Asymptotics of Language Model Alignment
2404.01730
0
0
Abstract
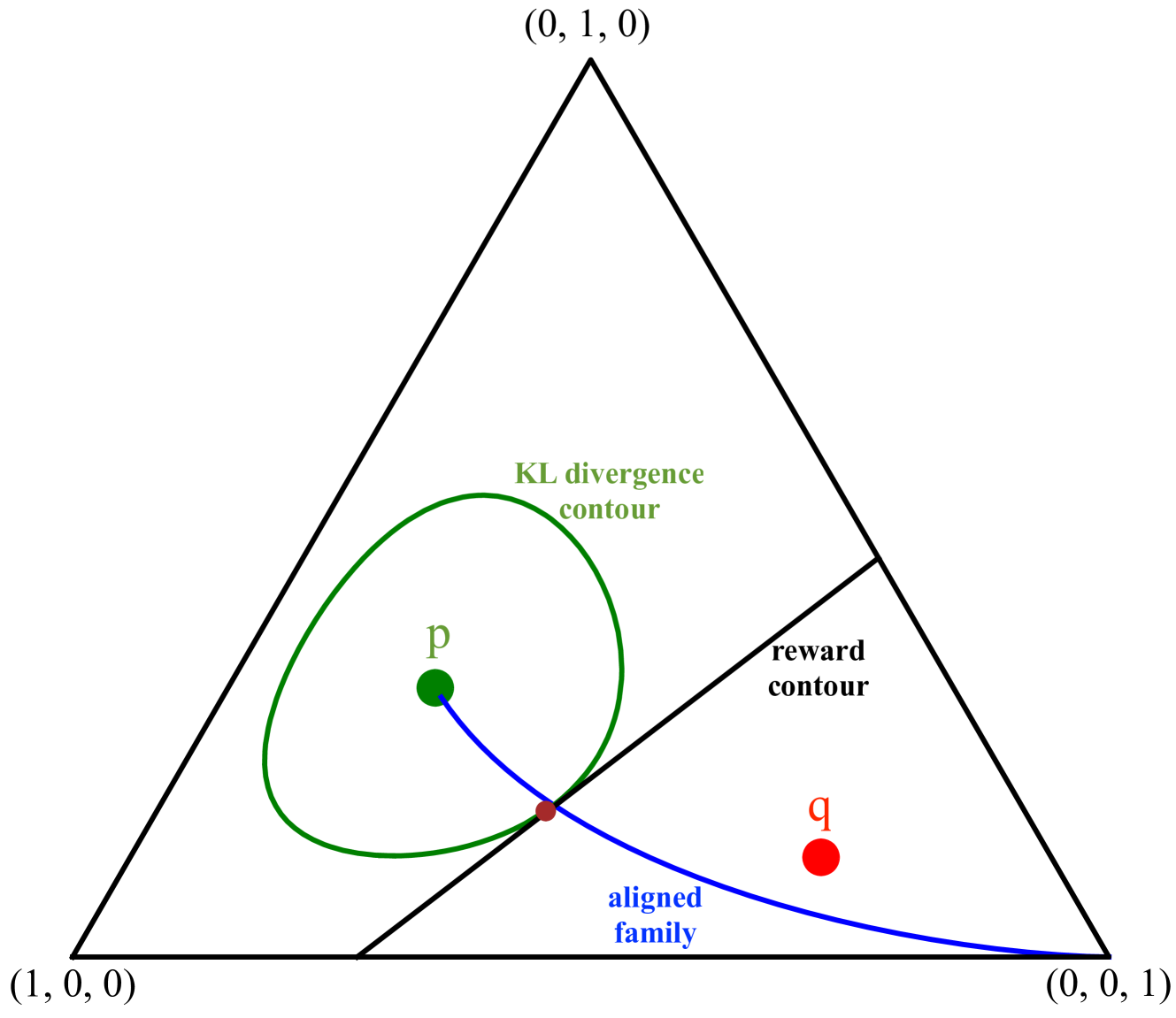
Let $p$ denote a generative language model. Let $r$ denote a reward model that returns a scalar that captures the degree at which a draw from $p$ is preferred. The goal of language model alignment is to alter $p$ to a new distribution $phi$ that results in a higher expected reward while keeping $phi$ close to $p.$ A popular alignment method is the KL-constrained reinforcement learning (RL), which chooses a distribution $phi_Delta$ that maximizes $E_{phi_{Delta}} r(y)$ subject to a relative entropy constraint $KL(phi_Delta || p) leq Delta.$ Another simple alignment method is best-of-$N$, where $N$ samples are drawn from $p$ and one with highest reward is selected. In this paper, we offer a closed-form characterization of the optimal KL-constrained RL solution. We demonstrate that any alignment method that achieves a comparable trade-off between KL divergence and reward must approximate the optimal KL-constrained RL solution in terms of relative entropy. To further analyze the properties of alignment methods, we introduce two simplifying assumptions: we let the language model be memoryless, and the reward model be linear. Although these assumptions may not reflect complex real-world scenarios, they enable a precise characterization of the asymptotic behavior of both the best-of-$N$ alignment, and the KL-constrained RL method, in terms of information-theoretic quantities. We prove that the reward of the optimal KL-constrained RL solution satisfies a large deviation principle, and we fully characterize its rate function. We also show that the rate of growth of the scaled cumulants of the reward is characterized by a proper Renyi cross entropy. Finally, we show that best-of-$N$ is asymptotically equivalent to KL-constrained RL solution by proving that their expected rewards are asymptotically equal, and concluding that the two distributions must be close in KL divergence.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the theoretical foundations of language model alignment, which is the process of ensuring that language models behave in accordance with desired characteristics or objectives.
- The authors analyze the asymptotic behavior of the optimal solution to a specific optimization problem that aims to align language models.
- The research provides insights into the fundamental limits and tradeoffs involved in language model alignment.
Plain English Explanation
The paper delves into the complex task of ensuring language models, which are AI systems that generate human-like text, behave in a desired way. Imagine you have a language model that can write articles, but you want it to always produce content that is factual, unbiased, and beneficial to society. The challenge is figuring out how to train the model to consistently meet these objectives, even as the model's capabilities grow over time.
The researchers investigate a mathematical approach to this problem, focusing on a specific optimization technique called "KL-constrained reinforcement learning." This method aims to find the optimal way to adjust the language model's behavior to align with the desired characteristics, while also considering the limitations and tradeoffs involved.
Through their analysis, the authors uncover insights into the fundamental limits of what can be achieved in language model alignment. They explore how factors like the model's size, the complexity of the desired objectives, and the available training data can influence the alignment process and its outcomes.
By understanding these theoretical underpinnings, the research paves the way for developing more effective strategies to ensure language models reliably behave in ways that are beneficial to users and society.
Technical Explanation
The paper presents a theoretical analysis of the asymptotics of language model alignment, where the goal is to optimize a language model's behavior to match a set of desired characteristics or objectives.
The authors frame the problem as a KL-constrained reinforcement learning task, where the objective is to find the optimal policy that maximizes the expected reward while satisfying a Kullback-Leibler (KL) divergence constraint between the model's distribution and a target distribution.
Through mathematical analysis, the researchers derive the asymptotic behavior of the optimal solution to this optimization problem. They show that the optimal policy converges to a specific form as the model size and training data scale, and they characterize the rate of this convergence.
The analysis reveals insights into the fundamental limits and tradeoffs involved in language model alignment. For example, the authors demonstrate how the complexity of the desired objectives and the available training data can impact the achievable alignment. They also discuss the implications of these findings for practical language model development and deployment.
Critical Analysis
The paper provides a rigorous theoretical foundation for understanding the challenges and limitations of language model alignment, which is an important and timely topic. The authors' mathematical analysis offers valuable insights into the inherent tradeoffs and constraints involved in this problem.
One potential limitation of the research is its focus on a specific optimization formulation (KL-constrained reinforcement learning). While this approach provides a useful theoretical framework, it may not capture the full complexity of real-world language model alignment, which can involve diverse objectives, architectures, and training approaches.
Additionally, the paper does not delve into the practical implications and implementation details of the theoretical findings. Further research may be needed to translate these insights into effective alignment strategies that can be deployed in production language models.
It would also be interesting to see the authors explore the potential biases and fairness implications of language model alignment, as these are crucial considerations for the responsible development of such systems.
Conclusion
This paper advances the theoretical understanding of language model alignment, a critical challenge in the development of powerful AI language systems. By analyzing the asymptotic behavior of the optimal solution to a KL-constrained reinforcement learning problem, the authors uncover fundamental insights into the limits and tradeoffs involved in aligning language models with desired characteristics.
These findings lay the groundwork for the continued refinement and responsible deployment of language models, as researchers and practitioners work to ensure these systems behave in ways that are beneficial to users and society. The theoretical insights provided in this paper can inform the development of more effective alignment strategies and guide future research in this important and rapidly evolving field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Privately Aligning Language Models with Reinforcement Learning
Fan Wu, Huseyin A. Inan, Arturs Backurs, Varun Chandrasekaran, Janardhan Kulkarni, Robert Sim
0
0
Positioned between pre-training and user deployment, aligning large language models (LLMs) through reinforcement learning (RL) has emerged as a prevailing strategy for training instruction following-models such as ChatGPT. In this work, we initiate the study of privacy-preserving alignment of LLMs through Differential Privacy (DP) in conjunction with RL. Following the influential work of Ziegler et al. (2020), we study two dominant paradigms: (i) alignment via RL without human in the loop (e.g., positive review generation) and (ii) alignment via RL from human feedback (RLHF) (e.g., summarization in a human-preferred way). We give a new DP framework to achieve alignment via RL, and prove its correctness. Our experimental results validate the effectiveness of our approach, offering competitive utility while ensuring strong privacy protections.
5/6/2024

Learn Your Reference Model for Real Good Alignment
Alexey Gorbatovski, Boris Shaposhnikov, Alexey Malakhov, Nikita Surnachev, Yaroslav Aksenov, Ian Maksimov, Nikita Balagansky, Daniil Gavrilov
0
0
The complexity of the alignment problem stems from the fact that existing methods are unstable. Researchers continuously invent various tricks to address this shortcoming. For instance, in the fundamental Reinforcement Learning From Human Feedback (RLHF) technique of Language Model alignment, in addition to reward maximization, the Kullback-Leibler divergence between the trainable policy and the SFT policy is minimized. This addition prevents the model from being overfitted to the Reward Model (RM) and generating texts that are out-of-domain for the RM. The Direct Preference Optimization (DPO) method reformulates the optimization task of RLHF and eliminates the Reward Model while tacitly maintaining the requirement for the policy to be close to the SFT policy. In our paper, we argue that this implicit limitation in the DPO method leads to sub-optimal results. We propose a new method called Trust Region DPO (TR-DPO), which updates the reference policy during training. With such a straightforward update, we demonstrate the effectiveness of TR-DPO against DPO on the Anthropic HH and TLDR datasets. We show that TR-DPO outperforms DPO by up to 19%, measured by automatic evaluation with GPT-4. The new alignment approach that we propose allows us to improve the quality of models across several parameters at once, such as coherence, correctness, level of detail, helpfulness, and harmlessness.
4/16/2024
📈
Reuse Your Rewards: Reward Model Transfer for Zero-Shot Cross-Lingual Alignment
Zhaofeng Wu, Ananth Balashankar, Yoon Kim, Jacob Eisenstein, Ahmad Beirami
0
0
Aligning language models (LMs) based on human-annotated preference data is a crucial step in obtaining practical and performant LM-based systems. However, multilingual human preference data are difficult to obtain at scale, making it challenging to extend this framework to diverse languages. In this work, we evaluate a simple approach for zero-shot cross-lingual alignment, where a reward model is trained on preference data in one source language and directly applied to other target languages. On summarization and open-ended dialog generation, we show that this method is consistently successful under comprehensive evaluation settings, including human evaluation: cross-lingually aligned models are preferred by humans over unaligned models on up to >70% of evaluation instances. We moreover find that a different-language reward model sometimes yields better aligned models than a same-language reward model. We also identify best practices when there is no language-specific data for even supervised finetuning, another component in alignment.
4/19/2024
💬
Learning Reward for Robot Skills Using Large Language Models via Self-Alignment
Yuwei Zeng, Yao Mu, Lin Shao
0
0
Learning reward functions remains the bottleneck to equip a robot with a broad repertoire of skills. Large Language Models (LLM) contain valuable task-related knowledge that can potentially aid in the learning of reward functions. However, the proposed reward function can be imprecise, thus ineffective which requires to be further grounded with environment information. We proposed a method to learn rewards more efficiently in the absence of humans. Our approach consists of two components: We first use the LLM to propose features and parameterization of the reward, then update the parameters through an iterative self-alignment process. In particular, the process minimizes the ranking inconsistency between the LLM and the learnt reward functions based on the execution feedback. The method was validated on 9 tasks across 2 simulation environments. It demonstrates a consistent improvement over training efficacy and efficiency, meanwhile consuming significantly fewer GPT tokens compared to the alternative mutation-based method.
5/17/2024