Masked Generative Video-to-Audio Transformers with Enhanced Synchronicity

0

Sign in to get full access
Overview
- This paper presents a novel generative model for translating video to audio, with a focus on enhancing the synchronicity between the generated audio and the input video.
- The model uses a masked token generation approach, where the model learns to predict missing audio tokens given the corresponding video frames.
- The authors introduce several architectural improvements to improve the alignment between the generated audio and the input video, including multi-scale feature fusion and a synchronicity loss function.
Plain English Explanation
The researchers have developed a new AI system that can generate audio from video. This is a challenging task because the audio and video need to be well-synchronized - the sounds should match up with what's happening on screen.
To address this, the researchers used a "masked token" approach. The model is trained to predict the missing audio parts given the video frames. This helps it learn the connection between the visual information and the corresponding sounds.
The researchers also made some key architectural improvements to enhance the synchronization between the generated audio and the input video. This includes fusing features at multiple scales and using a special "synchronicity loss function" during training.
The end result is a model that can generate audio from video while keeping the audio and video tightly synchronized, which is important for many applications like video editing and animation.
Technical Explanation
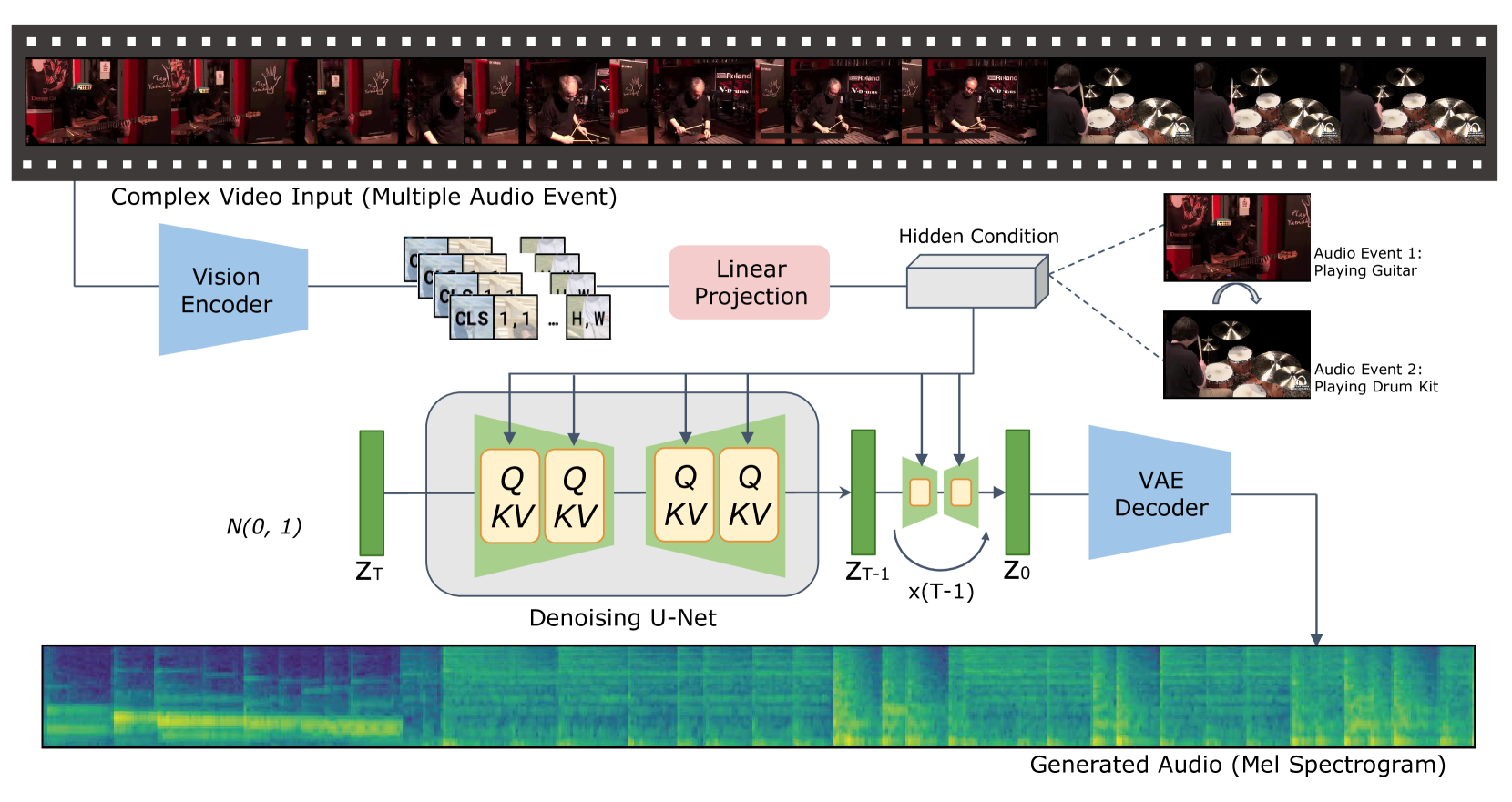
The paper presents a Video-to-Audio Masked Token Generative Model that aims to generate synchronized audio given input video. The model uses a transformer-based architecture to encode the video frames and predict the corresponding audio tokens in a masked token generation framework.
To enhance the synchronicity between the generated audio and input video, the authors introduce several key innovations:
-
Multi-Scale Feature Fusion: The model fuses features at multiple scales, from the local patch level to the global frame level, to better capture the complex relationships between visual and audio signals.
-
Synchronicity Loss Function: The authors define a novel synchronicity loss function that encourages the generated audio to be well-aligned with the input video, going beyond just maximizing audio-visual similarity.
-
Bi-Directional Attention: The model uses bi-directional attention to model the dependencies between video and audio, allowing it to better capture the complex dynamics between the two modalities.
The model is trained end-to-end on large-scale video-audio datasets using these techniques. Experiments show that the proposed model outperforms previous state-of-the-art approaches in terms of both audio quality and synchronicity with the input video.
Critical Analysis
The paper presents a compelling approach to the challenging problem of video-to-audio generation with enhanced synchronicity. The authors' innovations, such as multi-scale feature fusion and the synchronicity loss function, are well-designed to address the key challenges in this domain.
That said, the paper does not extensively discuss potential limitations or areas for future work. For example, it would be interesting to see how the model performs on more diverse and unconstrained video-audio data, beyond the curated datasets used in the experiments. Additionally, the paper does not provide much insight into the computational complexity and real-world deployment feasibility of the proposed approach.
Overall, the research represents a significant advancement in the field of video-to-audio generation, but there are still opportunities to further improve the robustness and practicality of such systems, which could be explored in future work.
Conclusion
This paper introduces a novel Video-to-Audio Masked Token Generative Model that can generate high-quality audio from input video, with a strong emphasis on maintaining synchronicity between the two modalities. The key innovations, such as multi-scale feature fusion and synchronicity-aware loss functions, help the model better capture the complex relationships between visual and audio signals.
The results demonstrate significant improvements over previous state-of-the-art approaches, highlighting the potential of this technology for various applications, such as video editing, animation, and virtual/augmented reality. As the field of multimodal AI continues to advance, this work represents an important step towards more seamless and natural integration of visual and auditory information.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Masked Generative Video-to-Audio Transformers with Enhanced Synchronicity
Santiago Pascual, Chunghsin Yeh, Ioannis Tsiamas, Joan Serr`a
Video-to-audio (V2A) generation leverages visual-only video features to render plausible sounds that match the scene. Importantly, the generated sound onsets should match the visual actions that are aligned with them, otherwise unnatural synchronization artifacts arise. Recent works have explored the progression of conditioning sound generators on still images and then video features, focusing on quality and semantic matching while ignoring synchronization, or by sacrificing some amount of quality to focus on improving synchronization only. In this work, we propose a V2A generative model, named MaskVAT, that interconnects a full-band high-quality general audio codec with a sequence-to-sequence masked generative model. This combination allows modeling both high audio quality, semantic matching, and temporal synchronicity at the same time. Our results show that, by combining a high-quality codec with the proper pre-trained audio-visual features and a sequence-to-sequence parallel structure, we are able to yield highly synchronized results on one hand, whilst being competitive with the state of the art of non-codec generative audio models. Sample videos and generated audios are available at https://maskvat.github.io .
Read more7/16/2024
0
Video-to-Audio Generation with Hidden Alignment
Manjie Xu, Chenxing Li, Yong Ren, Rilin Chen, Yu Gu, Wei Liang, Dong Yu
Generating semantically and temporally aligned audio content in accordance with video input has become a focal point for researchers, particularly following the remarkable breakthrough in text-to-video generation. In this work, we aim to offer insights into the video-to-audio generation paradigm, focusing on three crucial aspects: vision encoders, auxiliary embeddings, and data augmentation techniques. Beginning with a foundational model VTA-LDM built on a simple yet surprisingly effective intuition, we explore various vision encoders and auxiliary embeddings through ablation studies. Employing a comprehensive evaluation pipeline that emphasizes generation quality and video-audio synchronization alignment, we demonstrate that our model exhibits state-of-the-art video-to-audio generation capabilities. Furthermore, we provide critical insights into the impact of different data augmentation methods on enhancing the generation framework's overall capacity. We showcase possibilities to advance the challenge of generating synchronized audio from semantic and temporal perspectives. We hope these insights will serve as a stepping stone toward developing more realistic and accurate audio-visual generation models.
Read more7/11/2024

0
Dynamic Motion Synthesis: Masked Audio-Text Conditioned Spatio-Temporal Transformers
Sohan Anisetty, James Hays
Our research presents a novel motion generation framework designed to produce whole-body motion sequences conditioned on multiple modalities simultaneously, specifically text and audio inputs. Leveraging Vector Quantized Variational Autoencoders (VQVAEs) for motion discretization and a bidirectional Masked Language Modeling (MLM) strategy for efficient token prediction, our approach achieves improved processing efficiency and coherence in the generated motions. By integrating spatial attention mechanisms and a token critic we ensure consistency and naturalness in the generated motions. This framework expands the possibilities of motion generation, addressing the limitations of existing approaches and opening avenues for multimodal motion synthesis.
Read more9/4/2024

0
New!STA-V2A: Video-to-Audio Generation with Semantic and Temporal Alignment
Yong Ren, Chenxing Li, Manjie Xu, Wei Liang, Yu Gu, Rilin Chen, Dong Yu
Visual and auditory perception are two crucial ways humans experience the world. Text-to-video generation has made remarkable progress over the past year, but the absence of harmonious audio in generated video limits its broader applications. In this paper, we propose Semantic and Temporal Aligned Video-to-Audio (STA-V2A), an approach that enhances audio generation from videos by extracting both local temporal and global semantic video features and combining these refined video features with text as cross-modal guidance. To address the issue of information redundancy in videos, we propose an onset prediction pretext task for local temporal feature extraction and an attentive pooling module for global semantic feature extraction. To supplement the insufficient semantic information in videos, we propose a Latent Diffusion Model with Text-to-Audio priors initialization and cross-modal guidance. We also introduce Audio-Audio Align, a new metric to assess audio-temporal alignment. Subjective and objective metrics demonstrate that our method surpasses existing Video-to-Audio models in generating audio with better quality, semantic consistency, and temporal alignment. The ablation experiment validated the effectiveness of each module. Audio samples are available at https://y-ren16.github.io/STAV2A.
Read more9/16/2024