Learn Your Reference Model for Real Good Alignment
2404.09656
0
0

Abstract
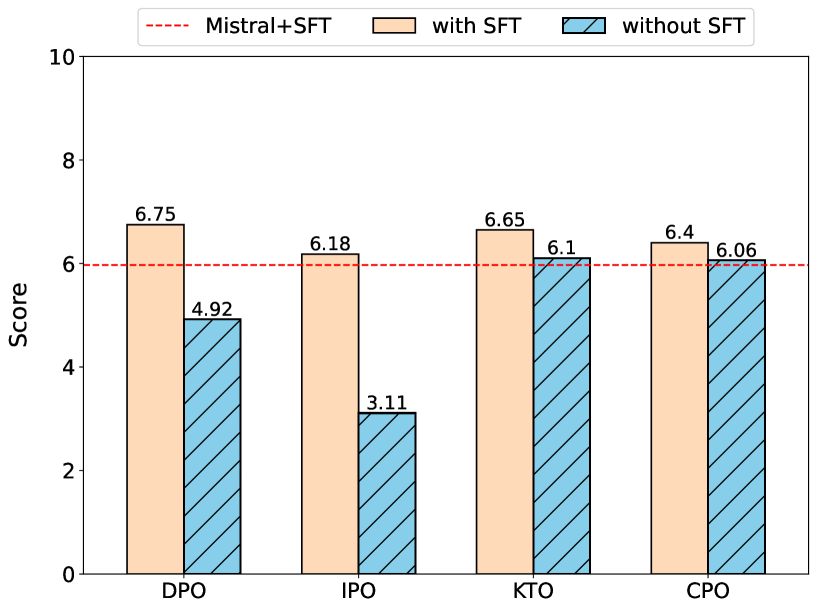
The complexity of the alignment problem stems from the fact that existing methods are unstable. Researchers continuously invent various tricks to address this shortcoming. For instance, in the fundamental Reinforcement Learning From Human Feedback (RLHF) technique of Language Model alignment, in addition to reward maximization, the Kullback-Leibler divergence between the trainable policy and the SFT policy is minimized. This addition prevents the model from being overfitted to the Reward Model (RM) and generating texts that are out-of-domain for the RM. The Direct Preference Optimization (DPO) method reformulates the optimization task of RLHF and eliminates the Reward Model while tacitly maintaining the requirement for the policy to be close to the SFT policy. In our paper, we argue that this implicit limitation in the DPO method leads to sub-optimal results. We propose a new method called Trust Region DPO (TR-DPO), which updates the reference policy during training. With such a straightforward update, we demonstrate the effectiveness of TR-DPO against DPO on the Anthropic HH and TLDR datasets. We show that TR-DPO outperforms DPO by up to 19%, measured by automatic evaluation with GPT-4. The new alignment approach that we propose allows us to improve the quality of models across several parameters at once, such as coherence, correctness, level of detail, helpfulness, and harmlessness.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper proposes a method for "learning your reference model" to achieve better alignment between language models and desired behaviors.
- The key idea is to use self-play and gradient-based optimization to learn a reference model that captures the intended behavior, and then align the language model to this reference.
- The authors demonstrate the effectiveness of this approach on several tasks, including Provably Robust DPO Aligning Language Models to Noisy Preferences, Latent Distance Guided Alignment Training for Large Language Models, and SALMON: Self-Alignment of Instructable Reward Models.
Plain English Explanation
The paper presents a technique to help language models, such as large language models, behave more closely in line with what humans intend. The key idea is to have the model "learn" what the desired behavior should be, rather than simply trying to align it with some predefined set of rules or instructions.
The method works by having the model engage in a sort of "self-play" - it tries different approaches and then evaluates how well they match the intended behavior. Over time, through this iterative process, the model is able to learn a "reference model" that captures the essence of what the desired behavior should be.
Once this reference model is learned, the original language model can then be aligned to it, helping ensure its outputs and actions are more closely aligned with human intentions. The authors show this approach can be effective across a range of different tasks, from aligning models to noisy human preferences, to guiding the training of large language models, to helping models better follow complex instructions.
The advantage of this "learn your own reference" approach is that it allows the model to discover the optimal way to behave, rather than trying to anticipate and hard-code all the rules. This can lead to more natural, flexible, and robust alignment between the model's behavior and human intentions.
Technical Explanation
The core of the proposed method is to use self-play and gradient-based optimization to learn a reference model that captures the intended behavior, and then align the language model to this reference.
Specifically, the authors introduce a framework where the language model and a reference model engage in an iterative process. The reference model is initialized randomly and updated via gradient descent to better match the intended behavior, as defined by a "loss function" that quantifies how well the reference model's outputs align with the desired outcomes.
Meanwhile, the language model is trained to match the outputs of this evolving reference model, using techniques like Latent Distance Guided Alignment Training and SALMON: Self-Alignment of Instructable Reward Models. This encourages the language model to learn representations and behaviors that closely match the reference model's "ideal" behavior.
The authors demonstrate the effectiveness of this approach on several tasks, including Provably Robust DPO Aligning Language Models to Noisy Preferences and Investigating Regularization in Self-Play for Language Models. They show that by learning a reference model tailored to the specific task or desired behavior, the language model can be better aligned than if it were simply trained on a predefined set of rules or instructions.
Critical Analysis
The authors acknowledge several limitations and caveats to their approach. First, the self-play process used to learn the reference model can be computationally expensive and may require careful hyperparameter tuning to converge reliably. Additionally, there are open questions around the Asymptotics of Language Model Alignment - i.e., how the quality of alignment scales as the language model and task complexity increase.
Another potential concern is the stability and generalization of the learned reference model. If the self-play process is overly sensitive to the specific training data or task formulation, the resulting reference model may not reliably capture the true "intended" behavior, limiting the effectiveness of the alignment.
Furthermore, while the authors demonstrate the approach on several tasks, it remains to be seen how well it will scale to more open-ended, real-world applications where the "intended" behavior is more ambiguous or subjective. Careful evaluation and monitoring will be crucial to ensure the learned reference models are truly capturing human preferences and values.
Overall, the "learn your reference model" approach is a promising direction for improving the alignment of language models with human intentions. However, further research is needed to address the computational and stability challenges, as well as to validate the approach on a broader range of real-world applications.
Conclusion
This paper proposes a novel method for aligning language models with desired behaviors by having the model "learn" an optimal reference model through self-play and gradient-based optimization. The key advantage of this approach is that it allows the model to discover the most effective way to behave, rather than trying to anticipate and hard-code all the rules.
The authors demonstrate the effectiveness of this technique on several tasks, showing that it can lead to more natural, flexible, and robust alignment compared to traditional approaches. However, the method also has some limitations, such as computational complexity and questions around the scalability and generalization of the learned reference models.
Overall, this research represents an important step forward in the quest for truly aligned and cooperative language models that reliably behave in accordance with human intentions. As AI systems become increasingly powerful and ubiquitous, developing robust and transparent alignment techniques will be crucial to ensure they remain a beneficial force for humanity.
Related Papers
Insights into Alignment: Evaluating DPO and its Variants Across Multiple Tasks
Amir Saeidi, Shivanshu Verma, Chitta Baral
0
0
Large Language Models (LLMs) have demonstrated remarkable performance across a spectrum of tasks. Recently, Direct Preference Optimization (DPO) has emerged as an RL-free approach to optimize the policy model on human preferences. However, several limitations hinder the widespread adoption of this method. To address these shortcomings, various versions of DPO have been introduced. Yet, a comprehensive evaluation of these variants across diverse tasks is still lacking. In this study, we aim to bridge this gap by investigating the performance of alignment methods across three distinct scenarios: (1) keeping the Supervised Fine-Tuning (SFT) part, (2) skipping the SFT part, and (3) skipping the SFT part and utilizing an instruction-tuned model. Furthermore, we explore the impact of different training sizes on their performance. Our evaluation spans a range of tasks including dialogue systems, reasoning, mathematical problem-solving, question answering, truthfulness, and multi-task understanding, encompassing 13 benchmarks such as MT-Bench, Big Bench, and Open LLM Leaderboard. Key observations reveal that alignment methods achieve optimal performance with smaller training data subsets, exhibit limited effectiveness in reasoning tasks yet significantly impact mathematical problem-solving, and employing an instruction-tuned model notably influences truthfulness. We anticipate that our findings will catalyze further research aimed at developing more robust models to address alignment challenges.
4/24/2024
Is DPO Superior to PPO for LLM Alignment? A Comprehensive Study
Shusheng Xu, Wei Fu, Jiaxuan Gao, Wenjie Ye, Weilin Liu, Zhiyu Mei, Guangju Wang, Chao Yu, Yi Wu
0
0
Reinforcement Learning from Human Feedback (RLHF) is currently the most widely used method to align large language models (LLMs) with human preferences. Existing RLHF methods can be roughly categorized as either reward-based or reward-free. Novel applications such as ChatGPT and Claude leverage reward-based methods that first learn a reward model and apply actor-critic algorithms, such as Proximal Policy Optimization (PPO). However, in academic benchmarks, state-of-the-art results are often achieved via reward-free methods, such as Direct Preference Optimization (DPO). Is DPO truly superior to PPO? Why does PPO perform poorly on these benchmarks? In this paper, we first conduct both theoretical and empirical studies on the algorithmic properties of DPO and show that DPO may have fundamental limitations. Moreover, we also comprehensively examine PPO and reveal the key factors for the best performances of PPO in fine-tuning LLMs. Finally, we benchmark DPO and PPO across a collection of RLHF testbeds, ranging from dialogue to code generation. Experiment results demonstrate that PPO is able to surpass other alignment methods in all cases and achieve state-of-the-art results in challenging code competitions.
4/23/2024
More RLHF, More Trust? On The Impact of Human Preference Alignment On Language Model Trustworthiness
Aaron J. Li, Satyapriya Krishna, Himabindu Lakkaraju
0
0
The surge in Large Language Models (LLMs) development has led to improved performance on cognitive tasks as well as an urgent need to align these models with human values in order to safely exploit their power. Despite the effectiveness of preference learning algorithms like Reinforcement Learning From Human Feedback (RLHF) in aligning human preferences, their assumed improvements on model trustworthiness haven't been thoroughly testified. Toward this end, this study investigates how models that have been aligned with general-purpose preference data on helpfulness and harmlessness perform across five trustworthiness verticals: toxicity, stereotypical bias, machine ethics, truthfulness, and privacy. For model alignment, we focus on three widely used RLHF variants: Supervised Finetuning (SFT), Proximal Policy Optimization (PPO), and Direct Preference Optimization (DPO). Through extensive empirical investigations, we discover that the improvement in trustworthiness by RLHF is far from guaranteed, and there exists a complex interplay between preference data, alignment algorithms, and specific trustworthiness aspects. Together, our results underscore the need for more nuanced approaches for model alignment. By shedding light on the intricate dynamics of these components within model alignment, we hope this research will guide the community towards developing language models that are both capable and trustworthy.
4/30/2024

From $r$ to $Q^*$: Your Language Model is Secretly a Q-Function
Rafael Rafailov, Joey Hejna, Ryan Park, Chelsea Finn
0
0
Reinforcement Learning From Human Feedback (RLHF) has been a critical to the success of the latest generation of generative AI models. In response to the complex nature of the classical RLHF pipeline, direct alignment algorithms such as Direct Preference Optimization (DPO) have emerged as an alternative approach. Although DPO solves the same objective as the standard RLHF setup, there is a mismatch between the two approaches. Standard RLHF deploys reinforcement learning in a specific token-level MDP, while DPO is derived as a bandit problem in which the whole response of the model is treated as a single arm. In this work we rectify this difference, first we theoretically show that we can derive DPO in the token-level MDP as a general inverse Q-learning algorithm, which satisfies the Bellman equation. Using our theoretical results, we provide three concrete empirical insights. First, we show that because of its token level interpretation, DPO is able to perform some type of credit assignment. Next, we prove that under the token level formulation, classical search-based algorithms, such as MCTS, which have recently been applied to the language generation space, are equivalent to likelihood-based search on a DPO policy. Empirically we show that a simple beam search yields meaningful improvement over the base DPO policy. Finally, we show how the choice of reference policy causes implicit rewards to decline during training. We conclude by discussing applications of our work, including information elicitation in multi-tun dialogue, reasoning, agentic applications and end-to-end training of multi-model systems.
4/19/2024