Attention-Driven Training-Free Efficiency Enhancement of Diffusion Models
2405.05252
0
1
🛸
Abstract
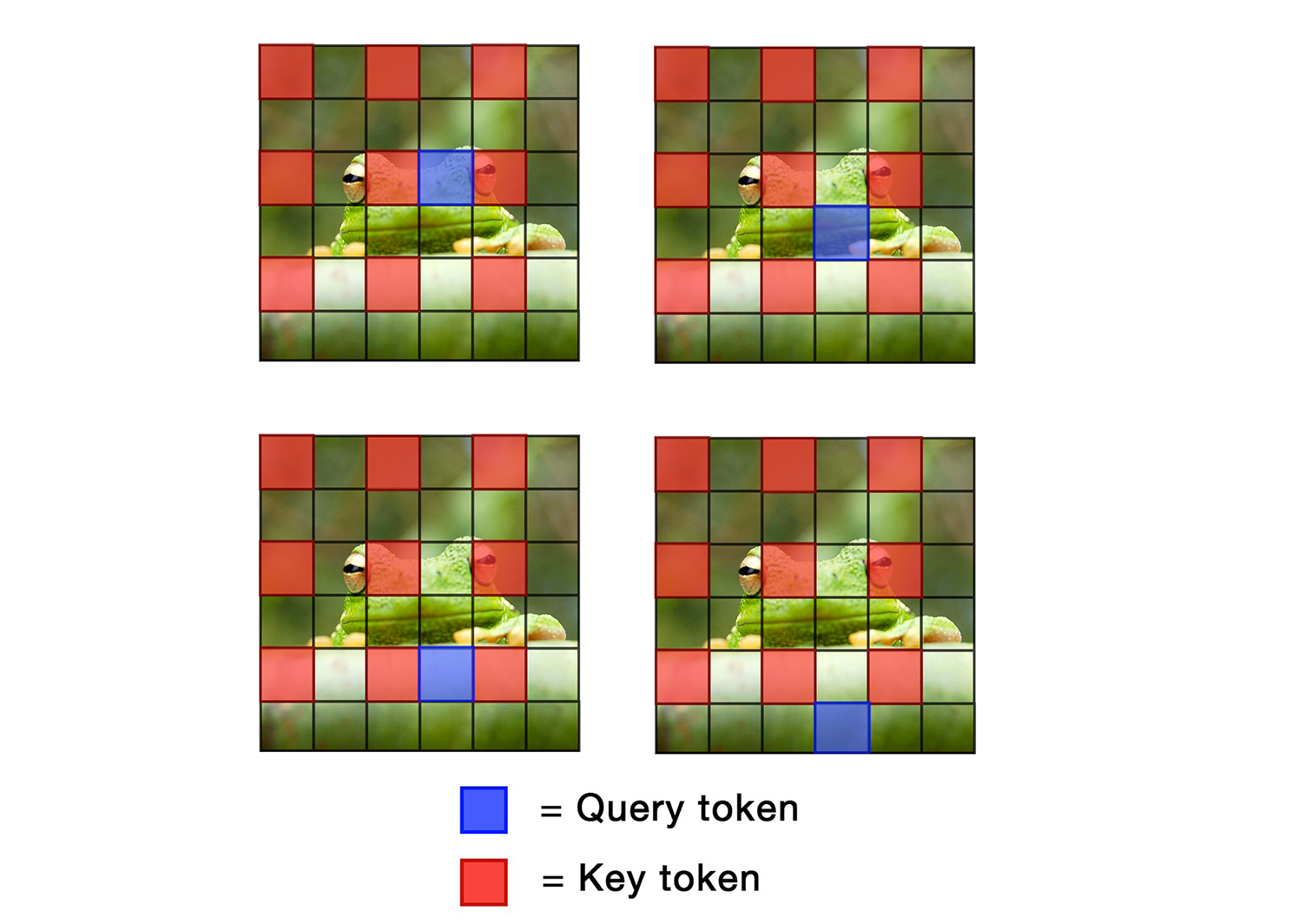
Diffusion Models (DMs) have exhibited superior performance in generating high-quality and diverse images. However, this exceptional performance comes at the cost of expensive architectural design, particularly due to the attention module heavily used in leading models. Existing works mainly adopt a retraining process to enhance DM efficiency. This is computationally expensive and not very scalable. To this end, we introduce the Attention-driven Training-free Efficient Diffusion Model (AT-EDM) framework that leverages attention maps to perform run-time pruning of redundant tokens, without the need for any retraining. Specifically, for single-denoising-step pruning, we develop a novel ranking algorithm, Generalized Weighted Page Rank (G-WPR), to identify redundant tokens, and a similarity-based recovery method to restore tokens for the convolution operation. In addition, we propose a Denoising-Steps-Aware Pruning (DSAP) approach to adjust the pruning budget across different denoising timesteps for better generation quality. Extensive evaluations show that AT-EDM performs favorably against prior art in terms of efficiency (e.g., 38.8% FLOPs saving and up to 1.53x speed-up over Stable Diffusion XL) while maintaining nearly the same FID and CLIP scores as the full model. Project webpage: https://atedm.github.io.
Create account to get full access
Overview
- Diffusion Models (DMs) have shown impressive performance in generating high-quality and diverse images.
- However, the leading DM models rely heavily on attention modules, which can be computationally expensive.
- Existing methods to improve DM efficiency often involve retraining the model, which is costly and not very scalable.
Plain English Explanation
Diffusion Models (DMs) are a type of machine learning model that can generate very realistic and varied images. They have become increasingly popular due to their impressive performance. However, the most successful DM models use a lot of computational power, particularly because of the attention mechanism they employ. Attention-driven Training-free Efficient Diffusion Model (AT-EDM) is a new framework that aims to make DMs more efficient without the need for retraining, which can be time-consuming and expensive.
Technical Explanation
The key idea behind AT-EDM is to use attention maps to identify and remove redundant tokens during the image generation process, without having to retrain the entire model. Specifically, the researchers developed a novel ranking algorithm called Generalized Weighted Page Rank (G-WPR) to identify the least important tokens, and a similarity-based recovery method to restore some of these tokens for the convolution operation.
Additionally, the researchers proposed a Denoising-Steps-Aware Pruning (DSAP) approach to adjust the pruning budget across different denoising timesteps, which helps maintain the generation quality. Extensive evaluations showed that AT-EDM can achieve significant efficiency gains, such as 38.8% FLOPs (floating-point operations) savings and up to 1.53x speed-up over the Stable Diffusion XL model, while maintaining similar image quality metrics (FID and CLIP scores) as the full model.
Critical Analysis
The AT-EDM framework provides a promising approach to improving the efficiency of Diffusion Models without the need for retraining. By leveraging attention maps to identify and prune redundant tokens, the researchers have found a way to reduce the computational cost of these models. However, the paper does not address the potential impact of this pruning on the diversity or fidelity of the generated images, which could be an important consideration.
Additionally, the researchers mention that the pruning approach may be sensitive to the specific architecture and hyperparameters of the DM model. This could limit the generalizability of the AT-EDM framework and require further investigation into its applicability to a wider range of DM models.
Conclusion
The Attention-driven Training-free Efficient Diffusion Model (AT-EDM) framework presents a novel and efficient way to improve the performance of Diffusion Models without the need for expensive retraining. By leveraging attention maps to prune redundant tokens, AT-EDM can achieve significant efficiency gains while maintaining the generation quality of the full model. This research could pave the way for more accessible and practical deployment of Diffusion Models in real-world applications, particularly where computational resources are constrained.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏷️
EfficientDM: Efficient Quantization-Aware Fine-Tuning of Low-Bit Diffusion Models
Yefei He, Jing Liu, Weijia Wu, Hong Zhou, Bohan Zhuang
0
0
Diffusion models have demonstrated remarkable capabilities in image synthesis and related generative tasks. Nevertheless, their practicality for real-world applications is constrained by substantial computational costs and latency issues. Quantization is a dominant way to compress and accelerate diffusion models, where post-training quantization (PTQ) and quantization-aware training (QAT) are two main approaches, each bearing its own properties. While PTQ exhibits efficiency in terms of both time and data usage, it may lead to diminished performance in low bit-width. On the other hand, QAT can alleviate performance degradation but comes with substantial demands on computational and data resources. In this paper, we introduce a data-free and parameter-efficient fine-tuning framework for low-bit diffusion models, dubbed EfficientDM, to achieve QAT-level performance with PTQ-like efficiency. Specifically, we propose a quantization-aware variant of the low-rank adapter (QALoRA) that can be merged with model weights and jointly quantized to low bit-width. The fine-tuning process distills the denoising capabilities of the full-precision model into its quantized counterpart, eliminating the requirement for training data. We also introduce scale-aware optimization and temporal learned step-size quantization to further enhance performance. Extensive experimental results demonstrate that our method significantly outperforms previous PTQ-based diffusion models while maintaining similar time and data efficiency. Specifically, there is only a 0.05 sFID increase when quantizing both weights and activations of LDM-4 to 4-bit on ImageNet 256x256. Compared to QAT-based methods, our EfficientDM also boasts a 16.2x faster quantization speed with comparable generation quality. Code is available at href{https://github.com/ThisisBillhe/EfficientDM}{this hrl}.
4/16/2024
🔮
Denoising Diffusion Step-aware Models
Shuai Yang, Yukang Chen, Luozhou Wang, Shu Liu, Yingcong Chen
0
0
Denoising Diffusion Probabilistic Models (DDPMs) have garnered popularity for data generation across various domains. However, a significant bottleneck is the necessity for whole-network computation during every step of the generative process, leading to high computational overheads. This paper presents a novel framework, Denoising Diffusion Step-aware Models (DDSM), to address this challenge. Unlike conventional approaches, DDSM employs a spectrum of neural networks whose sizes are adapted according to the importance of each generative step, as determined through evolutionary search. This step-wise network variation effectively circumvents redundant computational efforts, particularly in less critical steps, thereby enhancing the efficiency of the diffusion model. Furthermore, the step-aware design can be seamlessly integrated with other efficiency-geared diffusion models such as DDIMs and latent diffusion, thus broadening the scope of computational savings. Empirical evaluations demonstrate that DDSM achieves computational savings of 49% for CIFAR-10, 61% for CelebA-HQ, 59% for LSUN-bedroom, 71% for AFHQ, and 76% for ImageNet, all without compromising the generation quality.
5/27/2024
ToDo: Token Downsampling for Efficient Generation of High-Resolution Images
Ethan Smith, Nayan Saxena, Aninda Saha
0
0
Attention mechanism has been crucial for image diffusion models, however, their quadratic computational complexity limits the sizes of images we can process within reasonable time and memory constraints. This paper investigates the importance of dense attention in generative image models, which often contain redundant features, making them suitable for sparser attention mechanisms. We propose a novel training-free method ToDo that relies on token downsampling of key and value tokens to accelerate Stable Diffusion inference by up to 2x for common sizes and up to 4.5x or more for high resolutions like 2048x2048. We demonstrate that our approach outperforms previous methods in balancing efficient throughput and fidelity.
5/9/2024
🧠
Perturbing Attention Gives You More Bang for the Buck: Subtle Imaging Perturbations That Efficiently Fool Customized Diffusion Models
Jingyao Xu, Yuetong Lu, Yandong Li, Siyang Lu, Dongdong Wang, Xiang Wei
0
0
Diffusion models (DMs) embark a new era of generative modeling and offer more opportunities for efficient generating high-quality and realistic data samples. However, their widespread use has also brought forth new challenges in model security, which motivates the creation of more effective adversarial attackers on DMs to understand its vulnerability. We propose CAAT, a simple but generic and efficient approach that does not require costly training to effectively fool latent diffusion models (LDMs). The approach is based on the observation that cross-attention layers exhibits higher sensitivity to gradient change, allowing for leveraging subtle perturbations on published images to significantly corrupt the generated images. We show that a subtle perturbation on an image can significantly impact the cross-attention layers, thus changing the mapping between text and image during the fine-tuning of customized diffusion models. Extensive experiments demonstrate that CAAT is compatible with diverse diffusion models and outperforms baseline attack methods in a more effective (more noise) and efficient (twice as fast as Anti-DreamBooth and Mist) manner.
6/17/2024