Audio-Synchronized Visual Animation

0

Sign in to get full access
Overview
- This paper presents a method for generating audio-synchronized visual animations from an input audio signal.
- The approach leverages large language models and multimodal transformers to learn the complex relationships between audio and visual data, allowing for the generation of realistic and dynamic visual content that is closely synchronized with the input audio.
- The proposed technique could have applications in areas like video-to-audio generation, video-to-audio synthesis, and unified video-language pretraining.
Plain English Explanation
The paper describes a way to create animated visuals that are perfectly timed with an audio track. The researchers used advanced AI models to learn how sound and images are related, allowing them to generate visuals that move and change in sync with the audio.
Imagine you have a recording of someone speaking. The researchers' method could take that audio and automatically create an animated character that lip-syncs and moves in time with the voice. This could be useful for things like generating talking head videos or enhancing silent videos with generated audio.
The key innovation is using powerful AI models that can learn the complex relationships between audio and visual data. This allows the system to produce visuals that are tightly synchronized and feel natural, rather than just crudely matching mouth movements to audio.
Technical Explanation
The paper proposes a framework for generating audio-synchronized visual animations. The core of the approach is a multimodal transformer model that is trained on large datasets of audio-visual data. This allows the model to learn the intricate correspondences between audio signals and their associated visual representations.
During inference, the model takes an input audio waveform and generates a sequence of video frames that are dynamically synchronized with the audio. This is achieved by having the transformer model attend to relevant audio features when predicting each video frame, ensuring tight coupling between the auditory and visual outputs.
The authors experiment with different transformer architectures and training strategies, including masked generative models and joint video-language pretraining. Through quantitative and qualitative evaluations, they demonstrate the ability of their approach to generate high-quality, audio-synchronized animations across a variety of domains.
Critical Analysis
The paper presents a compelling approach to the challenging problem of audio-visual synchronization. The authors' use of powerful multimodal transformers is well-justified given the complexity of the task, and their experimental results are promising.
One potential limitation is the reliance on large, curated datasets of audio-visual data for training the models. In real-world scenarios, the availability of such high-quality datasets may be limited, which could impact the performance and generalization of the approach. Additionally, the paper does not address potential issues around bias and fairness that can arise when training on large, potentially biased datasets.
Further research could explore ways to improve the sample efficiency of the models, perhaps through few-shot or unsupervised learning techniques. Additionally, investigating the model's interpretability and its ability to generalize to novel audio-visual pairings could lead to valuable insights.
Conclusion
This paper presents a novel framework for generating audio-synchronized visual animations using advanced multimodal transformer models. The approach demonstrates the potential of AI to create dynamic, realistic visuals that are tightly coupled with audio input, with possible applications in areas like video production, virtual communication, and entertainment.
While the current results are promising, further research is needed to address potential limitations and explore the broader implications of this technology. As the field of audio-visual AI continues to advance, the techniques described in this paper could become an important tool for creating engaging, immersive multimedia experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Audio-Synchronized Visual Animation
Lin Zhang, Shentong Mo, Yijing Zhang, Pedro Morgado
Current visual generation methods can produce high quality videos guided by texts. However, effectively controlling object dynamics remains a challenge. This work explores audio as a cue to generate temporally synchronized image animations. We introduce Audio Synchronized Visual Animation (ASVA), a task animating a static image to demonstrate motion dynamics, temporally guided by audio clips across multiple classes. To this end, we present AVSync15, a dataset curated from VGGSound with videos featuring synchronized audio visual events across 15 categories. We also present a diffusion model, AVSyncD, capable of generating dynamic animations guided by audios. Extensive evaluations validate AVSync15 as a reliable benchmark for synchronized generation and demonstrate our models superior performance. We further explore AVSyncDs potential in a variety of audio synchronized generation tasks, from generating full videos without a base image to controlling object motions with various sounds. We hope our established benchmark can open new avenues for controllable visual generation. More videos on project webpage https://lzhangbj.github.io/projects/asva/asva.html.
Read more7/19/2024

0
A Comprehensive Review and Taxonomy of Audio-Visual Synchronization Techniques for Realistic Speech Animation
Jose Geraldo Fernandes, Sinval Nascimento, Daniel Dominguete, Andr'e Oliveira, Lucas Rotsen, Gabriel Souza, David Brochero, Luiz Facury, Mateus Vilela, Hebert Costa, Frederico Coelho, Ant^onio P. Braga
In many applications, synchronizing audio with visuals is crucial, such as in creating graphic animations for films or games, translating movie audio into different languages, and developing metaverse applications. This review explores various methodologies for achieving realistic facial animations from audio inputs, highlighting generative and adaptive models. Addressing challenges like model training costs, dataset availability, and silent moment distributions in audio data, it presents innovative solutions to enhance performance and realism. The research also introduces a new taxonomy to categorize audio-visual synchronization methods based on logistical aspects, advancing the capabilities of virtual assistants, gaming, and interactive digital media.
Read more8/29/2024
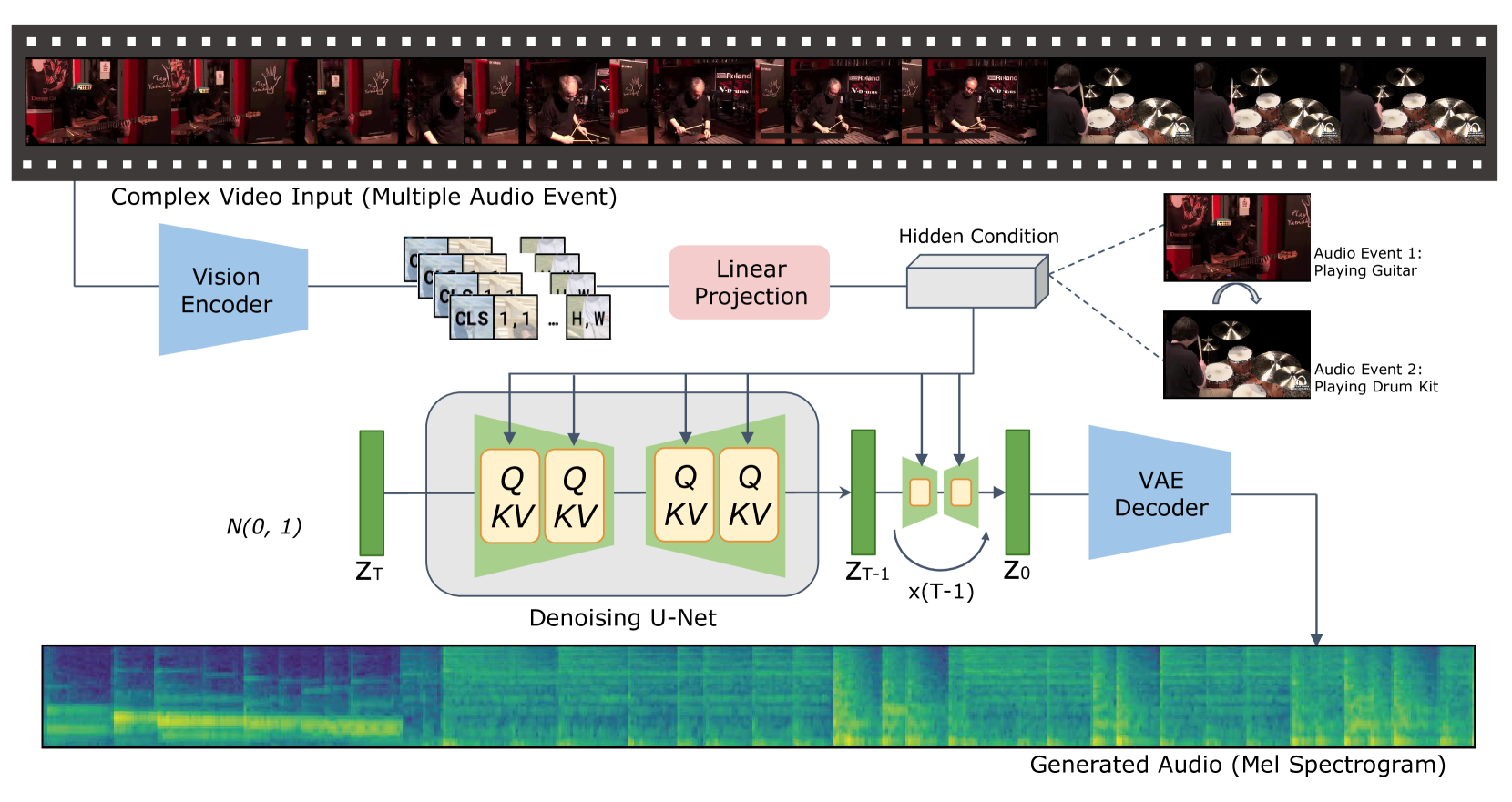
0
Video-to-Audio Generation with Hidden Alignment
Manjie Xu, Chenxing Li, Yong Ren, Rilin Chen, Yu Gu, Wei Liang, Dong Yu
Generating semantically and temporally aligned audio content in accordance with video input has become a focal point for researchers, particularly following the remarkable breakthrough in text-to-video generation. In this work, we aim to offer insights into the video-to-audio generation paradigm, focusing on three crucial aspects: vision encoders, auxiliary embeddings, and data augmentation techniques. Beginning with a foundational model VTA-LDM built on a simple yet surprisingly effective intuition, we explore various vision encoders and auxiliary embeddings through ablation studies. Employing a comprehensive evaluation pipeline that emphasizes generation quality and video-audio synchronization alignment, we demonstrate that our model exhibits state-of-the-art video-to-audio generation capabilities. Furthermore, we provide critical insights into the impact of different data augmentation methods on enhancing the generation framework's overall capacity. We showcase possibilities to advance the challenge of generating synchronized audio from semantic and temporal perspectives. We hope these insights will serve as a stepping stone toward developing more realistic and accurate audio-visual generation models.
Read more7/11/2024
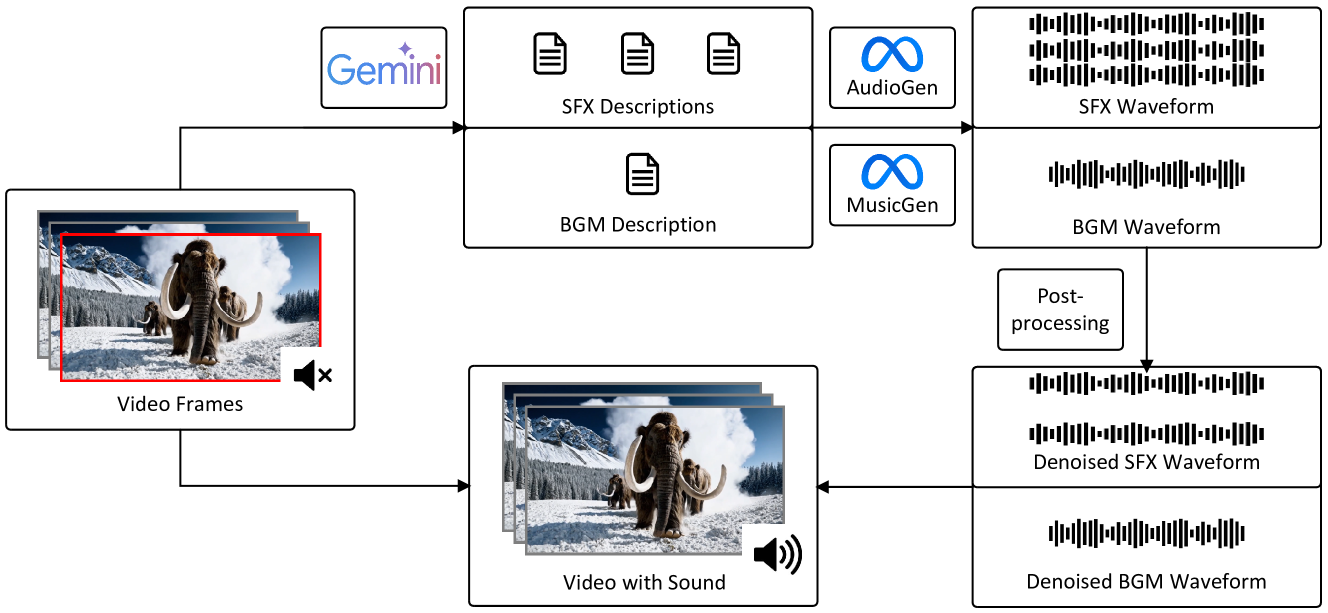
0
Semantically consistent Video-to-Audio Generation using Multimodal Language Large Model
Gehui Chen, Guan'an Wang, Xiaowen Huang, Jitao Sang
Existing works have made strides in video generation, but the lack of sound effects (SFX) and background music (BGM) hinders a complete and immersive viewer experience. We introduce a novel semantically consistent v ideo-to-audio generation framework, namely SVA, which automatically generates audio semantically consistent with the given video content. The framework harnesses the power of multimodal large language model (MLLM) to understand video semantics from a key frame and generate creative audio schemes, which are then utilized as prompts for text-to-audio models, resulting in video-to-audio generation with natural language as an interface. We show the satisfactory performance of SVA through case study and discuss the limitations along with the future research direction. The project page is available at https://huiz-a.github.io/audio4video.github.io/.
Read more4/29/2024