Audio-Language Datasets of Scenes and Events: A Survey

0

Sign in to get full access
Overview
- This paper provides a comprehensive survey of audio-language datasets that capture scenes and events.
- These datasets are crucial for developing multimodal AI models that can understand and interact with the world through both audio and language.
- The survey covers a wide range of datasets, from those focused on specific domains like AudioSetMix to those aiming to be more general like AudioBench.
- The paper also discusses the practical aspects of creating audio-language datasets, as well as emerging trends and future directions in this field.
Plain English Explanation
Audio and language are two of the most natural ways for humans to perceive and interact with the world around them. By combining these modalities, researchers can develop AI systems that can better understand and respond to the complexity of real-world situations.
The paper examines a variety of datasets that capture audio and language information about different scenes and events. For example, some datasets focus on specific domains like audio dialogues or audio-language mixtures, while others aim to be more general and cover a wide range of everyday experiences.
By reviewing these datasets, the authors provide insights into the practical challenges of creating high-quality audio-language datasets, as well as emerging trends and future directions in this field. This information can help researchers and developers build more effective AI systems that can seamlessly integrate audio and language understanding.
Technical Explanation
The paper begins by providing background on the importance of audio-language datasets for developing multimodal AI models. It then presents a comprehensive survey of various datasets in this domain, including their focus, data collection methods, and key features.
The survey covers datasets that capture specific types of audio-language interactions, such as dialogues or audio-language mixtures. It also examines more general datasets that aim to cover a broader range of scenes and events, like AudioBench.
The paper then delves into the practical aspects of creating audio-language datasets, drawing on insights from the Practical Aspects of Creation of Audio Dataset from Field paper. This includes considerations around data collection, annotation, and curation.
Finally, the paper discusses emerging trends and future directions in the field of audio-language datasets, such as the need for more diverse and inclusive datasets, as well as the use of techniques like CodecFake to address potential audio forgery issues.
Critical Analysis
The survey provides a comprehensive overview of the current landscape of audio-language datasets, highlighting the diverse range of datasets available and the key considerations in their creation. However, the paper also acknowledges some of the limitations and challenges in this field.
One potential issue is the lack of diversity in many of the existing datasets, which may not adequately represent the full range of real-world audio-language interactions. The authors suggest that future work should focus on developing more inclusive and representative datasets.
Additionally, the paper notes the potential for audio forgery, such as through the use of techniques like CodecFake, which could undermine the reliability and trustworthiness of audio-language datasets. Addressing this challenge will be an important area of future research.
Overall, the survey provides a valuable resource for researchers and developers in the field of multimodal AI, highlighting the key datasets and the critical challenges that need to be addressed to advance the state of the art.
Conclusion
This paper offers a comprehensive survey of audio-language datasets that capture scenes and events. These datasets are essential for developing AI systems that can seamlessly integrate audio and language understanding, enabling them to better perceive and interact with the world.
The survey covers a wide range of datasets, from those focused on specific domains to more general ones. It also discusses the practical aspects of creating high-quality audio-language datasets, as well as emerging trends and future directions in this field.
By providing this overview, the authors offer valuable insights that can guide researchers and developers in building more effective multimodal AI systems. As the field of audio-language learning continues to evolve, this survey serves as a valuable resource for understanding the current state of the art and the key challenges that need to be addressed.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Audio-Language Datasets of Scenes and Events: A Survey
Gijs Wijngaard, Elia Formisano, Michele Esposito, Michel Dumontier
Audio-language models (ALMs) process sounds to provide a linguistic description of sound-producing events and scenes. Recent advances in computing power and dataset creation have led to significant progress in this domain. This paper surveys existing datasets used for training audio-language models, emphasizing the recent trend towards using large, diverse datasets to enhance model performance. Key sources of these datasets include the Freesound platform and AudioSet that have contributed to the field's rapid growth. Although prior surveys primarily address techniques and training details, this survey categorizes and evaluates a wide array of datasets, addressing their origins, characteristics, and use cases. It also performs a data leak analysis to ensure dataset integrity and mitigate bias between datasets. This survey was conducted by analyzing research papers up to and including December 2023, and does not contain any papers after that period.
Read more7/10/2024

0
Practical aspects for the creation of an audio dataset from field recordings with optimized labeling budget with AI-assisted strategy
Javier Naranjo-Alcazar, Jordi Grau-Haro, Ruben Ribes-Serrano, Pedro Zuccarello
Machine Listening focuses on developing technologies to extract relevant information from audio signals. A critical aspect of these projects is the acquisition and labeling of contextualized data, which is inherently complex and requires specific resources and strategies. Despite the availability of some audio datasets, many are unsuitable for commercial applications. The paper emphasizes the importance of Active Learning (AL) using expert labelers over crowdsourcing, which often lacks detailed insights into dataset structures. AL is an iterative process combining human labelers and AI models to optimize the labeling budget by intelligently selecting samples for human review. This approach addresses the challenge of handling large, constantly growing datasets that exceed available computational resources and memory. The paper presents a comprehensive data-centric framework for Machine Listening projects, detailing the configuration of recording nodes, database structure, and labeling budget optimization in resource-constrained scenarios. Applied to an industrial port in Valencia, Spain, the framework successfully labeled 6540 ten-second audio samples over five months with a small team, demonstrating its effectiveness and adaptability to various resource availability situations. Acknowledgments: The participation of Javier Naranjo-Alcazar, Jordi Grau-Haro and Pedro Zuccarello in this research was funded by the Valencian Institute for Business Competitiveness (IVACE) and the FEDER funds by means of project Soroll-IA2 (IMDEEA/2023/91).
Read more8/1/2024

0
AudioSetMix: Enhancing Audio-Language Datasets with LLM-Assisted Augmentations
David Xu
Multi-modal learning in the audio-language domain has seen significant advancements in recent years. However, audio-language learning faces challenges due to limited and lower-quality data compared to image-language tasks. Existing audio-language datasets are notably smaller, and manual labeling is hindered by the need to listen to entire audio clips for accurate labeling. Our method systematically generates audio-caption pairs by augmenting audio clips with natural language labels and corresponding audio signal processing operations. Leveraging a Large Language Model, we generate descriptions of augmented audio clips with a prompt template. This scalable method produces AudioSetMix, a high-quality training dataset for text-and-audio related models. Integration of our dataset improves models performance on benchmarks by providing diversified and better-aligned examples. Notably, our dataset addresses the absence of modifiers (adjectives and adverbs) in existing datasets. By enabling models to learn these concepts, and generating hard negative examples during training, we achieve state-of-the-art performance on multiple benchmarks.
Read more6/10/2024
0
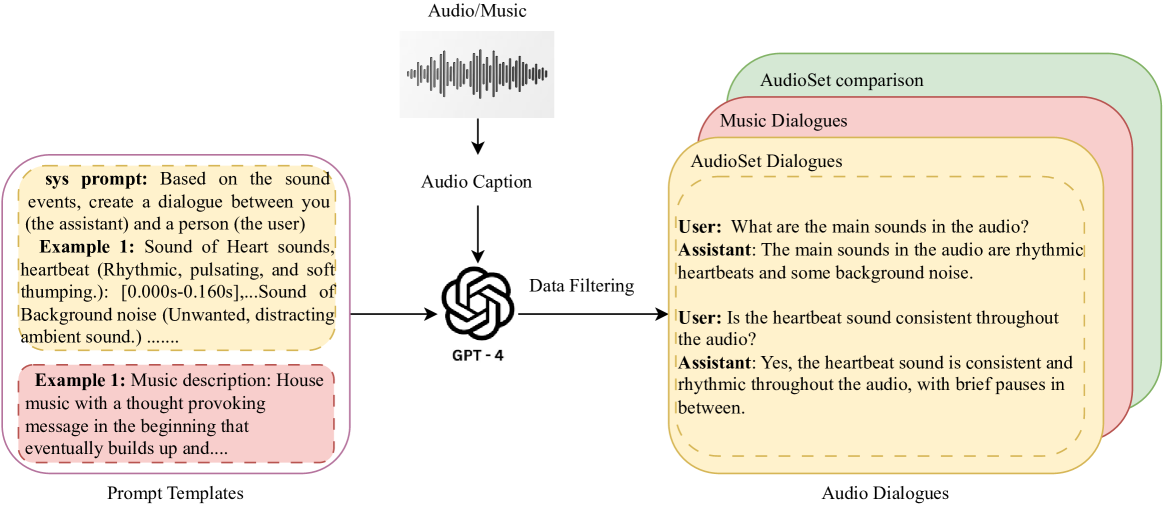
Audio Dialogues: Dialogues dataset for audio and music understanding
Arushi Goel, Zhifeng Kong, Rafael Valle, Bryan Catanzaro
Existing datasets for audio understanding primarily focus on single-turn interactions (i.e. audio captioning, audio question answering) for describing audio in natural language, thus limiting understanding audio via interactive dialogue. To address this gap, we introduce Audio Dialogues: a multi-turn dialogue dataset containing 163.8k samples for general audio sounds and music. In addition to dialogues, Audio Dialogues also has question-answer pairs to understand and compare multiple input audios together. Audio Dialogues leverages a prompting-based approach and caption annotations from existing datasets to generate multi-turn dialogues using a Large Language Model (LLM). We evaluate existing audio-augmented large language models on our proposed dataset to demonstrate the complexity and applicability of Audio Dialogues. Our code for generating the dataset will be made publicly available. Detailed prompts and generated dialogues can be found on the demo website https://audiodialogues.github.io/.
Read more4/12/2024