Looking Similar, Sounding Different: Leveraging Counterfactual Cross-Modal Pairs for Audiovisual Representation Learning
2304.05600
0
0
🏅
Abstract
Audiovisual representation learning typically relies on the correspondence between sight and sound. However, there are often multiple audio tracks that can correspond with a visual scene. Consider, for example, different conversations on the same crowded street. The effect of such counterfactual pairs on audiovisual representation learning has not been previously explored. To investigate this, we use dubbed versions of movies and television shows to augment cross-modal contrastive learning. Our approach learns to represent alternate audio tracks, differing only in speech, similarly to the same video. Our results, from a comprehensive set of experiments investigating different training strategies, show this general approach improves performance on a range of downstream auditory and audiovisual tasks, without majorly affecting linguistic task performance overall. These findings highlight the importance of considering speech variation when learning scene-level audiovisual correspondences and suggest that dubbed audio can be a useful augmentation technique for training audiovisual models toward more robust performance on diverse downstream tasks.
Create account to get full access
Overview
- This paper explores how the presence of multiple audio tracks corresponding to a single visual scene can impact audiovisual representation learning.
- The researchers used "dubbed" versions of movies and TV shows - where the original audio is replaced with a different spoken dialogue - to augment cross-modal contrastive learning.
- Their approach learns to represent alternate audio tracks, differing only in speech, similarly to the same video.
- The results show this approach improves performance on a range of downstream auditory and audiovisual tasks, without significantly affecting linguistic task performance.
Plain English Explanation
When training AI models to understand the relationship between what we see and what we hear, researchers typically rely on the natural correspondence between visual scenes and their associated audio. However, in the real world, there are often multiple possible audio tracks that could match a single visual scene - for example, different conversations happening on a crowded street.
This paper investigated how accounting for this "counterfactual" audio-visual pairing could impact the AI's learning. The researchers used "dubbed" movie and TV show clips, where the original audio was replaced with different spoken dialogue, to train the model. This taught the AI to recognize that even though the audio was different, it still matched the same underlying visual scene.
The results showed that this approach led to improvements in the model's performance on a variety of tasks involving audio processing and combining audio-visual information. Importantly, this boost in performance did not come at the cost of the model's ability to understand language.
These findings highlight the importance of considering speech variation when trying to learn how visual scenes and audio go together. The researchers suggest that using dubbed audio can be a helpful technique for training more robust and flexible audiovisual AI models.
Technical Explanation
Typical audiovisual representation learning relies on the natural correspondence between what we see and what we hear in a scene. However, in many real-world situations, there can be multiple possible audio tracks that could match a single visual scene - for example, different conversations happening on a crowded street.
To explore the impact of these "counterfactual" audio-visual pairings, the researchers used "dubbed" versions of movies and TV shows, where the original audio was replaced with different spoken dialogue. They then employed this dubbed audio to augment a cross-modal contrastive learning approach, teaching the AI to represent alternate audio tracks, differing only in speech, similarly to the same video.
The researchers conducted a comprehensive set of experiments to investigate different training strategies. Their results showed that this general approach improved performance on a range of downstream auditory and audiovisual tasks, such as speech recognition, video-language understanding, and audio-visual scene classification. Importantly, this boost in performance did not significantly affect the model's linguistic task performance overall.
These findings highlight the importance of considering speech variation when learning audiovisual correspondences at the scene level. The researchers suggest that using dubbed audio can be a useful augmentation technique for training more robust audiovisual models capable of handling diverse downstream tasks.
Critical Analysis
The paper presents a novel approach to audiovisual representation learning that accounts for the presence of multiple possible audio tracks corresponding to a single visual scene. The researchers' use of dubbed movie and TV show clips as a source of counterfactual audio-visual pairings is a clever way to explore this phenomenon.
One potential limitation of the study is the reliance on scripted, edited media content rather than more naturalistic, real-world audio-visual data. It would be interesting to see how the approach performs on recordings of spontaneous conversations and ambient sounds in public spaces.
Additionally, while the researchers demonstrate improvements on a range of downstream tasks, they do not provide a detailed analysis of the specific types of errors or mistakes the model makes before and after their proposed training approach. A deeper dive into the model's strengths, weaknesses, and failure modes could offer additional insights.
Overall, this research highlights an important consideration for developing audiovisual AI systems that can robustly handle the complexity of real-world audio-visual environments. The use of counterfactual audio-visual pairs is a promising direction for future work in this area.
Conclusion
This paper explores a novel approach to audiovisual representation learning that accounts for the presence of multiple possible audio tracks corresponding to a single visual scene. By using "dubbed" movie and TV show clips to augment cross-modal contrastive learning, the researchers were able to train AI models to better represent the diversity of audio-visual correspondences in the real world.
The results show that this approach leads to improvements in a range of downstream auditory and audiovisual tasks, without significantly affecting linguistic performance. These findings highlight the importance of considering speech variation when learning audiovisual relationships and suggest that using dubbed audio can be a useful technique for developing more robust and flexible audiovisual AI systems.
As the field of AI continues to strive for models that can understand and interact with the world in more natural and human-like ways, this research provides valuable insights into the challenges and opportunities of audiovisual representation learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Contrastive Learning from Synthetic Audio Doppelgangers
Manuel Cherep, Nikhil Singh
0
0
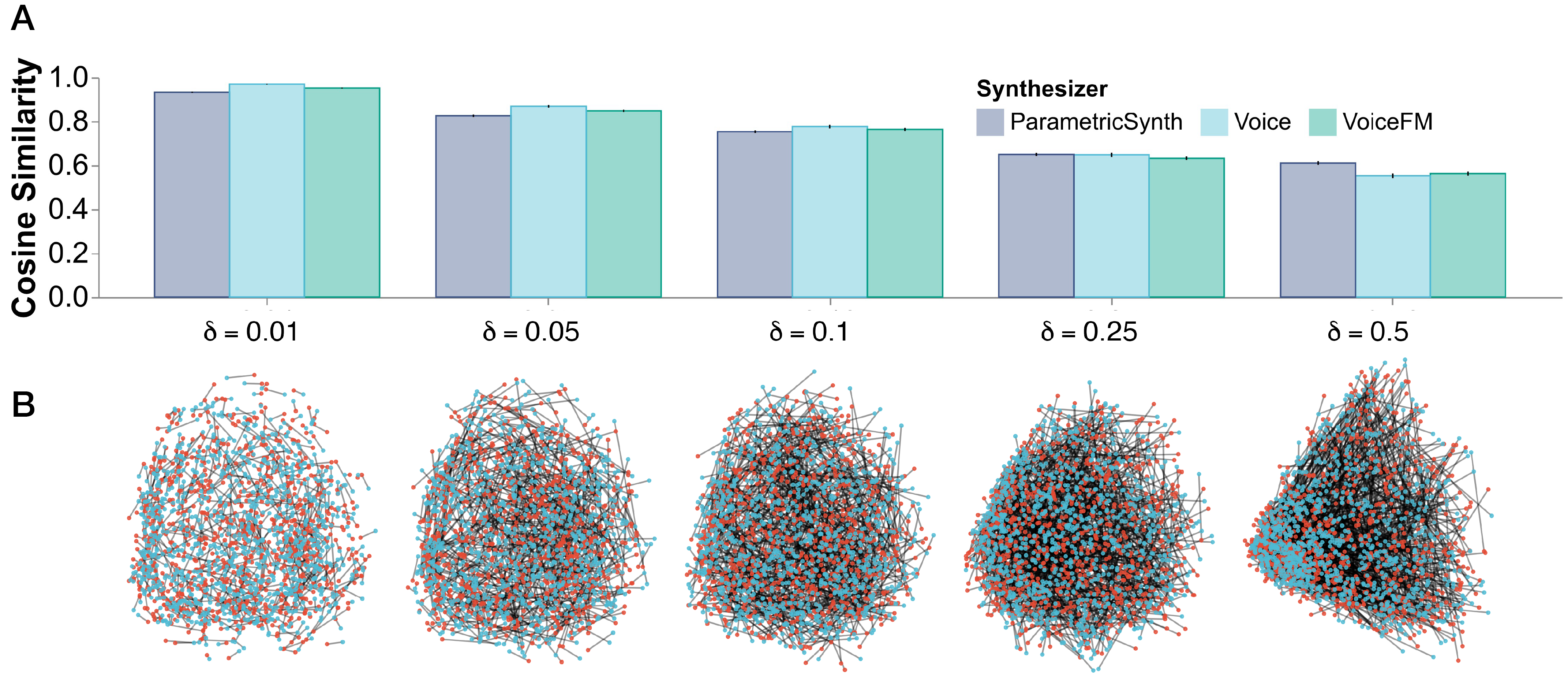
Learning robust audio representations currently demands extensive datasets of real-world sound recordings. By applying artificial transformations to these recordings, models can learn to recognize similarities despite subtle variations through techniques like contrastive learning. However, these transformations are only approximations of the true diversity found in real-world sounds, which are generated by complex interactions of physical processes, from vocal cord vibrations to the resonance of musical instruments. We propose a solution to both the data scale and transformation limitations, leveraging synthetic audio. By randomly perturbing the parameters of a sound synthesizer, we generate audio doppelgangers-synthetic positive pairs with causally manipulated variations in timbre, pitch, and temporal envelopes. These variations, difficult to achieve through transformations of existing audio, provide a rich source of contrastive information. Despite the shift to randomly generated synthetic data, our method produces strong representations, competitive with real data on standard audio classification benchmarks. Notably, our approach is lightweight, requires no data storage, and has only a single hyperparameter, which we extensively analyze. We offer this method as a complement to existing strategies for contrastive learning in audio, using synthesized sounds to reduce the data burden on practitioners.
6/11/2024
Separate in the Speech Chain: Cross-Modal Conditional Audio-Visual Target Speech Extraction
Zhaoxi Mu, Xinyu Yang
0
0
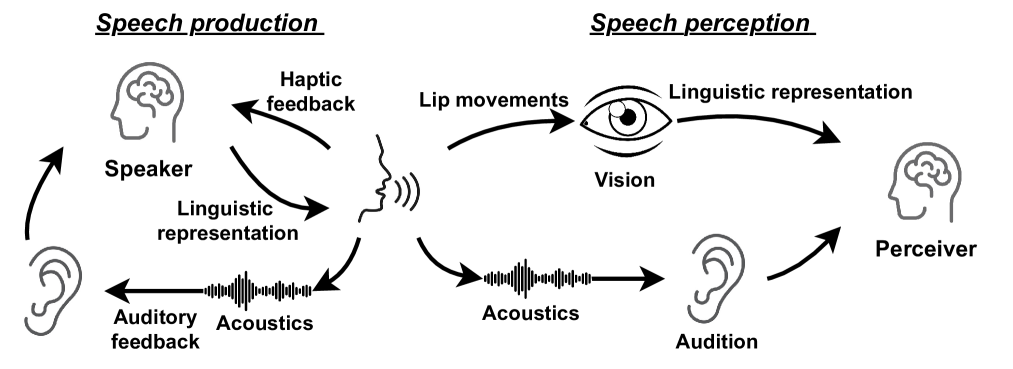
The integration of visual cues has revitalized the performance of the target speech extraction task, elevating it to the forefront of the field. Nevertheless, this multi-modal learning paradigm often encounters the challenge of modality imbalance. In audio-visual target speech extraction tasks, the audio modality tends to dominate, potentially overshadowing the importance of visual guidance. To tackle this issue, we propose AVSepChain, drawing inspiration from the speech chain concept. Our approach partitions the audio-visual target speech extraction task into two stages: speech perception and speech production. In the speech perception stage, audio serves as the dominant modality, while visual information acts as the conditional modality. Conversely, in the speech production stage, the roles are reversed. This transformation of modality status aims to alleviate the problem of modality imbalance. Additionally, we introduce a contrastive semantic matching loss to ensure that the semantic information conveyed by the generated speech aligns with the semantic information conveyed by lip movements during the speech production stage. Through extensive experiments conducted on multiple benchmark datasets for audio-visual target speech extraction, we showcase the superior performance achieved by our proposed method.
5/7/2024
EquiAV: Leveraging Equivariance for Audio-Visual Contrastive Learning
Jongsuk Kim, Hyeongkeun Lee, Kyeongha Rho, Junmo Kim, Joon Son Chung
0
0
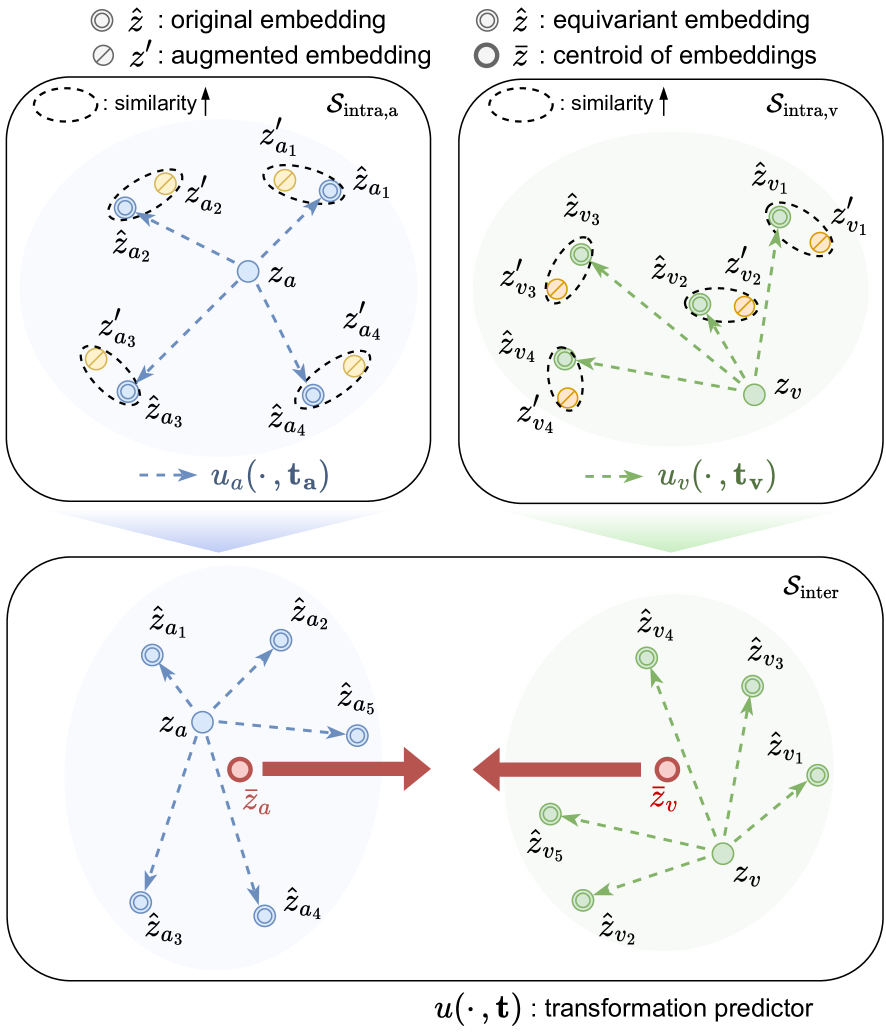
Recent advancements in self-supervised audio-visual representation learning have demonstrated its potential to capture rich and comprehensive representations. However, despite the advantages of data augmentation verified in many learning methods, audio-visual learning has struggled to fully harness these benefits, as augmentations can easily disrupt the correspondence between input pairs. To address this limitation, we introduce EquiAV, a novel framework that leverages equivariance for audio-visual contrastive learning. Our approach begins with extending equivariance to audio-visual learning, facilitated by a shared attention-based transformation predictor. It enables the aggregation of features from diverse augmentations into a representative embedding, providing robust supervision. Notably, this is achieved with minimal computational overhead. Extensive ablation studies and qualitative results verify the effectiveness of our method. EquiAV outperforms previous works across various audio-visual benchmarks. The code is available on https://github.com/JongSuk1/EquiAV.
6/21/2024
Unified Video-Language Pre-training with Synchronized Audio
Shentong Mo, Haofan Wang, Huaxia Li, Xu Tang
0
0
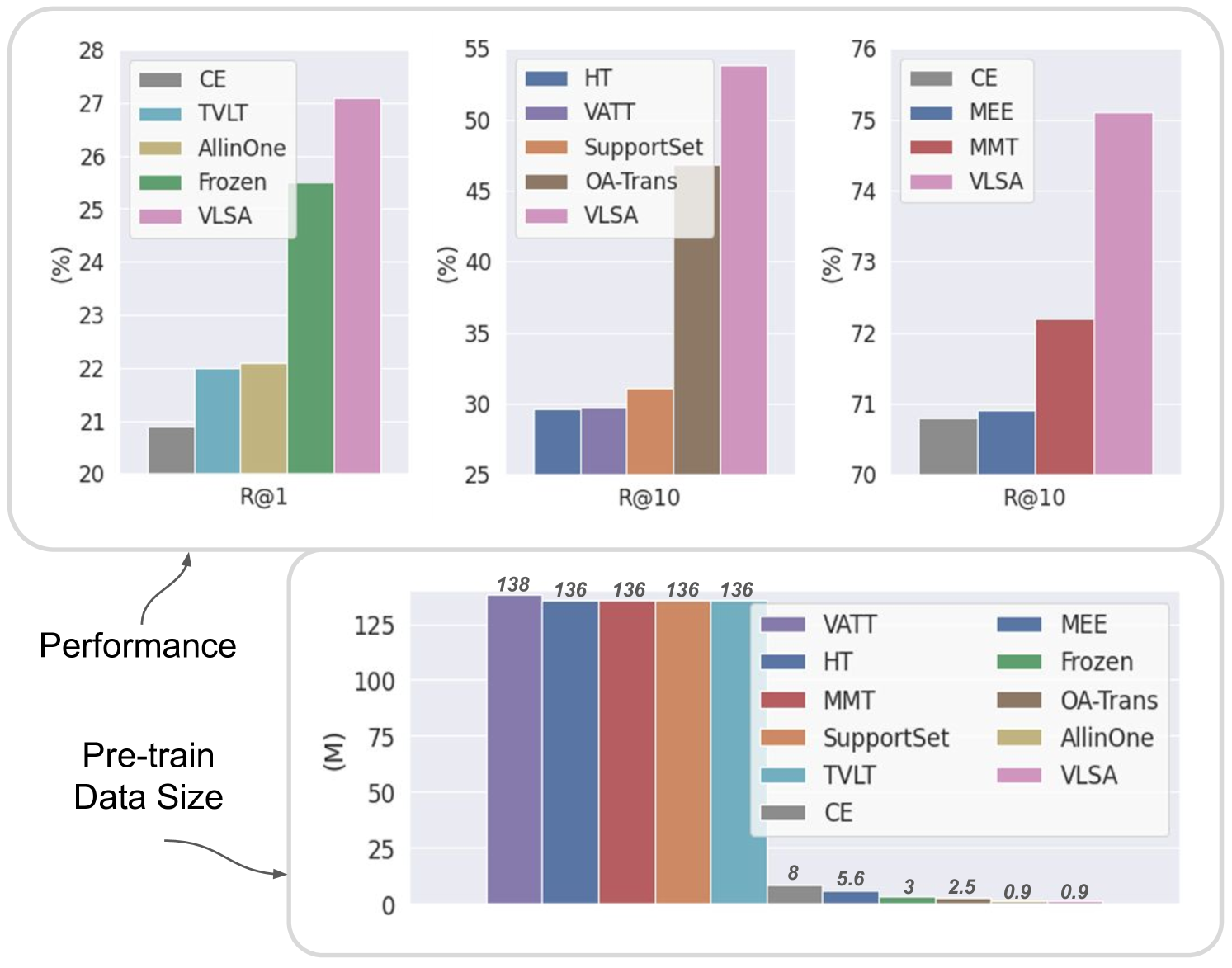
Video-language pre-training is a typical and challenging problem that aims at learning visual and textual representations from large-scale data in a self-supervised way. Existing pre-training approaches either captured the correspondence of image-text pairs or utilized temporal ordering of frames. However, they do not explicitly explore the natural synchronization between audio and the other two modalities. In this work, we propose an enhanced framework for Video-Language pre-training with Synchronized Audio, termed as VLSA, that can learn tri-modal representations in a unified self-supervised transformer. Specifically, our VLSA jointly aggregates embeddings of local patches and global tokens for video, text, and audio. Furthermore, we utilize local-patch masked modeling to learn modality-aware features, and leverage global audio matching to capture audio-guided features for video and text. We conduct extensive experiments on retrieval across text, video, and audio. Our simple model pre-trained on only 0.9M data achieves improving results against state-of-the-art baselines. In addition, qualitative visualizations vividly showcase the superiority of our VLSA in learning discriminative visual-textual representations.
5/14/2024