Asymmetric Bias in Text-to-Image Generation with Adversarial Attacks

0

Sign in to get full access
Overview
- This paper investigates the problem of asymmetric bias in text-to-image generation models, where the model may exhibit different biases depending on the input text.
- The researchers propose a novel adversarial attack method to uncover these biases and demonstrate its effectiveness on several state-of-the-art text-to-image models.
- The findings highlight the importance of addressing bias and fairness in these powerful generative AI systems.
Plain English Explanation
Text-to-image generation models are AI systems that can create images based on text descriptions. However, these models may exhibit different biases depending on the input text. For example, the model might generate more realistic images for certain types of text compared to others.
The researchers in this paper developed a new way to test for these biases using adversarial attacks. Adversarial attacks are a type of technique where you intentionally give the model inputs that are designed to expose its weaknesses or flaws.
By applying their adversarial attack method to several state-of-the-art text-to-image models, the researchers were able to uncover asymmetric biases - that is, biases that differ depending on the input text. This is an important finding because it highlights the need to address bias and fairness in these powerful AI systems, to ensure they are treating all inputs fairly and not exhibiting unfair or discriminatory behavior.
The paper's insights can help inform the development of more robust and equitable text-to-image generation models going forward.
Technical Explanation
The researchers propose a novel adversarial attack method to uncover asymmetric biases in text-to-image generation models. They define "asymmetric bias" as a bias in the model's performance that varies depending on the input text.
To test for this, they develop an adversarial attack algorithm that generates adversarial text prompts designed to expose the model's biases. The key idea is to create prompts that are semantically similar but elicit very different image outputs from the model.
The researchers evaluate their attack method on several state-of-the-art text-to-image models, including DALL-E 2, Imagen, and [Midjourney]. They find that these models exhibit significant asymmetric biases, producing lower-quality images for certain types of text prompts compared to others.
The paper also introduces an evaluation metric called "prompt-conditional Fréchet Inception Distance" (pcFID) to quantify the degree of asymmetric bias in the model outputs. This metric allows them to systematically measure and compare the biases across different models and input prompts.
Critical Analysis
The paper makes an important contribution by highlighting the issue of asymmetric bias in text-to-image generation models, which has received relatively little attention compared to other types of AI bias. The adversarial attack method proposed is a clever way to uncover these biases in a systematic way.
However, the paper does not delve deeply into the potential causes of the observed biases, which could stem from various factors in the model architecture, training data, or other design choices. Further research is needed to better understand the mechanisms underlying these asymmetric biases.
Additionally, while the pcFID metric provides a quantitative way to measure bias, it may not capture all nuances of the problem. Qualitative analysis of the model outputs and their societal implications could also yield valuable insights.
Finally, the paper focuses on a limited set of text-to-image models, and it would be interesting to see the approach applied to a broader range of systems, including newer or more specialized models. Expanding the scope of the investigation could lead to a more comprehensive understanding of the bias issues in this fast-moving field.
Conclusion
This paper makes an important contribution by uncovering the issue of asymmetric bias in text-to-image generation models. The proposed adversarial attack method and evaluation metric provide a systematic way to identify and measure these biases, which is a crucial step towards developing more robust and equitable AI systems.
The findings highlight the need for continued research and development to address bias and fairness in generative AI, as these models become increasingly powerful and widespread. By understanding the limitations and biases of these systems, the AI community can work towards creating text-to-image models that are fair, inclusive, and beneficial to all users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Asymmetric Bias in Text-to-Image Generation with Adversarial Attacks
Haz Sameen Shahgir, Xianghao Kong, Greg Ver Steeg, Yue Dong
The widespread use of Text-to-Image (T2I) models in content generation requires careful examination of their safety, including their robustness to adversarial attacks. Despite extensive research on adversarial attacks, the reasons for their effectiveness remain underexplored. This paper presents an empirical study on adversarial attacks against T2I models, focusing on analyzing factors associated with attack success rates (ASR). We introduce a new attack objective - entity swapping using adversarial suffixes and two gradient-based attack algorithms. Human and automatic evaluations reveal the asymmetric nature of ASRs on entity swap: for example, it is easier to replace human with robot in the prompt a human dancing in the rain. with an adversarial suffix, but the reverse replacement is significantly harder. We further propose probing metrics to establish indicative signals from the model's beliefs to the adversarial ASR. We identify conditions that result in a success probability of 60% for adversarial attacks and others where this likelihood drops below 5%.
Read more7/18/2024
0
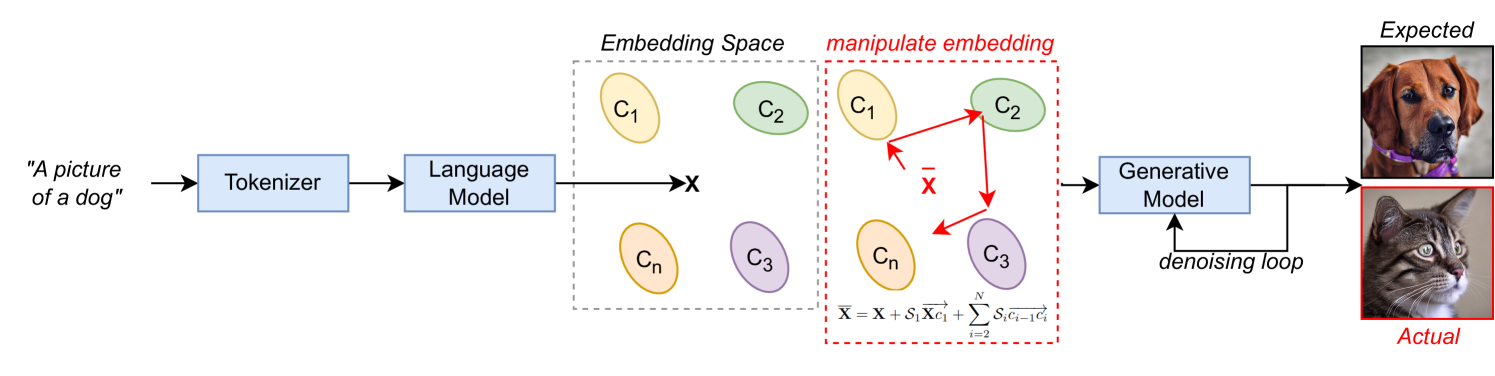
Severity Controlled Text-to-Image Generative Model Bias Manipulation
Jordan Vice, Naveed Akhtar, Richard Hartley, Ajmal Mian
Text-to-image (T2I) generative models are gaining wide popularity, especially in public domains. However, their intrinsic bias and potential malicious manipulations remain under-explored. Charting the susceptibility of T2I models to such manipulation, we first expose the new possibility of a dynamic and computationally efficient exploitation of model bias by targeting the embedded language models. By leveraging mathematical foundations of vector algebra, our technique enables a scalable and convenient control over the severity of output manipulation through model bias. As a by-product, this control also allows a form of precise prompt engineering to generate images which are generally implausible with regular text prompts. We also demonstrate a constructive application of our manipulation for balancing the frequency of generated classes - as in model debiasing. Our technique does not require training and is also framed as a backdoor attack with severity control using semantically-null text triggers in the prompts. With extensive analysis, we present interesting qualitative and quantitative results to expose potential manipulation possibilities for T2I models. Key-words: Text-to-Image Models, Generative Models, Backdoor Attacks, Prompt Engineering, Bias
Read more4/4/2024

0
Adversarial Attacks and Defenses on Text-to-Image Diffusion Models: A Survey
Chenyu Zhang, Mingwang Hu, Wenhui Li, Lanjun Wang
Recently, the text-to-image diffusion model has gained considerable attention from the community due to its exceptional image generation capability. A representative model, Stable Diffusion, amassed more than 10 million users within just two months of its release. This surge in popularity has facilitated studies on the robustness and safety of the model, leading to the proposal of various adversarial attack methods. Simultaneously, there has been a marked increase in research focused on defense methods to improve the robustness and safety of these models. In this survey, we provide a comprehensive review of the literature on adversarial attacks and defenses targeting text-to-image diffusion models. We begin with an overview of text-to-image diffusion models, followed by an introduction to a taxonomy of adversarial attacks and an in-depth review of existing attack methods. We then present a detailed analysis of current defense methods that improve model robustness and safety. Finally, we discuss ongoing challenges and explore promising future research directions. For a complete list of the adversarial attack and defense methods covered in this survey, please refer to our curated repository at https://github.com/datar001/Awesome-AD-on-T2IDM.
Read more9/16/2024

0
RT-Attack: Jailbreaking Text-to-Image Models via Random Token
Sensen Gao, Xiaojun Jia, Yihao Huang, Ranjie Duan, Jindong Gu, Yang Liu, Qing Guo
Recently, Text-to-Image(T2I) models have achieved remarkable success in image generation and editing, yet these models still have many potential issues, particularly in generating inappropriate or Not-Safe-For-Work(NSFW) content. Strengthening attacks and uncovering such vulnerabilities can advance the development of reliable and practical T2I models. Most of the previous works treat T2I models as white-box systems, using gradient optimization to generate adversarial prompts. However, accessing the model's gradient is often impossible in real-world scenarios. Moreover, existing defense methods, those using gradient masking, are designed to prevent attackers from obtaining accurate gradient information. While some black-box jailbreak attacks have been explored, these typically rely on simply replacing sensitive words, leading to suboptimal attack performance. To address this issue, we introduce a two-stage query-based black-box attack method utilizing random search. In the first stage, we establish a preliminary prompt by maximizing the semantic similarity between the adversarial and target harmful prompts. In the second stage, we use this initial prompt to refine our approach, creating a detailed adversarial prompt aimed at jailbreaking and maximizing the similarity in image features between the images generated from this prompt and those produced by the target harmful prompt. Extensive experiments validate the effectiveness of our method in attacking the latest prompt checkers, post-hoc image checkers, securely trained T2I models, and online commercial models.
Read more8/28/2024