Attention Based Machine Learning Methods for Data Reduction with Guaranteed Error Bounds

0
Sign in to get full access
Overview
- This paper presents attention-based machine learning methods for data reduction with guaranteed error bounds.
- The work was partially supported by DOE RAPIDS2 DE-SC0021320 and DOE DE-SC0022265.
Plain English Explanation
Attention-based machine learning is a technique that allows models to focus on the most important parts of data when making predictions. In this paper, the researchers use attention-based models to [object Object] and [object Object] of large datasets, while ensuring that the error or inaccuracy in the reduced data is kept within a guaranteed limit.
The key idea is to train the attention-based model to identify the most important or relevant parts of the data, and then use that information to create a compressed version of the dataset that still retains the most crucial details. This could be useful in [object Object] where storage space or bandwidth is limited, but the full dataset is still needed for analysis or further processing.
Technical Explanation
The paper presents two attention-based data reduction methods: [object Object] and [object Object]. AR uses attention to identify the most important features of the data and reconstruct a compressed version, while AP uses attention to project the data onto a lower-dimensional subspace.
Both methods are designed to provide guaranteed error bounds, meaning the researchers can ensure that the error or inaccuracy in the reduced data will not exceed a specified threshold. This is achieved by incorporating the error bound constraint directly into the model training process.
The paper evaluates the performance of AR and AP on both synthetic and real-world datasets, including fluid dynamics simulations and climate data. The results show that the attention-based methods can achieve significant data reduction (up to 90%) while maintaining low reconstruction errors, outperforming traditional dimensionality reduction techniques.
Critical Analysis
The paper provides a comprehensive and rigorous evaluation of the proposed attention-based data reduction methods. The authors acknowledge that the guaranteed error bounds come at the cost of slightly higher computational complexity compared to simpler dimensionality reduction techniques.
One potential limitation is that the methods may not be as effective on datasets with very high dimensionality or complex nonlinear structure, as the attention mechanisms may struggle to capture all the relevant features. Further research could explore ways to enhance the attention mechanisms or combine them with other techniques to address these challenges.
Additionally, the paper does not discuss the potential impact of the data reduction on downstream tasks or applications. It would be interesting to see how the reduced datasets perform in terms of accuracy and computational efficiency when used for tasks like prediction, anomaly detection, or decision-making.
Conclusion
This paper presents a novel approach to data reduction using attention-based machine learning techniques. The key advantage is the ability to provide guaranteed error bounds, ensuring that the compressed data retains the most important information. The results demonstrate the effectiveness of the proposed methods on a variety of datasets, making them a promising tool for applications where storage, bandwidth, or computational resources are limited.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Attention Based Machine Learning Methods for Data Reduction with Guaranteed Error Bounds
Xiao Li, Jaemoon Lee, Anand Rangarajan, Sanjay Ranka
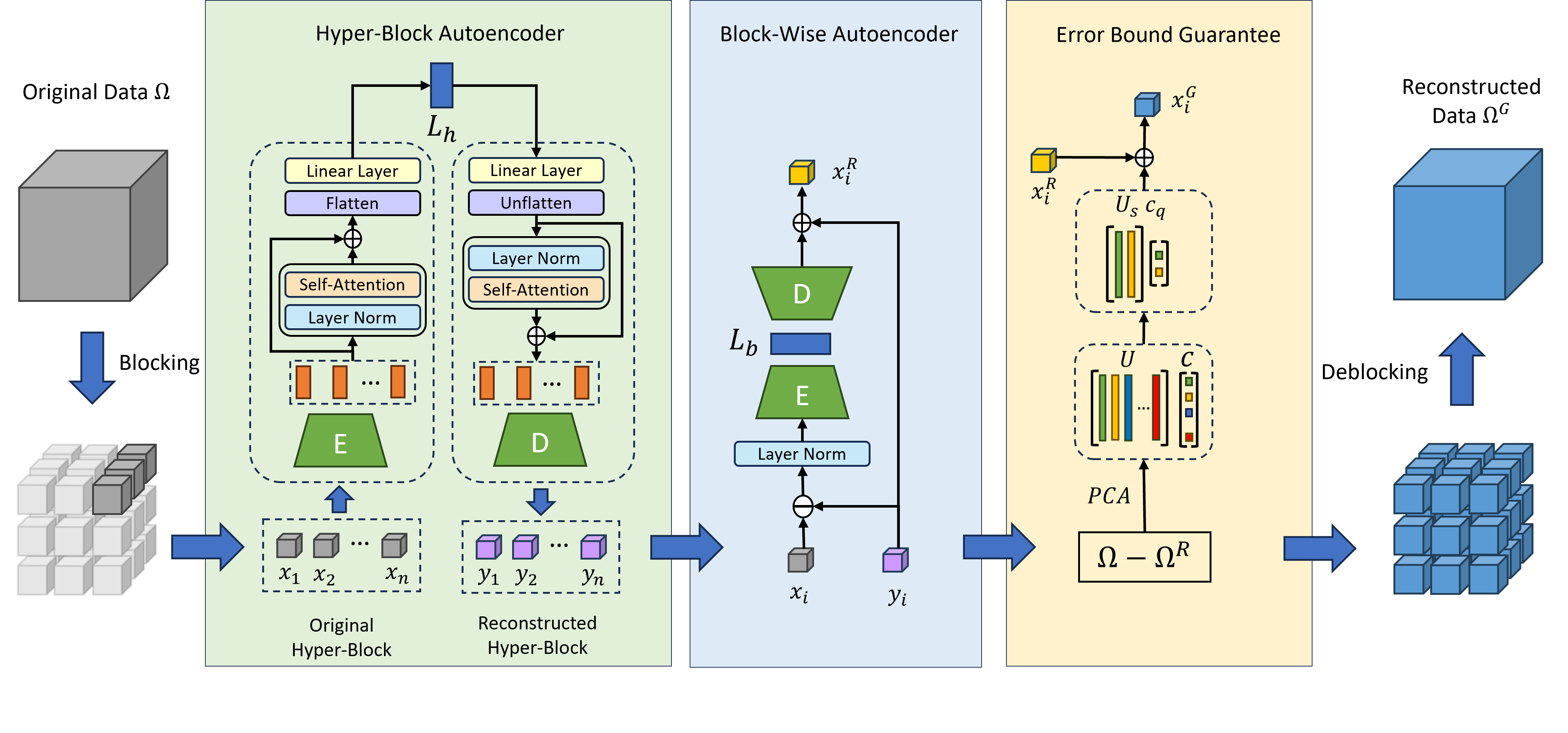
Scientific applications in fields such as high energy physics, computational fluid dynamics, and climate science generate vast amounts of data at high velocities. This exponential growth in data production is surpassing the advancements in computing power, network capabilities, and storage capacities. To address this challenge, data compression or reduction techniques are crucial. These scientific datasets have underlying data structures that consist of structured and block structured multidimensional meshes where each grid point corresponds to a tensor. It is important that data reduction techniques leverage strong spatial and temporal correlations that are ubiquitous in these applications. Additionally, applications such as CFD, process tensors comprising hundred plus species and their attributes at each grid point. Reduction techniques should be able to leverage interrelationships between the elements in each tensor. In this paper, we propose an attention-based hierarchical compression method utilizing a block-wise compression setup. We introduce an attention-based hyper-block autoencoder to capture inter-block correlations, followed by a block-wise encoder to capture block-specific information. A PCA-based post-processing step is employed to guarantee error bounds for each data block. Our method effectively captures both spatiotemporal and inter-variable correlations within and between data blocks. Compared to the state-of-the-art SZ3, our method achieves up to 8 times higher compression ratio on the multi-variable S3D dataset. When evaluated on single-variable setups using the E3SM and XGC datasets, our method still achieves up to 3 times and 2 times higher compression ratio, respectively.
Read more9/10/2024
📊
0
Machine Learning Techniques for Data Reduction of CFD Applications
Jaemoon Lee, Ki Sung Jung, Qian Gong, Xiao Li, Scott Klasky, Jacqueline Chen, Anand Rangarajan, Sanjay Ranka
We present an approach called guaranteed block autoencoder that leverages Tensor Correlations (GBATC) for reducing the spatiotemporal data generated by computational fluid dynamics (CFD) and other scientific applications. It uses a multidimensional block of tensors (spanning in space and time) for both input and output, capturing the spatiotemporal and interspecies relationship within a tensor. The tensor consists of species that represent different elements in a CFD simulation. To guarantee the error bound of the reconstructed data, principal component analysis (PCA) is applied to the residual between the original and reconstructed data. This yields a basis matrix, which is then used to project the residual of each instance. The resulting coefficients are retained to enable accurate reconstruction. Experimental results demonstrate that our approach can deliver two orders of magnitude in reduction while still keeping the errors of primary data under scientifically acceptable bounds. Compared to reduction-based approaches based on SZ, our method achieves a substantially higher compression ratio for a given error bound or a better error for a given compression ratio.
Read more4/30/2024

0
Machine Learning Techniques for Data Reduction of Climate Applications
Xiao Li, Qian Gong, Jaemoon Lee, Scott Klasky, Anand Rangarajan, Sanjay Ranka
Scientists conduct large-scale simulations to compute derived quantities-of-interest (QoI) from primary data. Often, QoI are linked to specific features, regions, or time intervals, such that data can be adaptively reduced without compromising the integrity of QoI. For many spatiotemporal applications, these QoI are binary in nature and represent presence or absence of a physical phenomenon. We present a pipelined compression approach that first uses neural-network-based techniques to derive regions where QoI are highly likely to be present. Then, we employ a Guaranteed Autoencoder (GAE) to compress data with differential error bounds. GAE uses QoI information to apply low-error compression to only these regions. This results in overall high compression ratios while still achieving downstream goals of simulation or data collections. Experimental results are presented for climate data generated from the E3SM Simulation model for downstream quantities such as tropical cyclone and atmospheric river detection and tracking. These results show that our approach is superior to comparable methods in the literature.
Read more5/3/2024
0
Hierarchical Autoencoder-based Lossy Compression for Large-scale High-resolution Scientific Data
Hieu Le, Jian Tao
Lossy compression has become an important technique to reduce data size in many domains. This type of compression is especially valuable for large-scale scientific data, whose size ranges up to several petabytes. Although Autoencoder-based models have been successfully leveraged to compress images and videos, such neural networks have not widely gained attention in the scientific data domain. Our work presents a neural network that not only significantly compresses large-scale scientific data, but also maintains high reconstruction quality. The proposed model is tested with scientific benchmark data available publicly and applied to a large-scale high-resolution climate modeling data set. Our model achieves a compression ratio of 140 on several benchmark data sets without compromising the reconstruction quality. 2D simulation data from the High-Resolution Community Earth System Model (CESM) Version 1.3 over 500 years are also being compressed with a compression ratio of 200 while the reconstruction error is negligible for scientific analysis.
Read more5/8/2024