AudioBench: A Universal Benchmark for Audio Large Language Models

0

Sign in to get full access
Overview
- This paper introduces AudioBench, a comprehensive benchmark for evaluating the performance of audio large language models (ALLMs) on a wide range of audio-related tasks.
- AudioBench covers a diverse set of tasks, including audio classification, audio captioning, audio-based question answering, and audio-to-text generation.
- The authors argue that AudioBench provides a more holistic assessment of ALLM capabilities compared to existing benchmarks.
Plain English Explanation
The paper describes a new benchmark called AudioBench that is designed to comprehensively evaluate the abilities of audio large language models (ALLMs) - models that can process and generate audio data. Unlike previous benchmarks that focused on more narrow tasks, AudioBench covers a wide variety of audio-related challenges, including recognizing different types of audio, generating captions for audio clips, answering questions about audio, and assessing phonological skills. The authors believe this more holistic approach will provide a better understanding of an ALLM's true capabilities compared to previous, more limited benchmarks. By testing models on this diverse set of audio-focused tasks, researchers and developers can get a more comprehensive view of how well these models can handle real-world audio-based applications and challenges.
Technical Explanation
The paper introduces AudioBench, a new benchmark designed to comprehensively evaluate the capabilities of audio large language models (ALLMs). The benchmark includes a diverse set of tasks that cover various aspects of audio processing and understanding, including audio classification, audio captioning, audio-based question answering, and phonological skill assessment. The authors argue that this broad coverage provides a more holistic assessment of ALLM capabilities compared to previous benchmarks that focused on more narrow tasks.
The paper details the design and composition of the AudioBench dataset, which includes audio samples, associated text data, and a wide range of task-specific annotations. The authors also describe the evaluation metrics used to assess ALLM performance across the different tasks.
Critical Analysis
The AudioBench benchmark represents a significant advancement in the evaluation of audio large language models (ALLMs). By covering a diverse set of audio-related tasks, the benchmark provides a more comprehensive assessment of model capabilities compared to previous, more narrowly focused benchmarks.
However, the paper does acknowledge some limitations of the current version of AudioBench. For example, the dataset may not fully capture the breadth of audio data and tasks encountered in real-world applications. Additionally, the authors note that the benchmark does not yet include certain advanced audio processing capabilities, such as understanding long-form video, that may be important for some use cases.
Further research and refinement of the benchmark could address these limitations and continue to push the field of ALLM evaluation forward. Ongoing development and expansion of AudioBench, as well as the adoption of the benchmark by the broader research community, will be important for ensuring a robust and comprehensive assessment of these increasingly important models.
Conclusion
The AudioBench benchmark introduced in this paper represents a significant advancement in the evaluation of audio large language models (ALLMs). By covering a diverse range of audio-related tasks, the benchmark provides a more holistic and comprehensive assessment of ALLM capabilities compared to previous, more narrowly focused benchmarks.
The wide-ranging tasks included in AudioBench, such as audio classification, captioning, question answering, and phonological skill assessment, will help researchers and developers better understand the strengths and limitations of ALLMs. This information can then be used to guide the development of more capable and versatile models that can be effectively deployed in real-world audio-based applications and systems.
Overall, the AudioBench benchmark is a valuable contribution to the field of ALLM evaluation and has the potential to drive significant progress in the development of these increasingly important models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AudioBench: A Universal Benchmark for Audio Large Language Models
Bin Wang, Xunlong Zou, Geyu Lin, Shuo Sun, Zhuohan Liu, Wenyu Zhang, Zhengyuan Liu, AiTi Aw, Nancy F. Chen
We introduce AudioBench, a universal benchmark designed to evaluate Audio Large Language Models (AudioLLMs). It encompasses 8 distinct tasks and 26 datasets, among which, 7 are newly proposed datasets. The evaluation targets three main aspects: speech understanding, audio scene understanding, and voice understanding (paralinguistic). Despite recent advancements, there lacks a comprehensive benchmark for AudioLLMs on instruction following capabilities conditioned on audio signals. AudioBench addresses this gap by setting up datasets as well as desired evaluation metrics. Besides, we also evaluated the capabilities of five popular models and found that no single model excels consistently across all tasks. We outline the research outlook for AudioLLMs and anticipate that our open-sourced evaluation toolkit, data, and leaderboard will offer a robust testbed for future model developments.
Read more9/4/2024

0
AIR-Bench: Benchmarking Large Audio-Language Models via Generative Comprehension
Qian Yang, Jin Xu, Wenrui Liu, Yunfei Chu, Ziyue Jiang, Xiaohuan Zhou, Yichong Leng, Yuanjun Lv, Zhou Zhao, Chang Zhou, Jingren Zhou
Recently, instruction-following audio-language models have received broad attention for human-audio interaction. However, the absence of benchmarks capable of evaluating audio-centric interaction capabilities has impeded advancements in this field. Previous models primarily focus on assessing different fundamental tasks, such as Automatic Speech Recognition (ASR), and lack an assessment of the open-ended generative capabilities centered around audio. Thus, it is challenging to track the progression in the Large Audio-Language Models (LALMs) domain and to provide guidance for future improvement. In this paper, we introduce AIR-Bench (textbf{A}udio textbf{I}nsttextbf{R}uction textbf{Bench}mark), the first benchmark designed to evaluate the ability of LALMs to understand various types of audio signals (including human speech, natural sounds, and music), and furthermore, to interact with humans in the textual format. AIR-Bench encompasses two dimensions: textit{foundation} and textit{chat} benchmarks. The former consists of 19 tasks with approximately 19k single-choice questions, intending to inspect the basic single-task ability of LALMs. The latter one contains 2k instances of open-ended question-and-answer data, directly assessing the comprehension of the model on complex audio and its capacity to follow instructions. Both benchmarks require the model to generate hypotheses directly. We design a unified framework that leverages advanced language models, such as GPT-4, to evaluate the scores of generated hypotheses given the meta-information of the audio. Experimental results demonstrate a high level of consistency between GPT-4-based evaluation and human evaluation. By revealing the limitations of existing LALMs through evaluation results, AIR-Bench can provide insights into the direction of future research.
Read more7/29/2024
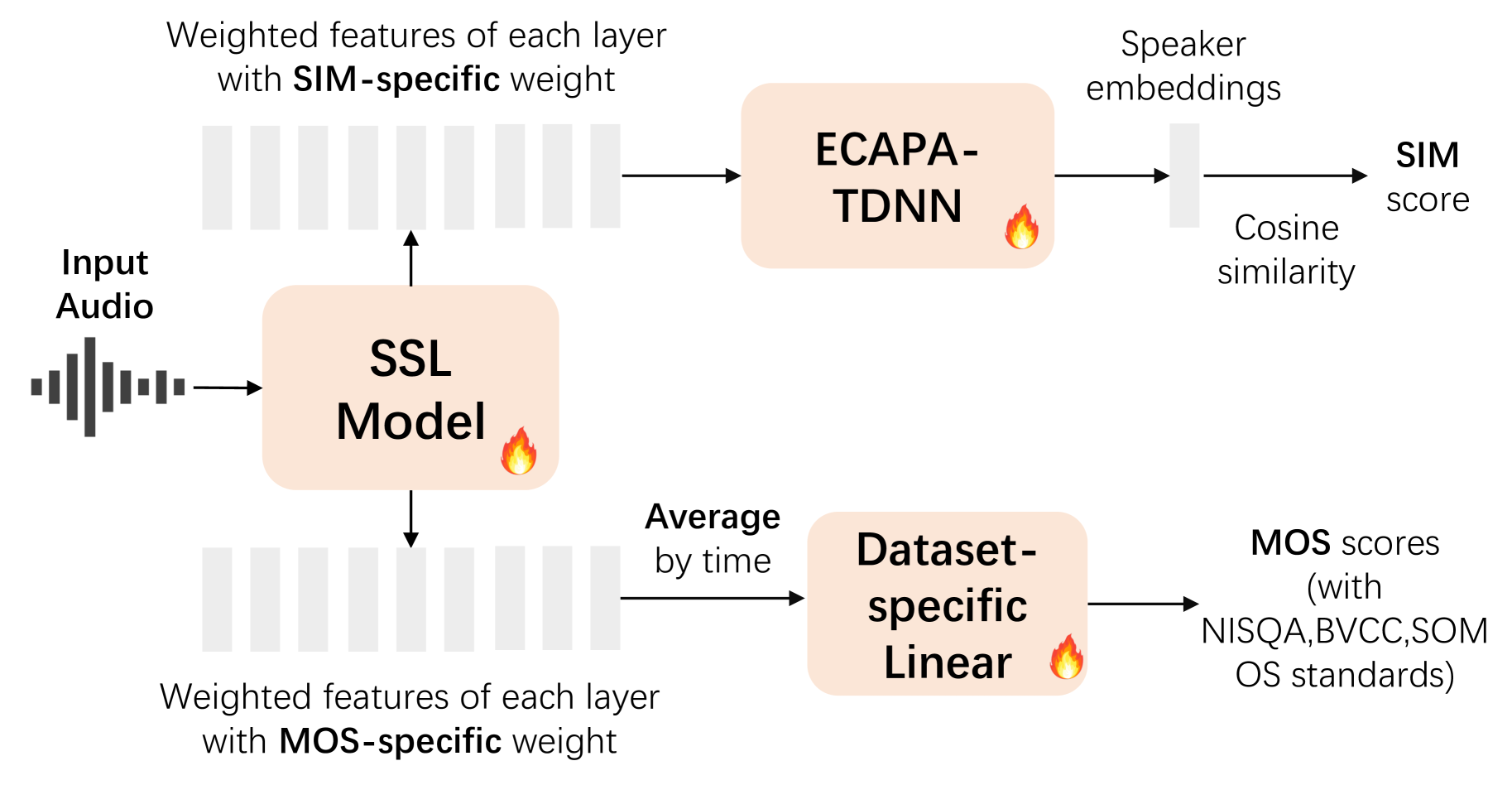
0
Enabling Auditory Large Language Models for Automatic Speech Quality Evaluation
Siyin Wang, Wenyi Yu, Yudong Yang, Changli Tang, Yixuan Li, Jimin Zhuang, Xianzhao Chen, Xiaohai Tian, Jun Zhang, Guangzhi Sun, Lu Lu, Chao Zhang
Speech quality assessment typically requires evaluating audio from multiple aspects, such as mean opinion score (MOS) and speaker similarity (SIM) etc., which can be challenging to cover using one small model designed for a single task. In this paper, we propose leveraging recently introduced auditory large language models (LLMs) for automatic speech quality assessment. By employing task-specific prompts, auditory LLMs are finetuned to predict MOS, SIM and A/B testing results, which are commonly used for evaluating text-to-speech systems. Additionally, the finetuned auditory LLM is able to generate natural language descriptions assessing aspects like noisiness, distortion, discontinuity, and overall quality, providing more interpretable outputs. Extensive experiments have been performed on the NISQA, BVCC, SOMOS and VoxSim speech quality datasets, using open-source auditory LLMs such as SALMONN, Qwen-Audio, and Qwen2-Audio. For the natural language descriptions task, a commercial model Google Gemini 1.5 Pro is also evaluated. The results demonstrate that auditory LLMs achieve competitive performance compared to state-of-the-art task-specific small models in predicting MOS and SIM, while also delivering promising results in A/B testing and natural language descriptions. Our data processing scripts and finetuned model checkpoints will be released upon acceptance.
Read more9/26/2024
⚙️
0
New!Beyond Single-Audio: Advancing Multi-Audio Processing in Audio Large Language Models
Yiming Chen, Xianghu Yue, Xiaoxue Gao, Chen Zhang, Luis Fernando D'Haro, Robby T. Tan, Haizhou Li
Various audio-LLMs (ALLMs) have been explored recently for tackling different audio tasks simultaneously using a single, unified model. While existing evaluations of ALLMs primarily focus on single-audio tasks, real-world applications often involve processing multiple audio streams simultaneously. To bridge this gap, we propose the first multi-audio evaluation (MAE) benchmark that consists of 20 datasets from 11 multi-audio tasks encompassing both speech and sound scenarios. Comprehensive experiments on MAE demonstrate that the existing ALLMs, while being powerful in comprehending primary audio elements in individual audio inputs, struggling to handle multi-audio scenarios. To this end, we propose a novel multi-audio-LLM (MALLM) to capture audio context among multiple similar audios using discriminative learning on our proposed synthetic data. The results demonstrate that the proposed MALLM outperforms all baselines and achieves high data efficiency using synthetic data without requiring human annotations. The proposed MALLM opens the door for ALLMs towards multi-audio processing era and brings us closer to replicating human auditory capabilities in machines.
Read more9/30/2024