Assumption-Lean and Data-Adaptive Post-Prediction Inference

0

Sign in to get full access
Overview
- This paper introduces a new approach for post-prediction inference that is assumption-lean and data-adaptive.
- The method aims to provide reliable statistical inferences without relying on strong assumptions about the data-generating process.
- It adaptively incorporates information from the prediction model to improve the accuracy of the inferences.
Plain English Explanation
When scientists or researchers want to make conclusions about something based on data, they often need to make assumptions about how the data was generated. This paper introduces a new approach that can provide reliable statistical inferences without needing to rely on these strong assumptions.
The key idea is to adaptively incorporate information from the prediction model that was used to generate the predictions. This helps improve the accuracy of the final inferences, without requiring the strict assumptions that are often needed.
For example, imagine a study looking at the effects of a new drug. Researchers would typically need to assume things like the data following a normal distribution. This new approach instead uses the prediction model to inform the statistical analysis, avoiding the need for those strong assumptions.
By being more data-adaptive and less assumption-dependent, this method can provide more reliable and meaningful conclusions from the data, even in cases where the underlying data-generating process is complex or not well understood.
Technical Explanation
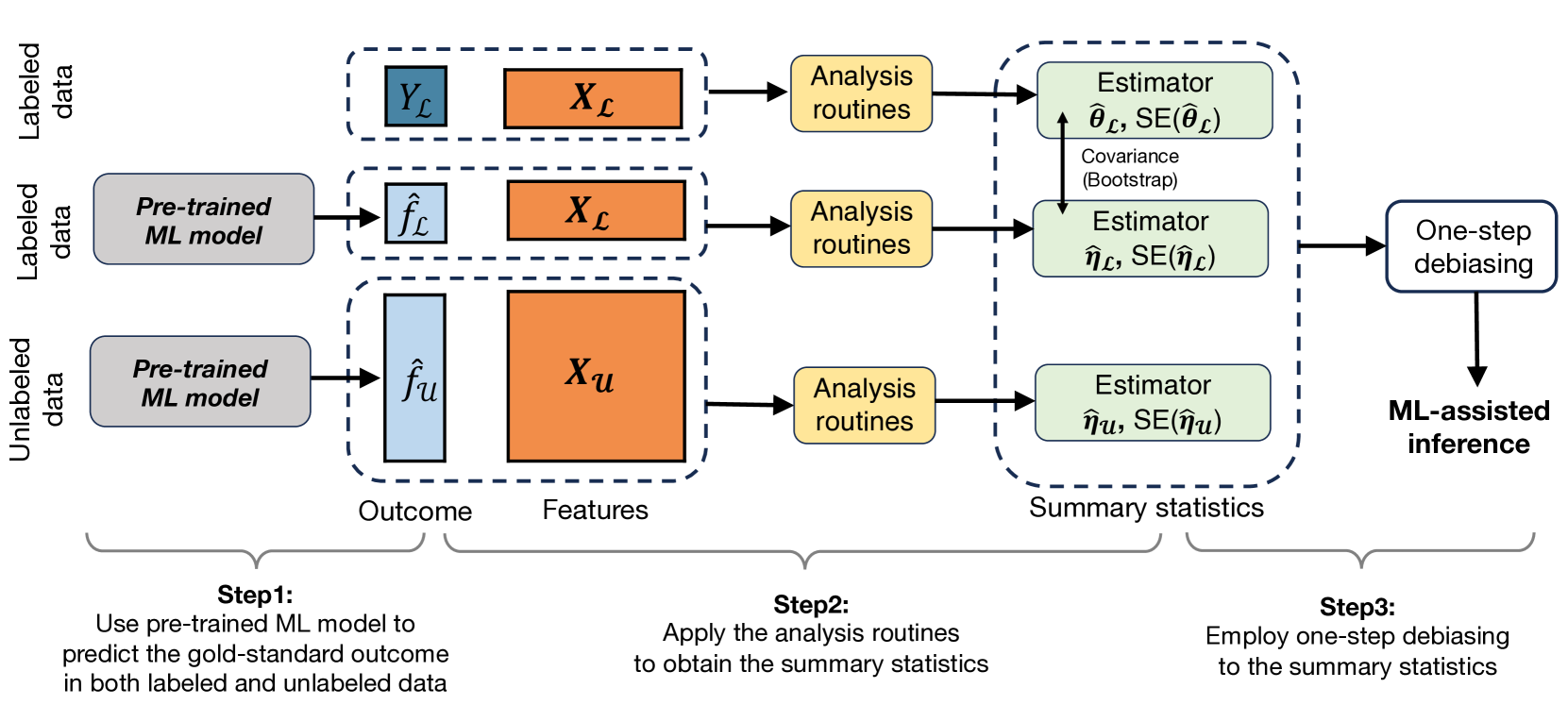
The paper presents a new framework for post-prediction inference that aims to be assumption-lean and data-adaptive. The key idea is to leverage information from the prediction model used to generate the outcomes, in order to improve the accuracy of subsequent statistical inferences.
Traditionally, making reliable inferences from data requires strong assumptions about the data-generating process, such as parametric model forms or independence. This new approach seeks to relax these assumptions by adaptively incorporating the prediction model into the inference procedure.
The authors demonstrate this approach through an example of estimating the outcome mean. They show how the prediction model can be used to construct an improved estimate of the mean, without needing to assume the data follows a normal distribution or have constant variance.
Theoretically, the method is shown to provide asymptotically valid inferences under mild conditions on the prediction model. Empirically, the authors demonstrate improvements in finite-sample performance compared to standard approaches, especially when the data departs from restrictive assumptions.
Critical Analysis
The authors highlight several key limitations and areas for future research. One is the need to carefully select the prediction model, as a poorly performing model could negatively impact the inferences. Developing methods to optimally select or ensemble prediction models is an important area for further work.
Additionally, the current framework assumes the prediction model is fixed and known. Extending the approach to handle uncertainty in the prediction model or even jointly learn the prediction model and inferences could improve its flexibility and applicability.
While the authors demonstrate promising empirical results, further research is needed to fully understand the properties and limitations of this approach, especially in high-dimensional or complex data settings. Careful comparisons to other robust inference methods would also help establish the relative merits of this technique.
Conclusion
This paper introduces an innovative approach for conducting post-prediction statistical inferences in a more assumption-lean and data-adaptive manner. By leveraging the prediction model to inform the inference procedure, it can provide reliable conclusions without relying on restrictive assumptions about the data.
This work has the potential to significantly impact fields where complex, high-dimensional data is common and traditional inferential methods may be inadequate. Further development and real-world applications of this technique could lead to more robust, meaningful, and impactful statistical analyses across a variety of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Assumption-Lean and Data-Adaptive Post-Prediction Inference
Jiacheng Miao, Xinran Miao, Yixuan Wu, Jiwei Zhao, Qiongshi Lu
A primary challenge facing modern scientific research is the limited availability of gold-standard data which can be costly, labor-intensive, or invasive to obtain. With the rapid development of machine learning (ML), scientists can now employ ML algorithms to predict gold-standard outcomes with variables that are easier to obtain. However, these predicted outcomes are often used directly in subsequent statistical analyses, ignoring imprecision and heterogeneity introduced by the prediction procedure. This will likely result in false positive findings and invalid scientific conclusions. In this work, we introduce PoSt-Prediction Adaptive inference (PSPA) that allows valid and powerful inference based on ML-predicted data. Its assumption-lean property guarantees reliable statistical inference without assumptions on the ML prediction. Its data-adaptive feature guarantees an efficiency gain over existing methods, regardless of the accuracy of ML prediction. We demonstrate the statistical superiority and broad applicability of our method through simulations and real-data applications.
Read more9/17/2024
0
Task-Agnostic Machine Learning-Assisted Inference
Jiacheng Miao, Qiongshi Lu
Machine learning (ML) is playing an increasingly important role in scientific research. In conjunction with classical statistical approaches, ML-assisted analytical strategies have shown great promise in accelerating research findings. This has also opened up a whole new field of methodological research focusing on integrative approaches that leverage both ML and statistics to tackle data science challenges. One type of study that has quickly gained popularity employs ML to predict unobserved outcomes in massive samples and then uses the predicted outcomes in downstream statistical inference. However, existing methods designed to ensure the validity of this type of post-prediction inference are limited to very basic tasks such as linear regression analysis. This is because any extension of these approaches to new, more sophisticated statistical tasks requires task-specific algebraic derivations and software implementations, which ignores the massive library of existing software tools already developed for complex inference tasks and severely constrains the scope of post-prediction inference in real applications. To address this challenge, we propose a novel statistical framework for task-agnostic ML-assisted inference. It provides a post-prediction inference solution that can be easily plugged into almost any established data analysis routine. It delivers valid and efficient inference that is robust to arbitrary choices of ML models, while allowing nearly all existing analytical frameworks to be incorporated into the analysis of ML-predicted outcomes. Through extensive experiments, we showcase the validity, versatility, and superiority of our method compared to existing approaches.
Read more5/31/2024
0
Active Statistical Inference
Tijana Zrnic, Emmanuel J. Cand`es
Inspired by the concept of active learning, we propose active inference$unicode{x2013}$a methodology for statistical inference with machine-learning-assisted data collection. Assuming a budget on the number of labels that can be collected, the methodology uses a machine learning model to identify which data points would be most beneficial to label, thus effectively utilizing the budget. It operates on a simple yet powerful intuition: prioritize the collection of labels for data points where the model exhibits uncertainty, and rely on the model's predictions where it is confident. Active inference constructs provably valid confidence intervals and hypothesis tests while leveraging any black-box machine learning model and handling any data distribution. The key point is that it achieves the same level of accuracy with far fewer samples than existing baselines relying on non-adaptively-collected data. This means that for the same number of collected samples, active inference enables smaller confidence intervals and more powerful p-values. We evaluate active inference on datasets from public opinion research, census analysis, and proteomics.
Read more5/30/2024
🤯
0
Bayesian Prediction-Powered Inference
R. Alex Hofer, Joshua Maynez, Bhuwan Dhingra, Adam Fisch, Amir Globerson, William W. Cohen
Prediction-powered inference (PPI) is a method that improves statistical estimates based on limited human-labeled data. Specifically, PPI methods provide tighter confidence intervals by combining small amounts of human-labeled data with larger amounts of data labeled by a reasonably accurate, but potentially biased, automatic system. We propose a framework for PPI based on Bayesian inference that allows researchers to develop new task-appropriate PPI methods easily. Exploiting the ease with which we can design new metrics, we propose improved PPI methods for several importantcases, such as autoraters that give discrete responses (e.g., prompted LLM ``judges'') and autoraters with scores that have a non-linear relationship to human scores.
Read more5/13/2024