Audio Match Cutting: Finding and Creating Matching Audio Transitions in Movies and Videos

0

Sign in to get full access
Overview
- This research paper explores a novel method called "Audio Match Cutting" for finding and creating matching audio transitions in movies and videos.
- The key idea is to automatically detect visually and aurally coherent transitions in video, allowing for seamless splicing and editing.
- The method involves analyzing the audio and visual signals to identify matching transition points, enabling smooth transitions between different video clips.
Plain English Explanation
The paper presents a way to automatically detect when the audio and video in a movie or video are in sync, or "match up." This allows editors to easily splice different video clips together without any jarring transitions.
For example, imagine you have a video that cuts from a busy city street to a quiet countryside scene. Normally, this transition might sound abrupt. But with the "Audio Match Cutting" method, the system can find the points in the audio where the transition would sound smooth, allowing the editor to line up the video clips at those spots. This creates a seamless, natural-sounding transition that the viewer barely notices.
The key is analyzing both the audio and visual signals to identify matching transition points. The audio might have a fade-out or other cue that lines up perfectly with a visual change, and the system can detect these sync points. This enables editors to stitch together video clips in a way that maintains the flow and continuity of the overall video.
Technical Explanation
The paper introduces an "Audio Match Cutting" technique that automatically identifies visually and aurally coherent transition points in video. The core idea is to analyze the audio and visual signals in a video to detect synchronization cues that indicate a good spot to transition between different video clips.
The method works by first extracting audio and visual features from the input video. It then aligns these features to identify points where the audio and video "match up" in a seamless way. Finally, it generates candidate transition points based on this alignment, allowing editors to splice the video clips together at those locations.
The key innovation is leveraging both the audio and visual signals to find optimal transition points, rather than relying on just one modality. This multimodal approach allows the system to detect transitions that maintain the overall continuity and flow of the video.
Critical Analysis
The paper presents a promising approach for automating a common but tedious task in video editing. By automatically detecting coherent transition points, the "Audio Match Cutting" method could significantly speed up the editing process and lead to more seamless final videos.
However, the paper does not extensively evaluate the approach on a wide range of video types or in comparison to human editors. More research would be needed to fully understand the strengths and limitations of the technique.
Additionally, the current implementation relies on pre-extracted audio and visual features, which may not always be available. Extending the method to work directly on raw video and audio data could increase its real-world applicability.
Conclusion
This paper introduces an innovative "Audio Match Cutting" technique for automatically finding and creating matching audio transitions in movies and videos. By analyzing both the audio and visual signals, the method can identify optimal points to splice video clips together in a seamless way.
While more research is needed to fully evaluate the approach, this work represents an important step towards automating a common video editing task. If further developed, the "Audio Match Cutting" method could save editors significant time and effort, leading to more polished final products.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Audio Match Cutting: Finding and Creating Matching Audio Transitions in Movies and Videos
Dennis Fedorishin, Lie Lu, Srirangaraj Setlur, Venu Govindaraju
A match cut is a common video editing technique where a pair of shots that have a similar composition transition fluidly from one to another. Although match cuts are often visual, certain match cuts involve the fluid transition of audio, where sounds from different sources merge into one indistinguishable transition between two shots. In this paper, we explore the ability to automatically find and create audio match cuts within videos and movies. We create a self-supervised audio representation for audio match cutting and develop a coarse-to-fine audio match pipeline that recommends matching shots and creates the blended audio. We further annotate a dataset for the proposed audio match cut task and compare the ability of multiple audio representations to find audio match cut candidates. Finally, we evaluate multiple methods to blend two matching audio candidates with the goal of creating a smooth transition. Project page and examples are available at: https://denfed.github.io/audiomatchcut/
Read more8/21/2024
🏅
0
Soundify: Matching Sound Effects to Video
David Chuan-En Lin, Anastasis Germanidis, Crist'obal Valenzuela, Yining Shi, Nikolas Martelaro
In the art of video editing, sound helps add character to an object and immerse the viewer within a space. Through formative interviews with professional editors (N=10), we found that the task of adding sounds to video can be challenging. This paper presents Soundify, a system that assists editors in matching sounds to video. Given a video, Soundify identifies matching sounds, synchronizes the sounds to the video, and dynamically adjusts panning and volume to create spatial audio. In a human evaluation study (N=889), we show that Soundify is capable of matching sounds to video out-of-the-box for a diverse range of audio categories. In a within-subjects expert study (N=12), we demonstrate the usefulness of Soundify in helping video editors match sounds to video with lighter workload, reduced task completion time, and improved usability.
Read more6/26/2024
🏅
0
Looking Similar, Sounding Different: Leveraging Counterfactual Cross-Modal Pairs for Audiovisual Representation Learning
Nikhil Singh, Chih-Wei Wu, Iroro Orife, Mahdi Kalayeh
Audiovisual representation learning typically relies on the correspondence between sight and sound. However, there are often multiple audio tracks that can correspond with a visual scene. Consider, for example, different conversations on the same crowded street. The effect of such counterfactual pairs on audiovisual representation learning has not been previously explored. To investigate this, we use dubbed versions of movies and television shows to augment cross-modal contrastive learning. Our approach learns to represent alternate audio tracks, differing only in speech, similarly to the same video. Our results, from a comprehensive set of experiments investigating different training strategies, show this general approach improves performance on a range of downstream auditory and audiovisual tasks, without majorly affecting linguistic task performance overall. These findings highlight the importance of considering speech variation when learning scene-level audiovisual correspondences and suggest that dubbed audio can be a useful augmentation technique for training audiovisual models toward more robust performance on diverse downstream tasks.
Read more6/11/2024
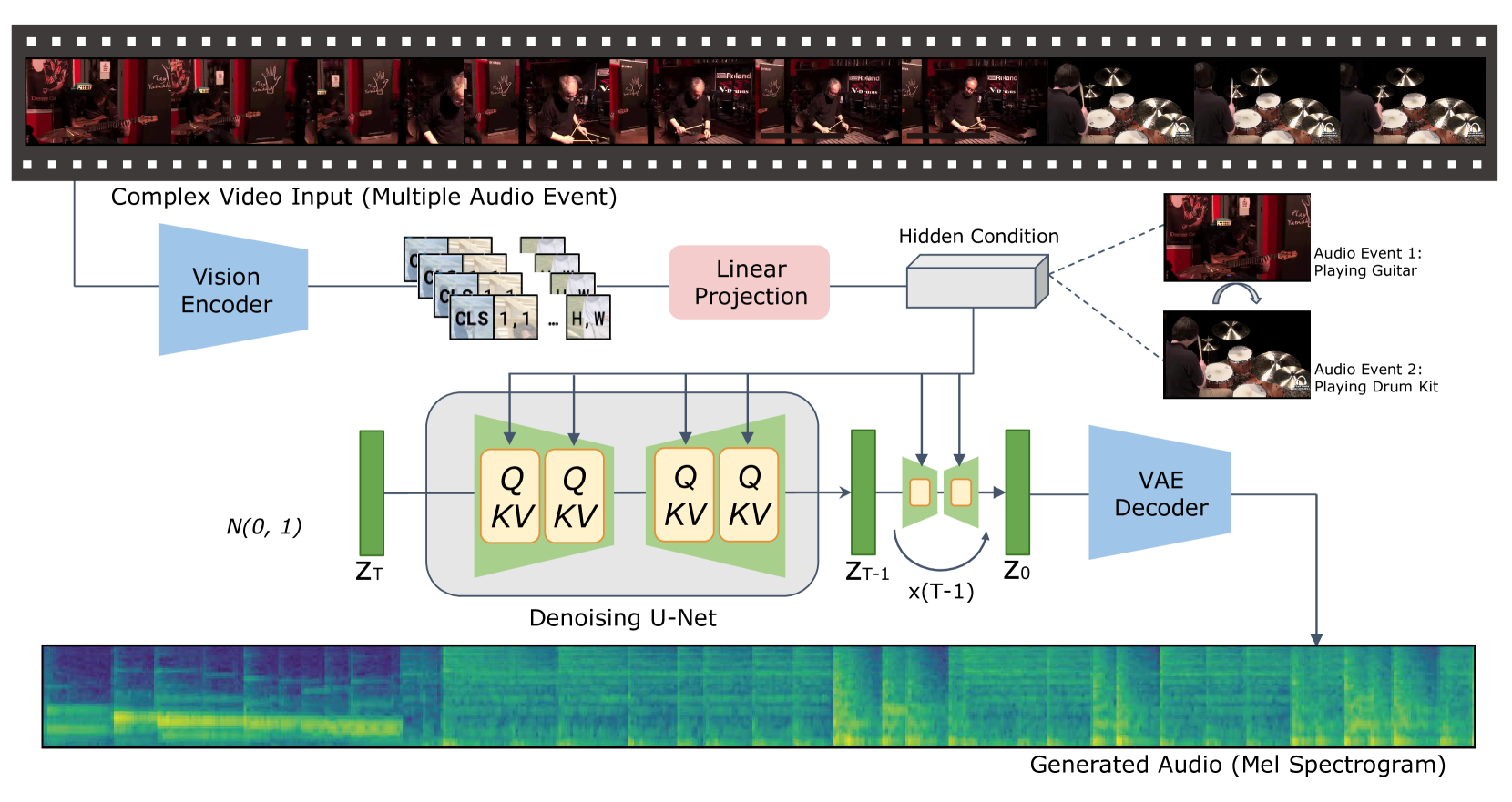
0
Video-to-Audio Generation with Hidden Alignment
Manjie Xu, Chenxing Li, Yong Ren, Rilin Chen, Yu Gu, Wei Liang, Dong Yu
Generating semantically and temporally aligned audio content in accordance with video input has become a focal point for researchers, particularly following the remarkable breakthrough in text-to-video generation. In this work, we aim to offer insights into the video-to-audio generation paradigm, focusing on three crucial aspects: vision encoders, auxiliary embeddings, and data augmentation techniques. Beginning with a foundational model VTA-LDM built on a simple yet surprisingly effective intuition, we explore various vision encoders and auxiliary embeddings through ablation studies. Employing a comprehensive evaluation pipeline that emphasizes generation quality and video-audio synchronization alignment, we demonstrate that our model exhibits state-of-the-art video-to-audio generation capabilities. Furthermore, we provide critical insights into the impact of different data augmentation methods on enhancing the generation framework's overall capacity. We showcase possibilities to advance the challenge of generating synchronized audio from semantic and temporal perspectives. We hope these insights will serve as a stepping stone toward developing more realistic and accurate audio-visual generation models.
Read more7/11/2024