Large Language Models are In-Context Molecule Learners
2403.04197
0
0
Abstract
Large Language Models (LLMs) have demonstrated exceptional performance in biochemical tasks, especially the molecule caption translation task, which aims to bridge the gap between molecules and natural language texts. However, previous methods in adapting LLMs to the molecule-caption translation task required extra domain-specific pre-training stages, suffered weak alignment between molecular and textual spaces, or imposed stringent demands on the scale of LLMs. To resolve the challenges, we propose In-Context Molecule Adaptation (ICMA), as a new paradigm allowing LLMs to learn the molecule-text alignment from context examples via In-Context Molecule Tuning. Specifically, ICMA incorporates the following three stages: Hybrid Context Retrieval, Post-retrieval Re-ranking, and In-context Molecule Tuning. Initially, Hybrid Context Retrieval utilizes BM25 Caption Retrieval and Molecule Graph Retrieval to retrieve informative context examples. Additionally, we also propose Post-retrieval Re-ranking with Sequence Reversal and Random Walk to further improve the quality of retrieval results. Finally, In-Context Molecule Tuning unlocks the in-context molecule learning capability of LLMs with retrieved examples and adapts the parameters of LLMs for the molecule-caption translation task. Experimental results demonstrate that ICMT can empower LLMs to achieve state-of-the-art or comparable performance without extra training corpora and intricate structures, showing that LLMs are inherently in-context molecule learners.
Create account to get full access
Overview
- This paper investigates the ability of large language models (LLMs) to learn and understand chemical molecules in the context of natural language.
- The researchers found that LLMs can effectively learn about molecules through textual descriptions, demonstrating an impressive in-context learning capability.
- This has significant implications for the use of LLMs in various chemistry-related tasks, such as molecule-caption translation and knowledge-based chemist support.
Plain English Explanation
Large language models (LLMs) are artificial intelligence systems that have been trained on vast amounts of text data, allowing them to understand and generate human-like language. This paper shows that LLMs can also learn about chemical molecules just by being exposed to textual descriptions of them, without any explicit training on molecular data.
Imagine you're trying to learn about a new type of molecule. Instead of studying diagrams and chemical formulas, you simply read a few sentences describing the molecule's structure and properties. A person with a strong chemistry background could likely learn a lot about the molecule this way. Similarly, the LLMs in this study were able to take in textual information about molecules and develop an understanding of their key characteristics.
This is a significant finding because it demonstrates the impressive in-context learning capabilities of LLMs. They can absorb and apply knowledge from the surrounding text, rather than requiring highly structured training data. This suggests that LLMs could be valuable tools for context-based learning and multi-task support in chemistry-related fields.
Technical Explanation
The researchers trained several LLMs, including GPT-3 and PaLM, on a large corpus of scientific literature containing textual descriptions of chemical molecules. They then evaluated the models' ability to answer questions about the structure, properties, and reactions of these molecules, without providing any explicit molecular data during training.
The results showed that the LLMs were able to learn and reason about molecules effectively, often matching or even exceeding the performance of dedicated molecular models. The models could, for example, accurately predict the likely products of chemical reactions or identify key structural features of molecules.
This in-context learning ability suggests that LLMs can serve as superhuman chemists, integrating textual knowledge to develop a rich understanding of molecular science. The researchers hypothesize that this is due to the LLMs' capacity to extract and leverage contextual information, allowing them to build conceptual models of molecules from linguistic descriptions.
Critical Analysis
The paper provides a strong demonstration of the in-context learning capabilities of LLMs, but also acknowledges several caveats and limitations. For example, the models may struggle with rare or highly specialized molecular concepts that are not well-represented in the training data. Additionally, the researchers note that the models' reasoning about molecules, while impressive, may not always be fully robust or generalizable.
Further research is needed to better understand the precise mechanisms underlying the LLMs' molecular learning, as well as to explore potential biases or blind spots in their knowledge. It will also be important to investigate the models' performance on more complex or multifaceted chemistry tasks, beyond the relatively simple question-answering scenarios examined in this study.
Despite these limitations, the findings suggest that LLMs could be valuable tools for supporting chemists and accelerating chemical discovery, provided that their capabilities and limitations are well-understood. Ongoing research in this area will be crucial for unlocking the full potential of these powerful language models in the domain of molecular science.
Conclusion
This paper demonstrates that large language models (LLMs) can effectively learn about chemical molecules by extracting and integrating relevant information from textual descriptions, without any explicit training on molecular data. This in-context learning capability has significant implications for the use of LLMs in various chemistry-related tasks, such as molecule-caption translation, knowledge-based chemist support, and multi-task applications.
While the findings are promising, further research is needed to fully understand the limitations and potential biases of these models when applied to the complex domain of molecular science. Nonetheless, the demonstrated ability of LLMs to serve as superhuman chemists through in-context learning suggests that they could become valuable tools for accelerating chemical discovery and supporting the work of human experts in the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

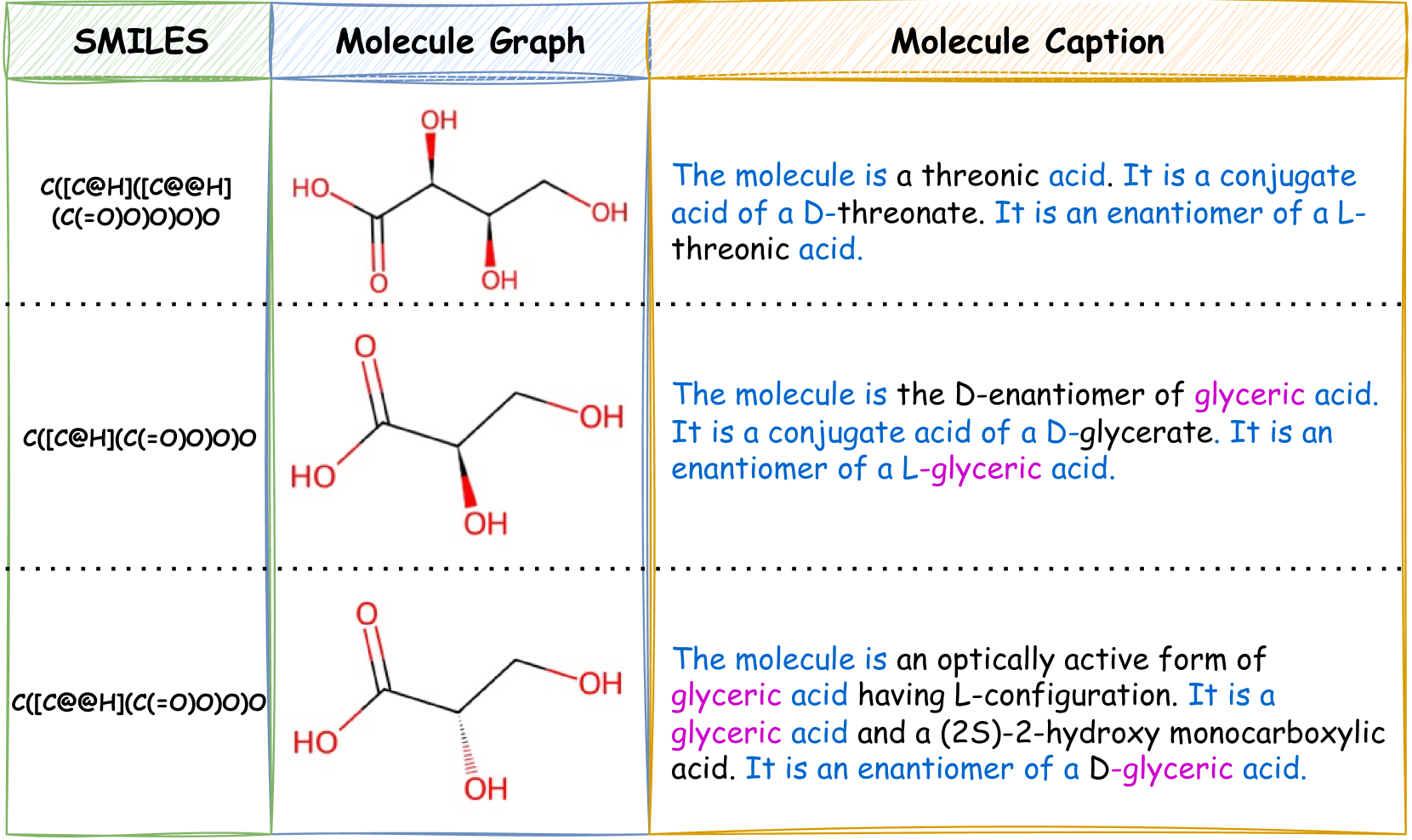
Empowering Molecule Discovery for Molecule-Caption Translation with Large Language Models: A ChatGPT Perspective
Jiatong Li, Yunqing Liu, Wenqi Fan, Xiao-Yong Wei, Hui Liu, Jiliang Tang, Qing Li
0
0
Molecule discovery plays a crucial role in various scientific fields, advancing the design of tailored materials and drugs. However, most of the existing methods heavily rely on domain experts, require excessive computational cost, or suffer from sub-optimal performance. On the other hand, Large Language Models (LLMs), like ChatGPT, have shown remarkable performance in various cross-modal tasks due to their powerful capabilities in natural language understanding, generalization, and in-context learning (ICL), which provides unprecedented opportunities to advance molecule discovery. Despite several previous works trying to apply LLMs in this task, the lack of domain-specific corpus and difficulties in training specialized LLMs still remain challenges. In this work, we propose a novel LLM-based framework (MolReGPT) for molecule-caption translation, where an In-Context Few-Shot Molecule Learning paradigm is introduced to empower molecule discovery with LLMs like ChatGPT to perform their in-context learning capability without domain-specific pre-training and fine-tuning. MolReGPT leverages the principle of molecular similarity to retrieve similar molecules and their text descriptions from a local database to enable LLMs to learn the task knowledge from context examples. We evaluate the effectiveness of MolReGPT on molecule-caption translation, including molecule understanding and text-based molecule generation. Experimental results show that compared to fine-tuned models, MolReGPT outperforms MolT5-base and is comparable to MolT5-large without additional training. To the best of our knowledge, MolReGPT is the first work to leverage LLMs via in-context learning in molecule-caption translation for advancing molecule discovery. Our work expands the scope of LLM applications, as well as providing a new paradigm for molecule discovery and design.
4/23/2024
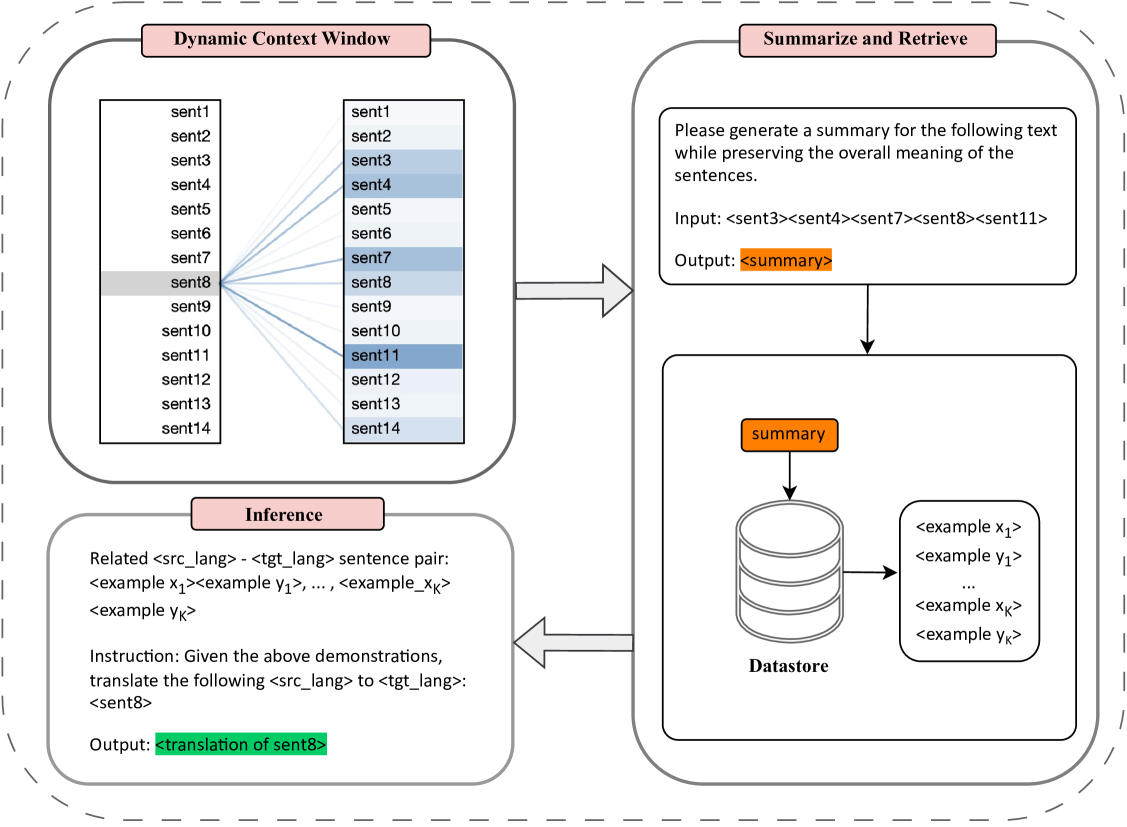
Efficiently Exploring Large Language Models for Document-Level Machine Translation with In-context Learning
Menglong Cui, Jiangcun Du, Shaolin Zhu, Deyi Xiong
0
0
Large language models (LLMs) exhibit outstanding performance in machine translation via in-context learning. In contrast to sentence-level translation, document-level translation (DOCMT) by LLMs based on in-context learning faces two major challenges: firstly, document translations generated by LLMs are often incoherent; secondly, the length of demonstration for in-context learning is usually limited. To address these issues, we propose a Context-Aware Prompting method (CAP), which enables LLMs to generate more accurate, cohesive, and coherent translations via in-context learning. CAP takes into account multi-level attention, selects the most relevant sentences to the current one as context, and then generates a summary from these collected sentences. Subsequently, sentences most similar to the summary are retrieved from the datastore as demonstrations, which effectively guide LLMs in generating cohesive and coherent translations. We conduct extensive experiments across various DOCMT tasks, and the results demonstrate the effectiveness of our approach, particularly in zero pronoun translation (ZPT) and literary translation tasks.
6/12/2024

MolX: Enhancing Large Language Models for Molecular Learning with A Multi-Modal Extension
Khiem Le, Zhichun Guo, Kaiwen Dong, Xiaobao Huang, Bozhao Nan, Roshni Iyer, Xiangliang Zhang, Olaf Wiest, Wei Wang, Nitesh V. Chawla
0
0
Recently, Large Language Models (LLMs) with their strong task-handling capabilities have shown remarkable advancements across a spectrum of fields, moving beyond natural language understanding. However, their proficiency within the chemistry domain remains restricted, especially in solving professional molecule-related tasks. This challenge is attributed to their inherent limitations in comprehending molecules using only common textual representations, i.e., SMILES strings. In this study, we seek to enhance the ability of LLMs to comprehend molecules by designing and equipping them with a multi-modal external module, namely MolX. In particular, instead of directly using a SMILES string to represent a molecule, we utilize specific encoders to extract fine-grained features from both SMILES string and 2D molecular graph representations for feeding into an LLM. Moreover, a human-defined molecular fingerprint is incorporated to leverage its embedded domain knowledge. Then, to establish an alignment between MolX and the LLM's textual input space, the whole model in which the LLM is frozen, is pre-trained with a versatile strategy including a diverse set of tasks. Extensive experimental evaluations demonstrate that our proposed method only introduces a small number of trainable parameters while outperforming baselines on various downstream molecule-related tasks ranging from molecule-to-text translation to retrosynthesis, with and without fine-tuning the LLM.
6/14/2024
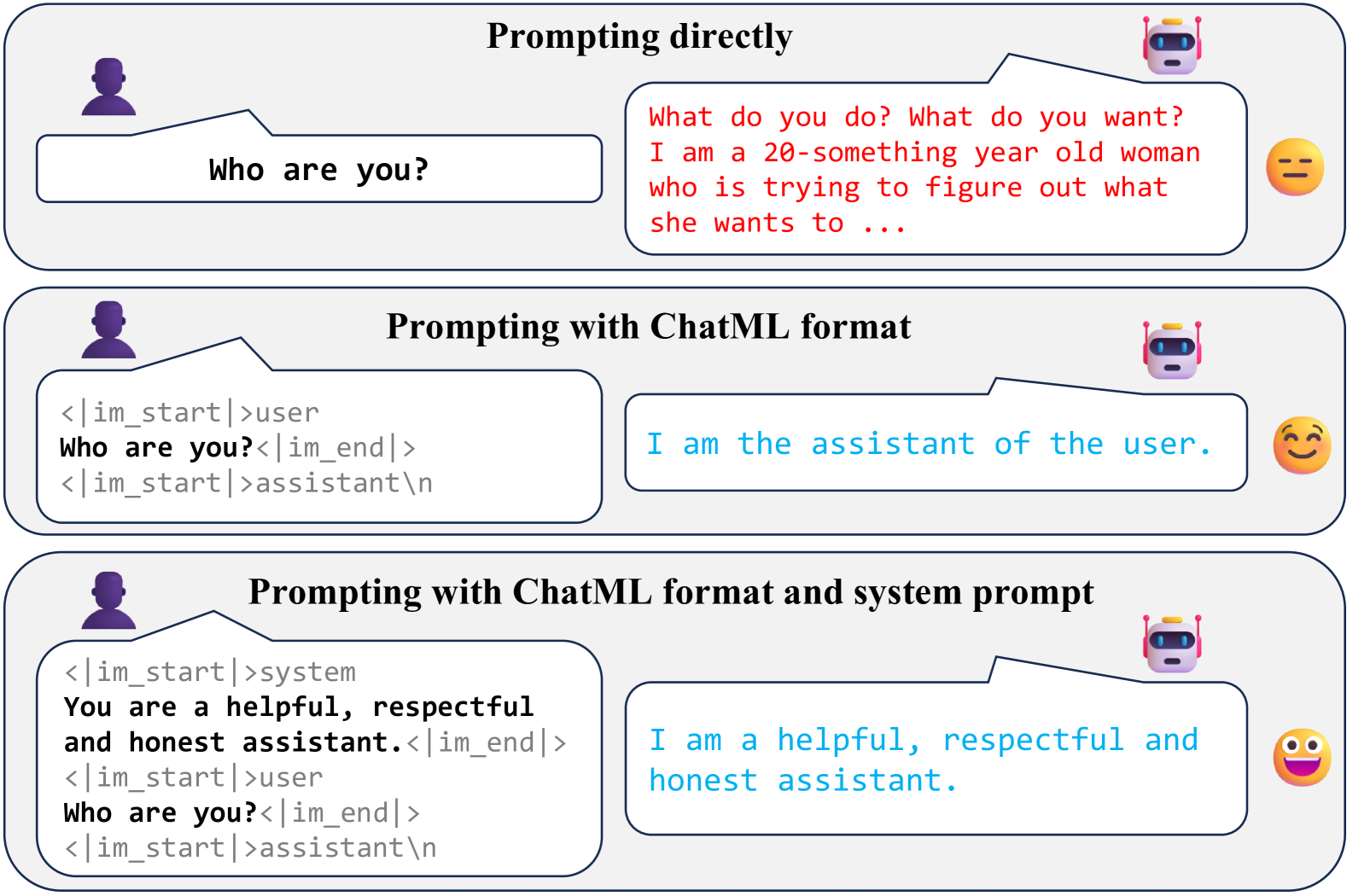
How Far Can In-Context Alignment Go? Exploring the State of In-Context Alignment
Heyan Huang, Yinghao Li, Huashan Sun, Yu Bai, Yang Gao
0
0
Recent studies have demonstrated that In-Context Learning (ICL), through the use of specific demonstrations, can align Large Language Models (LLMs) with human preferences known as In-Context Alignment (ICA), indicating that models can comprehend human instructions without requiring parameter adjustments. However, the exploration of the mechanism and applicability of ICA remains limited. In this paper, we begin by dividing the context text used in ICA into three categories: format, system prompt, and example. Through ablation experiments, we investigate the effectiveness of each part in enabling ICA to function effectively. We then examine how variants in these parts impact the model's alignment performance. Our findings indicate that the example part is crucial for enhancing the model's alignment capabilities, with changes in examples significantly affecting alignment performance. We also conduct a comprehensive evaluation of ICA's zero-shot capabilities in various alignment tasks. The results indicate that compared to parameter fine-tuning methods, ICA demonstrates superior performance in knowledge-based tasks and tool-use tasks. However, it still exhibits certain limitations in areas such as multi-turn dialogues and instruction following.
6/18/2024