White-Box Transformers via Sparse Rate Reduction: Compression Is All There Is?

1
🗣️
Sign in to get full access
Overview
- The paper proposes that the natural objective of representation learning is to compress and transform the data distribution towards a low-dimensional Gaussian mixture.
- It introduces a measure called "sparse rate reduction" to evaluate the quality of such representations.
- It shows that popular deep network architectures like transformers can be viewed as optimizing this objective.
- It introduces a family of white-box transformer-like architectures called CRATE that are mathematically interpretable.
- CRATE architectures are universal for both encoding and decoding tasks.
- Experiments show CRATE performs competitively with highly engineered transformer-based models on real-world datasets.
Plain English Explanation
The paper argues that the goal of machine learning models should be to compress and transform data, such as sets of text or images, into a more efficient form. Specifically, the authors believe the ideal representation would be a low-dimensional Gaussian mixture - a combination of simple bell-curve distributions.
To measure how well a model achieves this, the researchers introduce a new metric called sparse rate reduction. This balances two important factors: maximizing the information captured in the compressed representation, while also making the representation as sparse (simple) as possible.
The paper then shows that popular deep learning architectures like transformers can be viewed as trying to optimize this sparse rate reduction objective through their design. The multi-head self-attention mechanism compresses the data representation, while the subsequent multi-layer perceptron sparsifies it.
Building on this insight, the authors introduce a new family of white-box transformer-like models called CRATE. These architectures are mathematically interpretable, meaning we can clearly see how they are optimizing the sparse rate reduction objective.
Interestingly, the researchers also demonstrate that the inverse process - decoding the compressed representation back to the original data - can be performed by the same class of CRATE models. This makes them universal for both encoding and decoding tasks.
Experiments on real-world image and text datasets show that these simple CRATE models can achieve performance very close to highly engineered transformer-based models like ViT, MAE, DINO, BERT, and GPT2. This suggests CRATE could be a promising direction for bridging the gap between the theory and practice of deep learning.
Technical Explanation
The key technical insight of the paper is that representation learning should aim to compress the data distribution towards a low-dimensional Gaussian mixture. The authors introduce a principled measure called sparse rate reduction to evaluate the quality of such representations.
This metric simultaneously optimizes for two goals: maximizing the intrinsic information gain (how much of the original data is captured) and extrinsic sparsity (how simple the compressed representation is).
The paper demonstrates that popular deep learning architectures like transformers can be viewed as iterative schemes to optimize this sparse rate reduction objective. Specifically:
- The multi-head self-attention mechanism implements an approximate gradient descent step to compress the representation by reducing its coding rate.
- The subsequent multi-layer perceptron then sparsifies the compressed features.
Building on this insight, the authors derive a family of white-box transformer-like models called CRATE, which are mathematically interpretable realizations of this optimization process.
Importantly, the paper also shows that the inverse process - decoding the compressed representation back to the original data - can be performed by the same class of CRATE models. This makes them universal for both encoding and decoding tasks.
Experiments on large-scale image and text datasets demonstrate that these simple CRATE models can achieve performance very close to highly engineered transformer-based models like ViT, MAE, DINO, BERT, and GPT2. This suggests the proposed computational framework has great potential in bridging the gap between the theory and practice of deep learning, from a unified perspective of data compression.
Critical Analysis
The paper presents a compelling theoretical framework for understanding and designing deep learning architectures from the lens of data compression. The introduction of the sparse rate reduction metric provides a principled way to evaluate representation quality, balancing information capture and simplicity.
However, the authors acknowledge that their work is still theoretical in nature, and more research is needed to fully validate the practical implications. Some potential limitations and areas for further study include:
- Scaling to larger datasets and more complex tasks: While the CRATE models performed well on the tested benchmarks, their simplicity may limit their scalability to truly large-scale, real-world problems.
- Robustness and generalization: The paper does not extensively explore the robustness of CRATE models or their ability to generalize to out-of-distribution data.
- Comparison to other compression-inspired approaches: It would be valuable to situate the CRATE framework in the context of other compression-based techniques for deep learning, such as pruning and quantization.
Additionally, while the mathematical interpretability of CRATE is a strength, it remains to be seen how this theoretical clarity translates to practical benefits in terms of explainability, debugging, or safety for real-world machine learning systems.
Overall, the paper presents a novel and thought-provoking perspective on deep learning that merits further exploration and empirical validation. Researchers and practitioners should keep a critical eye on the limitations and consider the broader implications of a compression-centric approach to representation learning.
Conclusion
This paper proposes that the fundamental goal of representation learning should be to compress and transform data distributions towards a low-dimensional Gaussian mixture. It introduces a principled measure called sparse rate reduction to evaluate the quality of such representations.
The authors demonstrate that popular deep learning architectures like transformers can be viewed as optimization schemes for this objective. Building on this insight, they derive a family of white-box transformer-like models called CRATE, which are mathematically interpretable.
Experiments show that these simple CRATE models can achieve performance very close to highly engineered transformer-based models on real-world image and text datasets. This suggests the proposed computational framework has great potential in bridging the theory and practice of deep learning, from a unified perspective of data compression.
While more research is needed to fully validate the practical implications, this work presents a compelling new lens through which to understand and design deep learning systems. Researchers and practitioners should consider the merits of a compression-centric approach to representation learning and its broader implications for the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
1
White-Box Transformers via Sparse Rate Reduction: Compression Is All There Is?
Yaodong Yu, Sam Buchanan, Druv Pai, Tianzhe Chu, Ziyang Wu, Shengbang Tong, Hao Bai, Yuexiang Zhai, Benjamin D. Haeffele, Yi Ma
In this paper, we contend that a natural objective of representation learning is to compress and transform the distribution of the data, say sets of tokens, towards a low-dimensional Gaussian mixture supported on incoherent subspaces. The goodness of such a representation can be evaluated by a principled measure, called sparse rate reduction, that simultaneously maximizes the intrinsic information gain and extrinsic sparsity of the learned representation. From this perspective, popular deep network architectures, including transformers, can be viewed as realizing iterative schemes to optimize this measure. Particularly, we derive a transformer block from alternating optimization on parts of this objective: the multi-head self-attention operator compresses the representation by implementing an approximate gradient descent step on the coding rate of the features, and the subsequent multi-layer perceptron sparsifies the features. This leads to a family of white-box transformer-like deep network architectures, named CRATE, which are mathematically fully interpretable. We show, by way of a novel connection between denoising and compression, that the inverse to the aforementioned compressive encoding can be realized by the same class of CRATE architectures. Thus, the so-derived white-box architectures are universal to both encoders and decoders. Experiments show that these networks, despite their simplicity, indeed learn to compress and sparsify representations of large-scale real-world image and text datasets, and achieve performance very close to highly engineered transformer-based models: ViT, MAE, DINO, BERT, and GPT2. We believe the proposed computational framework demonstrates great potential in bridging the gap between theory and practice of deep learning, from a unified perspective of data compression. Code is available at: https://ma-lab-berkeley.github.io/CRATE .
Read more9/9/2024

0
Scaling White-Box Transformers for Vision
Jinrui Yang, Xianhang Li, Druv Pai, Yuyin Zhou, Yi Ma, Yaodong Yu, Cihang Xie
CRATE, a white-box transformer architecture designed to learn compressed and sparse representations, offers an intriguing alternative to standard vision transformers (ViTs) due to its inherent mathematical interpretability. Despite extensive investigations into the scaling behaviors of language and vision transformers, the scalability of CRATE remains an open question which this paper aims to address. Specifically, we propose CRATE-$alpha$, featuring strategic yet minimal modifications to the sparse coding block in the CRATE architecture design, and a light training recipe designed to improve the scalability of CRATE. Through extensive experiments, we demonstrate that CRATE-$alpha$ can effectively scale with larger model sizes and datasets. For example, our CRATE-$alpha$-B substantially outperforms the prior best CRATE-B model accuracy on ImageNet classification by 3.7%, achieving an accuracy of 83.2%. Meanwhile, when scaling further, our CRATE-$alpha$-L obtains an ImageNet classification accuracy of 85.1%. More notably, these model performance improvements are achieved while preserving, and potentially even enhancing the interpretability of learned CRATE models, as we demonstrate through showing that the learned token representations of increasingly larger trained CRATE-$alpha$ models yield increasingly higher-quality unsupervised object segmentation of images. The project page is https://rayjryang.github.io/CRATE-alpha/.
Read more6/4/2024
4
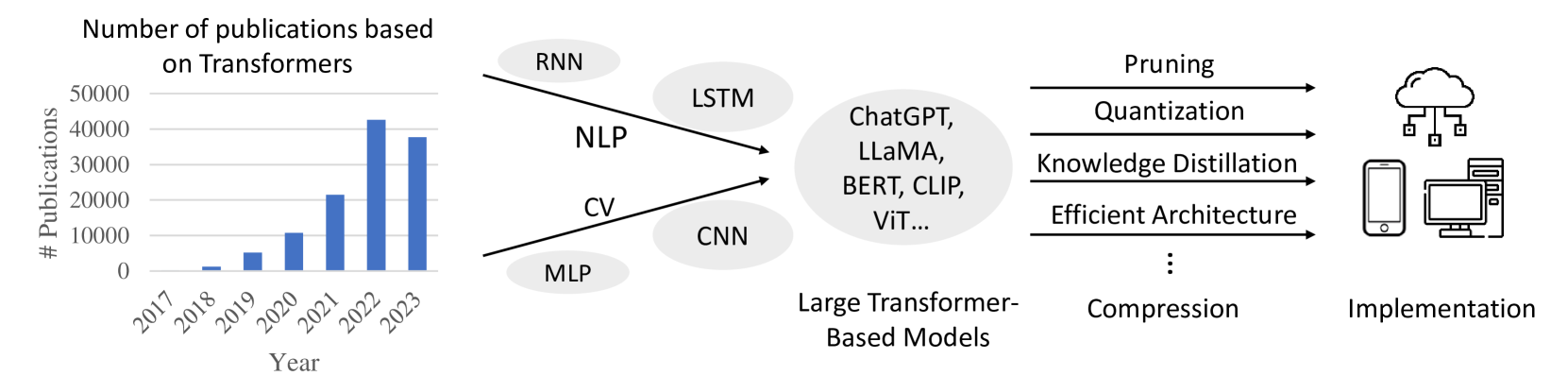
A Survey on Transformer Compression
Yehui Tang, Yunhe Wang, Jianyuan Guo, Zhijun Tu, Kai Han, Hailin Hu, Dacheng Tao
Transformer plays a vital role in the realms of natural language processing (NLP) and computer vision (CV), specially for constructing large language models (LLM) and large vision models (LVM). Model compression methods reduce the memory and computational cost of Transformer, which is a necessary step to implement large language/vision models on practical devices. Given the unique architecture of Transformer, featuring alternative attention and feedforward neural network (FFN) modules, specific compression techniques are usually required. The efficiency of these compression methods is also paramount, as retraining large models on the entire training dataset is usually impractical. This survey provides a comprehensive review of recent compression methods, with a specific focus on their application to Transformer-based models. The compression methods are primarily categorized into pruning, quantization, knowledge distillation, and efficient architecture design (Mamba, RetNet, RWKV, etc.). In each category, we discuss compression methods for both language and vision tasks, highlighting common underlying principles. Finally, we delve into the relation between various compression methods, and discuss further directions in this domain.
Read more4/9/2024
👨🏫
0
Transformer-Aided Semantic Communications
Matin Mortaheb, Erciyes Karakaya, Mohammad A. Amir Khojastepour, Sennur Ulukus
The transformer structure employed in large language models (LLMs), as a specialized category of deep neural networks (DNNs) featuring attention mechanisms, stands out for their ability to identify and highlight the most relevant aspects of input data. Such a capability is particularly beneficial in addressing a variety of communication challenges, notably in the realm of semantic communication where proper encoding of the relevant data is critical especially in systems with limited bandwidth. In this work, we employ vision transformers specifically for the purpose of compression and compact representation of the input image, with the goal of preserving semantic information throughout the transmission process. Through the use of the attention mechanism inherent in transformers, we create an attention mask. This mask effectively prioritizes critical segments of images for transmission, ensuring that the reconstruction phase focuses on key objects highlighted by the mask. Our methodology significantly improves the quality of semantic communication and optimizes bandwidth usage by encoding different parts of the data in accordance with their semantic information content, thus enhancing overall efficiency. We evaluate the effectiveness of our proposed framework using the TinyImageNet dataset, focusing on both reconstruction quality and accuracy. Our evaluation results demonstrate that our framework successfully preserves semantic information, even when only a fraction of the encoded data is transmitted, according to the intended compression rates.
Read more5/3/2024