Asynchronous Local-SGD Training for Language Modeling

0

Sign in to get full access
Overview
- This paper presents an asynchronous Local-SGD (Stochastic Gradient Descent) training approach for language modeling tasks.
- The method aims to improve the efficiency and scalability of training large language models by leveraging multiple devices.
- Key ideas include a framework for asynchronous Local-SGD and addressing optimization challenges in this distributed setting.
Plain English Explanation
The paper describes a new way to train large language models, which are AI systems that can understand and generate human-like text. Training these models typically requires a lot of computing power and time.
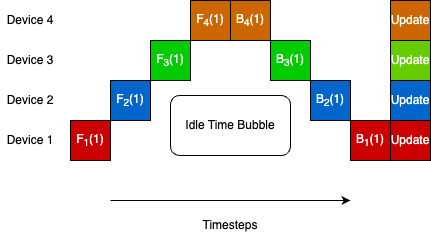
The researchers propose using an "asynchronous Local-SGD" approach, which means the training happens across multiple devices (like computers or phones) at the same time, but in a more flexible way compared to traditional methods. 1. Framework (Section 3)
This allows the training to be more efficient and scalable, as the work can be distributed across many devices. However, this also introduces some optimization challenges, such as how to effectively combine the updates from the different devices. 2. Optimization Challenge (Section 4)
The paper discusses strategies to address these challenges and improve the performance of the asynchronous Local-SGD approach for training large language models.
Technical Explanation
The paper introduces a framework for asynchronous Local-SGD training, where each device (e.g., a computer or phone) performs local updates to the model independently, and these updates are then combined asynchronously. 1. Framework (Section 3)
This approach aims to improve the efficiency and scalability of training large language models compared to traditional synchronous training methods. However, the asynchronous nature introduces optimization challenges, as the model updates from the different devices may be out of sync and conflicting. 2. Optimization Challenge (Section 4)
The paper explores strategies to address these challenges, such as dynamic gradient clipping, adaptive learning rates, and importance sampling. The researchers also analyze the convergence properties of the asynchronous Local-SGD approach and conduct experiments to validate their methods.
Critical Analysis
The paper provides a thoughtful approach to addressing the challenges of training large language models in a distributed, asynchronous setting. The proposed strategies, such as dynamic gradient clipping and adaptive learning rates, seem well-justified and could be applicable to other distributed machine learning problems.
However, the paper does not fully explore the potential limitations or edge cases of the asynchronous Local-SGD approach. For example, it would be interesting to see how the method performs under highly heterogeneous device configurations or in the presence of significant network latency or device failures.
Additionally, the paper could have discussed the potential trade-offs between the improved efficiency and scalability of the asynchronous approach versus the potential for slower convergence or increased variance in the model updates.
Conclusion
This paper presents an innovative asynchronous Local-SGD approach for training large language models, which aims to improve the efficiency and scalability of these computationally intensive tasks. The researchers have identified key optimization challenges and proposed strategies to address them, contributing valuable insights to the field of distributed machine learning.
While the paper provides a strong technical foundation, further research could explore the method's robustness and limitations in more diverse real-world scenarios. Overall, this work represents an important step forward in developing scalable and efficient techniques for training state-of-the-art language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Asynchronous Local-SGD Training for Language Modeling
Bo Liu, Rachita Chhaparia, Arthur Douillard, Satyen Kale, Andrei A. Rusu, Jiajun Shen, Arthur Szlam, Marc'Aurelio Ranzato
Local stochastic gradient descent (Local-SGD), also referred to as federated averaging, is an approach to distributed optimization where each device performs more than one SGD update per communication. This work presents an empirical study of {it asynchronous} Local-SGD for training language models; that is, each worker updates the global parameters as soon as it has finished its SGD steps. We conduct a comprehensive investigation by examining how worker hardware heterogeneity, model size, number of workers, and optimizer could impact the learning performance. We find that with naive implementations, asynchronous Local-SGD takes more iterations to converge than its synchronous counterpart despite updating the (global) model parameters more frequently. We identify momentum acceleration on the global parameters when worker gradients are stale as a key challenge. We propose a novel method that utilizes a delayed Nesterov momentum update and adjusts the workers' local training steps based on their computation speed. This approach, evaluated with models up to 150M parameters on the C4 dataset, matches the performance of synchronous Local-SGD in terms of perplexity per update step, and significantly surpasses it in terms of wall clock time.
Read more9/24/2024
💬
0
New!Exploring Scaling Laws for Local SGD in Large Language Model Training
Qiaozhi He, Xiaomin Zhuang, Zhihua Wu
This paper investigates scaling laws for local SGD in LLM training, a distributed optimization algorithm that facilitates training on loosely connected devices. Through extensive experiments, we show that local SGD achieves competitive results compared to conventional methods, given equivalent model parameters, datasets, and computational resources. Furthermore, we explore the application of local SGD in various practical scenarios, including multi-cluster setups and edge computing environments. Our findings elucidate the necessary conditions for effective multi-cluster LLM training and examine the potential and limitations of leveraging edge computing resources in the LLM training process. This demonstrates its viability as an alternative to single large-cluster training.
Read more9/23/2024
0
Ravnest: Decentralized Asynchronous Training on Heterogeneous Devices
Anirudh Rajiv Menon, Unnikrishnan Menon, Kailash Ahirwar
Modern deep learning models, growing larger and more complex, have demonstrated exceptional generalization and accuracy due to training on huge datasets. This trend is expected to continue. However, the increasing size of these models poses challenges in training, as traditional centralized methods are limited by memory constraints at such scales. This paper proposes an asynchronous decentralized training paradigm for large modern deep learning models that harnesses the compute power of regular heterogeneous PCs with limited resources connected across the internet to achieve favourable performance metrics. Ravnest facilitates decentralized training by efficiently organizing compute nodes into clusters with similar data transfer rates and compute capabilities, without necessitating that each node hosts the entire model. These clusters engage in $textit{Zero-Bubble Asynchronous Model Parallel}$ training, and a $textit{Parallel Multi-Ring All-Reduce}$ method is employed to effectively execute global parameter averaging across all clusters. We have framed our asynchronous SGD loss function as a block structured optimization problem with delayed updates and derived an optimal convergence rate of $Oleft(frac{1}{sqrt{K}}right)$. We further discuss linear speedup with respect to the number of participating clusters and the bound on the staleness parameter.
Read more5/24/2024
🔮
0
Locally Adaptive Federated Learning
Sohom Mukherjee, Nicolas Loizou, Sebastian U. Stich
Federated learning is a paradigm of distributed machine learning in which multiple clients coordinate with a central server to learn a model, without sharing their own training data. Standard federated optimization methods such as Federated Averaging (FedAvg) ensure balance among the clients by using the same stepsize for local updates on all clients. However, this means that all clients need to respect the global geometry of the function which could yield slow convergence. In this work, we propose locally adaptive federated learning algorithms, that leverage the local geometric information for each client function. We show that such locally adaptive methods with uncoordinated stepsizes across all clients can be particularly efficient in interpolated (overparameterized) settings, and analyze their convergence in the presence of heterogeneous data for convex and strongly convex settings. We validate our theoretical claims by performing illustrative experiments for both i.i.d. non-i.i.d. cases. Our proposed algorithms match the optimization performance of tuned FedAvg in the convex setting, outperform FedAvg as well as state-of-the-art adaptive federated algorithms like FedAMS for non-convex experiments, and come with superior generalization performance.
Read more5/15/2024