristics in the final matching steps by existing methods. In this paper, we present a unified framework SLAck that jointly considers semantics, location, and appearance priors in the early steps of association and learns how to integrate all valuable information through a lightweight spatial and temporal object graph. Our method eliminates complex post-processing heuristics for fusing different cues and boosts the association performance significantly for large-scale open-vocabulary tracking. Without bells and whistles, we outperform previous state-of-the-art methods for novel classes tracking on the open-vocabulary MOT and TAO TETA benchmarks. Our code is available at href{https://github.com/siyuanliii/SLAck}{github.com/siyuanliii/SLAck}.
Read more9/18/2024