Atomas: Hierarchical Alignment on Molecule-Text for Unified Molecule Understanding and Generation

0
🤔
Sign in to get full access
Overview
- This paper presents a new method called Atomas for learning molecular representations by jointly using SMILES string and text data.
- Existing approaches use a global alignment strategy, which fails to capture fine-grained information like molecular fragments and their textual descriptions.
- Atomas uses a Hierarchical Adaptive Alignment model to learn representations of molecular fragments and align them across the SMILES and text modalities.
- Atomas can support a wide range of downstream tasks through its end-to-end training framework that learns to both understand and generate molecules.
Plain English Explanation
Molecules are the fundamental building blocks of all matter, and understanding their properties is crucial in fields like drug discovery and materials science. Researchers have been exploring ways to use machine learning to better represent and understand molecules.
One approach is to use the SMILES string, a text-based representation of a molecule's chemical structure, along with the written descriptions of the molecule in scientific papers and other text data. By learning how the SMILES string and text descriptions correspond to each other, machines can build a richer understanding of molecules.
However, existing methods have struggled to capture the fine-grained details, like the relationships between specific molecular fragments and their textual descriptions. This is crucial information for many applications.
The Atomas method proposed in this paper aims to address this by using a hierarchical approach to align the SMILES string and text data at multiple levels of granularity. This allows it to learn representations of molecular fragments and how they correspond to the text descriptions.
Atomas can then use this knowledge to not only understand molecules better, but also to generate new molecules with desired properties. This makes it a powerful tool for tasks like drug discovery and materials design.
Technical Explanation
The key innovation in Atomas is the Hierarchical Adaptive Alignment model, which learns to align the SMILES string and text data at multiple levels of granularity. This starts by aligning the overall representations of the molecule, then proceeds to align the representations of molecular fragments and their corresponding textual descriptions.
This hierarchical approach allows Atomas to capture fine-grained correspondences between the SMILES and text modalities, which is crucial for downstream tasks that rely on this level of detail, such as molecule captioning and generation.
Atomas is trained in an end-to-end fashion, with objectives for both understanding (e.g., molecule retrieval) and generating molecules. This flexible framework allows it to be applied to a wide range of downstream applications.
The paper demonstrates Atomas' strong performance on various benchmarks, including a 30.8% improvement in molecule retrieval accuracy over previous methods. The visualizations of the learned alignments also provide interesting chemical insights.
Critical Analysis
One limitation mentioned in the paper is the scarcity of paired, local part-annotated data, which makes it challenging to directly model the fine-grained fragment-level correspondences. The authors address this by designing the hierarchical alignment model, but further advances in data collection and curation could potentially benefit this approach.
Additionally, while the paper showcases Atomas' strong performance on standard benchmarks, it would be valuable to see more real-world evaluations, such as its impact on actual drug discovery or materials design workflows. Deeper engagement with domain experts could help validate the practical utility of the method.
Overall, Atomas represents an interesting and promising step forward in multi-modal molecular representation learning, with the potential to significantly impact various scientific fields. As the field continues to evolve, it will be important to address the remaining challenges and further demonstrate the real-world applicability of these techniques.
Conclusion
The Atomas framework presented in this paper is a significant advancement in multi-modal molecular representation learning. By jointly learning from SMILES strings and text data using a hierarchical alignment approach, Atomas is able to capture fine-grained correspondences between molecular fragments and their textual descriptions.
This rich molecular understanding enables Atomas to excel at a variety of downstream tasks, from molecule retrieval to captioning and generation. As the field of computational chemistry and materials science continues to evolve, tools like Atomas will become increasingly valuable for accelerating scientific discovery and innovation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
0
Atomas: Hierarchical Alignment on Molecule-Text for Unified Molecule Understanding and Generation
Yikun Zhang, Geyan Ye, Chaohao Yuan, Bo Han, Long-Kai Huang, Jianhua Yao, Wei Liu, Yu Rong
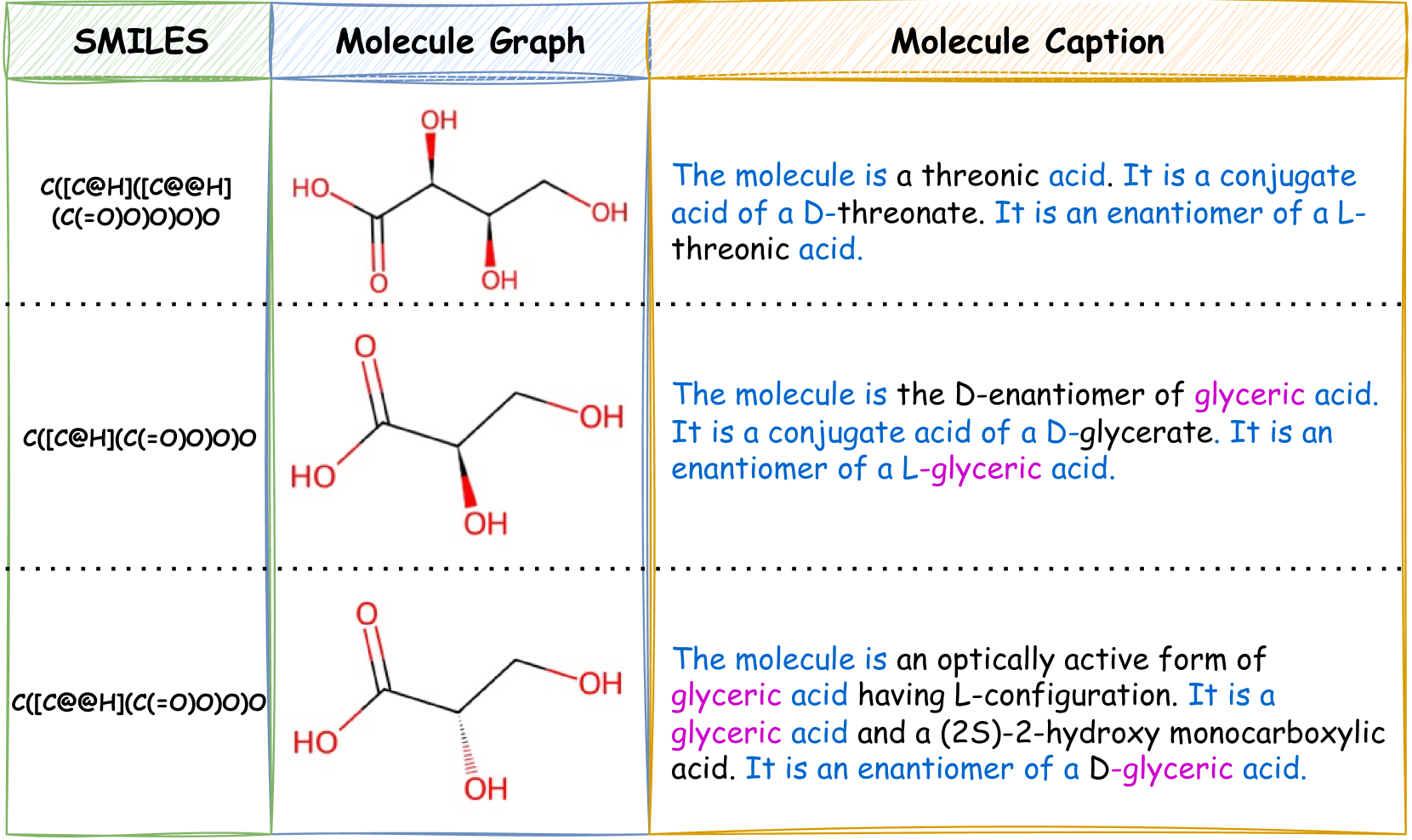
Molecule-and-text cross-modal representation learning has emerged as a promising direction for enhancing the quality of molecular representation, thereby improving performance in various scientific fields, including drug discovery and materials science. Existing studies adopt a global alignment approach to learn the knowledge from different modalities. These global alignment approaches fail to capture fine-grained information, such as molecular fragments and their corresponding textual description, which is crucial for downstream tasks. Furthermore, it is incapable to model such information using a similar global alignment strategy due to data scarcity of paired local part annotated data from existing datasets. In this paper, we propose Atomas, a multi-modal molecular representation learning framework to jointly learn representations from SMILES string and text. We design a Hierarchical Adaptive Alignment model to concurrently learn the fine-grained fragment correspondence between two modalities and align these representations of fragments in three levels. Additionally, Atomas's end-to-end training framework incorporates the tasks of understanding and generating molecule, thereby supporting a wider range of downstream tasks. In the retrieval task, Atomas exhibits robust generalization ability and outperforms the baseline by 30.8% of recall@1 on average. In the generation task, Atomas achieves state-of-the-art results in both molecule captioning task and molecule generation task. Moreover, the visualization of the Hierarchical Adaptive Alignment model further confirms the chemical significance of our approach. Our codes can be found at https://anonymous.4open.science/r/Atomas-03C3.
Read more4/29/2024

0
3D-MolT5: Towards Unified 3D Molecule-Text Modeling with 3D Molecular Tokenization
Qizhi Pei, Lijun Wu, Kaiyuan Gao, Jinhua Zhu, Rui Yan
The integration of molecule and language has garnered increasing attention in molecular science. Recent advancements in Language Models (LMs) have demonstrated potential for the comprehensive modeling of molecule and language. However, existing works exhibit notable limitations. Most existing works overlook the modeling of 3D information, which is crucial for understanding molecular structures and also functions. While some attempts have been made to leverage external structure encoding modules to inject the 3D molecular information into LMs, there exist obvious difficulties that hinder the integration of molecular structure and language text, such as modality alignment and separate tuning. To bridge this gap, we propose 3D-MolT5, a unified framework designed to model both 1D molecular sequence and 3D molecular structure. The key innovation lies in our methodology for mapping fine-grained 3D substructure representations (based on 3D molecular fingerprints) to a specialized 3D token vocabulary for 3D-MolT5. This 3D structure token vocabulary enables the seamless combination of 1D sequence and 3D structure representations in a tokenized format, allowing 3D-MolT5 to encode molecular sequence (SELFIES), molecular structure, and text sequences within a unified architecture. Alongside, we further introduce 1D and 3D joint pre-training to enhance the model's comprehension of these diverse modalities in a joint representation space and better generalize to various tasks for our foundation model. Through instruction tuning on multiple downstream datasets, our proposed 3D-MolT5 shows superior performance than existing methods in molecular property prediction, molecule captioning, and text-based molecule generation tasks. Our code will be available on GitHub soon.
Read more6/11/2024

0
MolFusion: Multimodal Fusion Learning for Molecular Representations via Multi-granularity Views
Muzhen Cai, Sendong Zhao, Haochun Wang, Yanrui Du, Zewen Qiang, Bing Qin, Ting Liu
Artificial Intelligence predicts drug properties by encoding drug molecules, aiding in the rapid screening of candidates. Different molecular representations, such as SMILES and molecule graphs, contain complementary information for molecular encoding. Thus exploiting complementary information from different molecular representations is one of the research priorities in molecular encoding. Most existing methods for combining molecular multi-modalities only use molecular-level information, making it hard to encode intra-molecular alignment information between different modalities. To address this issue, we propose a multi-granularity fusion method that is MolFusion. The proposed MolFusion consists of two key components: (1) MolSim, a molecular-level encoding component that achieves molecular-level alignment between different molecular representations. and (2) AtomAlign, an atomic-level encoding component that achieves atomic-level alignment between different molecular representations. Experimental results show that MolFusion effectively utilizes complementary multimodal information, leading to significant improvements in performance across various classification and regression tasks.
Read more6/27/2024
0
Large Language Models are In-Context Molecule Learners
Jiatong Li, Wei Liu, Zhihao Ding, Wenqi Fan, Yuqiang Li, Qing Li
Large Language Models (LLMs) have demonstrated exceptional performance in biochemical tasks, especially the molecule caption translation task, which aims to bridge the gap between molecules and natural language texts. However, previous methods in adapting LLMs to the molecule-caption translation task required extra domain-specific pre-training stages, suffered weak alignment between molecular and textual spaces, or imposed stringent demands on the scale of LLMs. To resolve the challenges, we propose In-Context Molecule Adaptation (ICMA), as a new paradigm allowing LLMs to learn the molecule-text alignment from context examples via In-Context Molecule Tuning. Specifically, ICMA incorporates the following three stages: Hybrid Context Retrieval, Post-retrieval Re-ranking, and In-context Molecule Tuning. Initially, Hybrid Context Retrieval utilizes BM25 Caption Retrieval and Molecule Graph Retrieval to retrieve informative context examples. Additionally, we also propose Post-retrieval Re-ranking with Sequence Reversal and Random Walk to further improve the quality of retrieval results. Finally, In-Context Molecule Tuning unlocks the in-context molecule learning capability of LLMs with retrieved examples and adapts the parameters of LLMs for the molecule-caption translation task. Experimental results demonstrate that ICMT can empower LLMs to achieve state-of-the-art or comparable performance without extra training corpora and intricate structures, showing that LLMs are inherently in-context molecule learners.
Read more4/17/2024