Attacking Bayes: On the Adversarial Robustness of Bayesian Neural Networks
2404.19640
0
0
Abstract
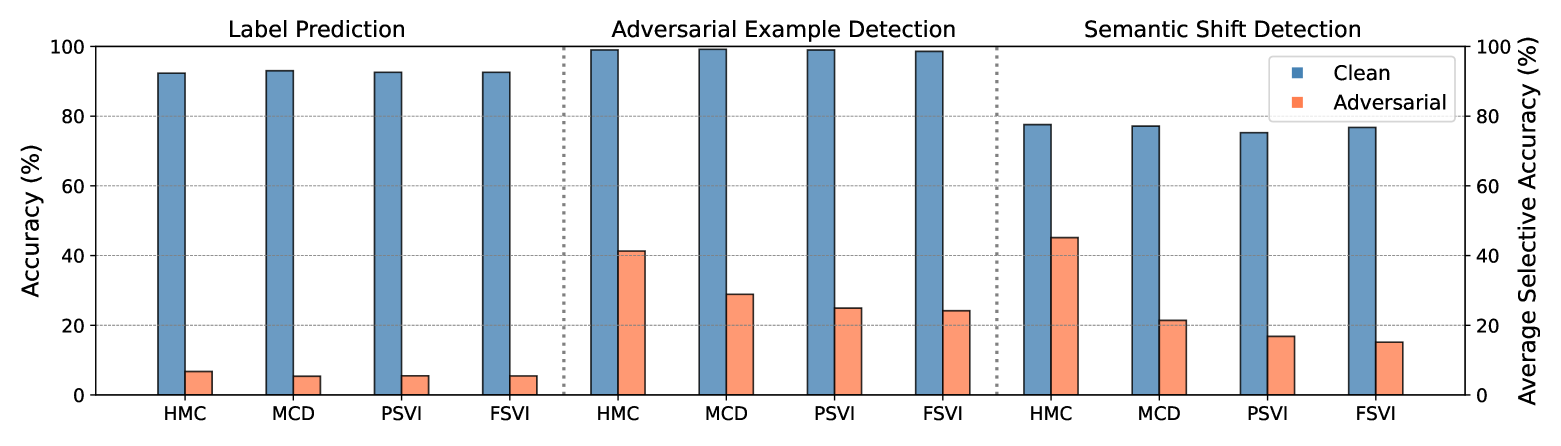
Adversarial examples have been shown to cause neural networks to fail on a wide range of vision and language tasks, but recent work has claimed that Bayesian neural networks (BNNs) are inherently robust to adversarial perturbations. In this work, we examine this claim. To study the adversarial robustness of BNNs, we investigate whether it is possible to successfully break state-of-the-art BNN inference methods and prediction pipelines using even relatively unsophisticated attacks for three tasks: (1) label prediction under the posterior predictive mean, (2) adversarial example detection with Bayesian predictive uncertainty, and (3) semantic shift detection. We find that BNNs trained with state-of-the-art approximate inference methods, and even BNNs trained with Hamiltonian Monte Carlo, are highly susceptible to adversarial attacks. We also identify various conceptual and experimental errors in previous works that claimed inherent adversarial robustness of BNNs and conclusively demonstrate that BNNs and uncertainty-aware Bayesian prediction pipelines are not inherently robust against adversarial attacks.
Create account to get full access
Overview
- This paper explores the adversarial robustness of Bayesian Neural Networks (BNNs) - a type of neural network that incorporates uncertainty into its predictions.
- The authors propose a novel attack method, called Variational Adversarial Attack (VAA), which exploits the inherent uncertainty in BNNs to generate adversarial examples that are difficult to defend against.
- The paper also analyzes the performance of various BNN training methods and their impact on adversarial robustness.
Plain English Explanation
Neural networks are a type of machine learning model that can be trained to perform various tasks, such as image recognition or language processing. Bayesian Neural Networks (BNNs) are a special type of neural network that incorporate uncertainty into their predictions. This means that instead of giving a single, definitive output, BNNs provide a probability distribution over possible outputs, which can be useful for applications where decision-making requires an understanding of the model's confidence.
However, neural networks, including BNNs, can be vulnerable to adversarial examples - small, carefully crafted perturbations to the input that can cause the model to make incorrect predictions. In this paper, the researchers propose a new attack method, called Variational Adversarial Attack (VAA), that specifically targets the uncertainty in BNNs to generate these adversarial examples.
The key idea behind VAA is to exploit the fact that BNNs produce a probability distribution over possible outputs, rather than a single, definitive answer. By crafting adversarial examples that "confuse" this probability distribution, the researchers were able to generate inputs that the BNNs would misclassify with high confidence.
The paper also explores the impact of different BNN training methods on adversarial robustness. Some training techniques, such as link to "Restricted Bayesian Neural Networks" or link to "Be Bayesian by Attachments to Catch More", were found to be more effective at defending against the VAA attack than others.
Overall, this research highlights the importance of understanding the vulnerabilities of BNNs and developing more robust training techniques to ensure the reliable deployment of these models in safety-critical applications.
Technical Explanation
The paper begins by introducing the concept of Bayesian Neural Networks (BNNs) and their potential advantages over traditional neural networks. BNNs model the uncertainty in their predictions by representing the model parameters as probability distributions, rather than fixed values.
The authors then propose a novel attack method, called the Variational Adversarial Attack (VAA), which exploits the uncertainty inherent in BNNs. The key idea behind VAA is to craft adversarial examples that "confuse" the probability distribution of the BNN's output, causing the model to make incorrect predictions with high confidence.
To evaluate the effectiveness of VAA, the researchers conduct experiments on several benchmark datasets and BNN architectures, including link to "Adversarially Robust Spiking Neural Networks Through Conversion" and link to "Adversarial Training 1-Nearest Neighbor Classifier". They compare the performance of VAA against other state-of-the-art attack methods and also analyze the impact of different BNN training techniques on adversarial robustness.
The results show that VAA is highly effective at generating adversarial examples that fool BNNs, often achieving a higher success rate than other attacks. Additionally, the paper demonstrates that certain BNN training methods, such as link to "Restricted Bayesian Neural Networks" and link to "Be Bayesian by Attachments to Catch More", are more effective at defending against the VAA attack compared to other approaches.
Critical Analysis
The paper presents a comprehensive analysis of the adversarial robustness of Bayesian Neural Networks, and the proposed Variational Adversarial Attack (VAA) appears to be a powerful and effective method for generating adversarial examples against BNNs.
One potential limitation of the research is that the experiments are primarily conducted on image classification tasks, and it would be interesting to see how the VAA attack and BNN training methods perform on other types of problems, such as natural language processing or reinforcement learning.
Additionally, the paper does not explore the interpretability or explainability of the BNNs under attack, which could be an important consideration in safety-critical applications where understanding the model's decision-making process is crucial.
Further research could also investigate the transferability of the VAA attack across different BNN architectures and training methods, as well as explore potential defense mechanisms beyond the training techniques discussed in the paper, such as link to "Survey Neural Network Robustness Assessment Image Recognition".
Overall, this paper makes a valuable contribution to the understanding of the adversarial robustness of Bayesian Neural Networks and highlights the need for continued research in this area to ensure the reliable deployment of these models in real-world applications.
Conclusion
This paper presents a novel attack method, called the Variational Adversarial Attack (VAA), that effectively exploits the inherent uncertainty in Bayesian Neural Networks (BNNs) to generate adversarial examples. The research demonstrates that VAA outperforms other state-of-the-art attack methods in fooling BNNs, and also analyzes the impact of different BNN training techniques on adversarial robustness.
The findings of this paper have important implications for the development and deployment of BNNs in safety-critical applications, where adversarial robustness is a crucial consideration. The work highlights the need for continued research into more robust BNN training methods and the exploration of other potential defense mechanisms against adversarial attacks.
By shedding light on the vulnerabilities of BNNs and proposing effective attack and defense strategies, this paper contributes to the broader effort to improve the reliability and trustworthiness of machine learning systems in real-world settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Certified Robust Accuracy of Neural Networks Are Bounded due to Bayes Errors
Ruihan Zhang, Jun Sun
0
0
Adversarial examples pose a security threat to many critical systems built on neural networks. While certified training improves robustness, it also decreases accuracy noticeably. Despite various proposals for addressing this issue, the significant accuracy drop remains. More importantly, it is not clear whether there is a certain fundamental limit on achieving robustness whilst maintaining accuracy. In this work, we offer a novel perspective based on Bayes errors. By adopting Bayes error to robustness analysis, we investigate the limit of certified robust accuracy, taking into account data distribution uncertainties. We first show that the accuracy inevitably decreases in the pursuit of robustness due to changed Bayes error in the altered data distribution. Subsequently, we establish an upper bound for certified robust accuracy, considering the distribution of individual classes and their boundaries. Our theoretical results are empirically evaluated on real-world datasets and are shown to be consistent with the limited success of existing certified training results, e.g., for CIFAR10, our analysis results in an upper bound (of certified robust accuracy) of 67.49%, meanwhile existing approaches are only able to increase it from 53.89% in 2017 to 62.84% in 2023.
6/21/2024

Explainable AI Security: Exploring Robustness of Graph Neural Networks to Adversarial Attacks
Tao Wu, Canyixing Cui, Xingping Xian, Shaojie Qiao, Chao Wang, Lin Yuan, Shui Yu
0
0
Graph neural networks (GNNs) have achieved tremendous success, but recent studies have shown that GNNs are vulnerable to adversarial attacks, which significantly hinders their use in safety-critical scenarios. Therefore, the design of robust GNNs has attracted increasing attention. However, existing research has mainly been conducted via experimental trial and error, and thus far, there remains a lack of a comprehensive understanding of the vulnerability of GNNs. To address this limitation, we systematically investigate the adversarial robustness of GNNs by considering graph data patterns, model-specific factors, and the transferability of adversarial examples. Through extensive experiments, a set of principled guidelines is obtained for improving the adversarial robustness of GNNs, for example: (i) rather than highly regular graphs, the training graph data with diverse structural patterns is crucial for model robustness, which is consistent with the concept of adversarial training; (ii) the large model capacity of GNNs with sufficient training data has a positive effect on model robustness, and only a small percentage of neurons in GNNs are affected by adversarial attacks; (iii) adversarial transfer is not symmetric and the adversarial examples produced by the small-capacity model have stronger adversarial transferability. This work illuminates the vulnerabilities of GNNs and opens many promising avenues for designing robust GNNs.
6/21/2024
Restricted Bayesian Neural Network
Sourav Ganguly, Saprativa Bhattacharjee
0
0
Modern deep learning tools are remarkably effective in addressing intricate problems. However, their operation as black-box models introduces increased uncertainty in predictions. Additionally, they contend with various challenges, including the need for substantial storage space in large networks, issues of overfitting, underfitting, vanishing gradients, and more. This study explores the concept of Bayesian Neural Networks, presenting a novel architecture designed to significantly alleviate the storage space complexity of a network. Furthermore, we introduce an algorithm adept at efficiently handling uncertainties, ensuring robust convergence values without becoming trapped in local optima, particularly when the objective function lacks perfect convexity.
4/9/2024
🤖
Intrinsic Biologically Plausible Adversarial Robustness
Matilde Tristany Farinha, Thomas Ortner, Giorgia Dellaferrera, Benjamin Grewe, Angeliki Pantazi
0
0
Artificial Neural Networks (ANNs) trained with Backpropagation (BP) excel in different daily tasks but have a dangerous vulnerability: inputs with small targeted perturbations, also known as adversarial samples, can drastically disrupt their performance. Adversarial training, a technique in which the training dataset is augmented with exemplary adversarial samples, is proven to mitigate this problem but comes at a high computational cost. In contrast to ANNs, humans are not susceptible to misclassifying these same adversarial samples. Thus, one can postulate that biologically-plausible trained ANNs might be more robust against adversarial attacks. In this work, we chose the biologically-plausible learning algorithm Present the Error to Perturb the Input To modulate Activity (PEPITA) as a case study and investigated this question through a comparative analysis with BP-trained ANNs on various computer vision tasks. We observe that PEPITA has a higher intrinsic adversarial robustness and, when adversarially trained, also has a more favorable natural-vs-adversarial performance trade-off. In particular, for the same natural accuracies on the MNIST task, PEPITA's adversarial accuracies decrease on average only by 0.26% while BP's decrease by 8.05%.
6/4/2024