Audio-Visual Talker Localization in Video for Spatial Sound Reproduction
2406.00495
0
0
Abstract
Object-based audio production requires the positional metadata to be defined for each point-source object, including the key elements in the foreground of the sound scene. In many media production use cases, both cameras and microphones are employed to make recordings, and the human voice is often a key element. In this research, we detect and locate the active speaker in the video, facilitating the automatic extraction of the positional metadata of the talker relative to the camera's reference frame. With the integration of the visual modality, this study expands upon our previous investigation focused solely on audio-based active speaker detection and localization. Our experiments compare conventional audio-visual approaches for active speaker detection that leverage monaural audio, our previous audio-only method that leverages multichannel recordings from a microphone array, and a novel audio-visual approach integrating vision and multichannel audio. We found the role of the two modalities to complement each other. Multichannel audio, overcoming the problem of visual occlusions, provides a double-digit reduction in detection error compared to audio-visual methods with single-channel audio. The combination of multichannel audio and vision further enhances spatial accuracy, leading to a four-percentage point increase in F1 score on the Tragic Talkers dataset. Future investigations will assess the robustness of the model in noisy and highly reverberant environments, as well as tackle the problem of off-screen speakers.
Create account to get full access
Overview
- This paper explores the problem of audio-visual talker localization in video for spatial sound reproduction.
- The goal is to develop a system that can accurately locate the position of a speaker in a video and use that information to create a spatial audio experience that matches the visual cues.
- The research involves experiments with various machine learning models and techniques to achieve this objective.
Plain English Explanation
This research aims to improve the experience of watching videos or movies by making the audio match the visuals more closely. When we watch someone speaking on a screen, we expect the sound to come from the direction of their mouth. However, in many cases, the audio is just played through speakers in front of the viewer, creating a disconnect between what we see and what we hear.
The researchers in this paper are trying to solve this problem by developing a system that can automatically detect the location of the speaker in the video and then adjust the audio accordingly. This would allow the sound to appear to come from the correct position on the screen, making the overall experience more immersive and natural.
To achieve this, the researchers experiment with different machine learning models that can analyze the video and audio data together to pinpoint the speaker's location. This involves techniques like cross-modal cognitive consensus guided audio-visual perception and unified audio-visual perception for multi-task learning.
The goal is to create a system that can be used in a variety of video and movie applications, from streaming services to home theater setups, to provide a more realistic and engaging audio-visual experience for the viewer.
Technical Explanation
The paper proposes a novel approach for audio-visual talker localization in video, which is essential for spatial sound reproduction. The key technical components include:
-
Audio-Visual Feature Extraction: The system extracts visual features from the video, such as facial landmarks and lip movements, as well as audio features from the corresponding speech signal. These features are used to model the relationship between the audio and visual cues.
-
Talker Localization: The researchers experiment with different machine learning models, including text-guided visual sound source localization and separate speech chain cross-modal conditional audio-visual architectures, to accurately locate the position of the speaker in the video frame.
-
Spatial Sound Reproduction: Based on the estimated speaker location, the system generates a spatial audio signal that matches the visual cues, creating a more immersive and realistic experience for the viewer.
The researchers conduct extensive experiments on various datasets to evaluate the performance of their approach. They compare their results to state-of-the-art methods and demonstrate the effectiveness of their proposed techniques for audio-visual talker localization and spatial sound reproduction.
Critical Analysis
The paper presents a well-designed and comprehensive approach to the problem of audio-visual talker localization. The researchers have thoroughly explored the relevant literature and built upon existing techniques, such as cross-modal cognitive consensus guided audio-visual perception, to develop their own innovative solutions.
One potential limitation of the research is the reliance on specific dataset characteristics, such as the quality and synchronization of the audio and visual data. It would be valuable to further investigate the robustness of the proposed methods to more diverse and challenging real-world scenarios, including noisy environments, variable camera angles, and varying speaker positions.
Additionally, the paper does not discuss the computational complexity and resource requirements of the proposed system, which could be an important consideration for practical deployment, especially in resource-constrained settings like mobile devices or embedded systems.
Nonetheless, the research presents a significant contribution to the field of audio-visual signal processing and has the potential to improve the quality and immersiveness of various multimedia applications, such as video conferencing, entertainment systems, and augmented reality experiences.
Conclusion
This paper addresses the important problem of audio-visual talker localization in video for spatial sound reproduction. The researchers have developed a comprehensive system that can accurately detect the position of a speaker in a video and use that information to generate a spatial audio signal that matches the visual cues.
The proposed methods, which leverage various machine learning techniques, have demonstrated promising results in experiments and have the potential to significantly enhance the overall audio-visual experience for viewers. As the research continues to evolve, it could lead to more natural and immersive multimedia experiences in a wide range of applications, from streaming services to virtual reality.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Exploring Audio-Visual Information Fusion for Sound Event Localization and Detection In Low-Resource Realistic Scenarios
Ya Jiang, Qing Wang, Jun Du, Maocheng Hu, Pengfei Hu, Zeyan Liu, Shi Cheng, Zhaoxu Nian, Yuxuan Dong, Mingqi Cai, Xin Fang, Chin-Hui Lee
0
0
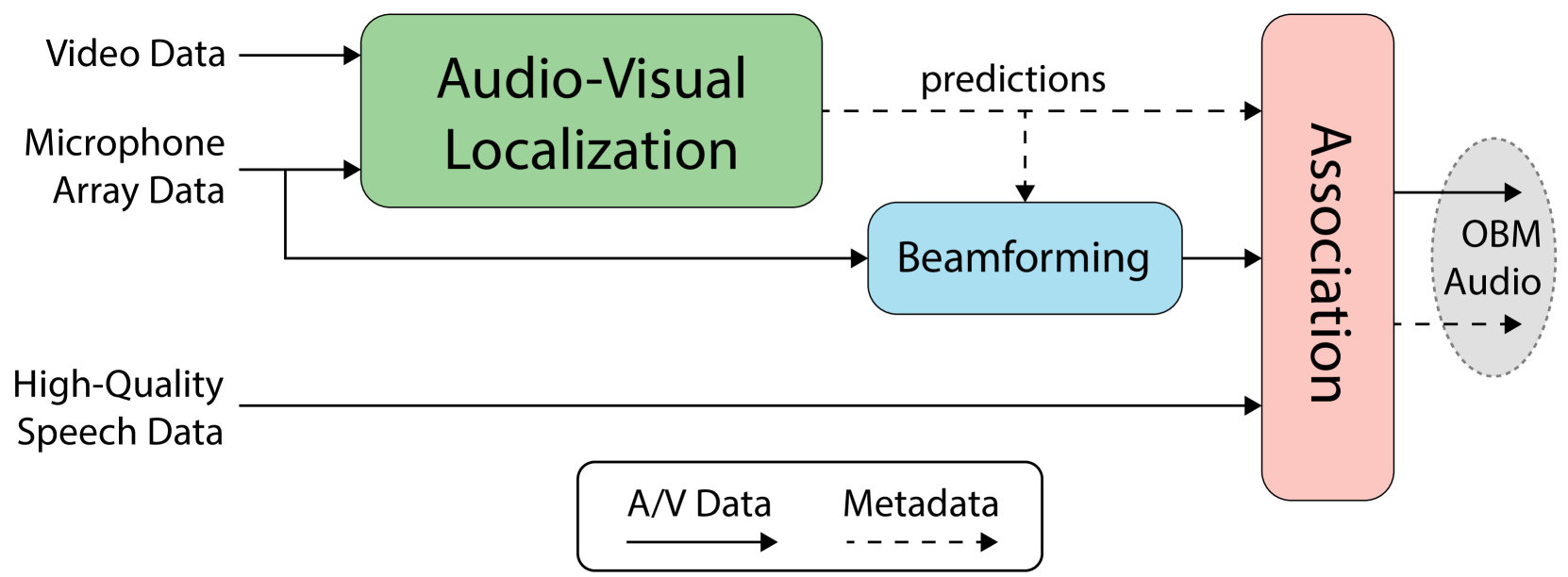
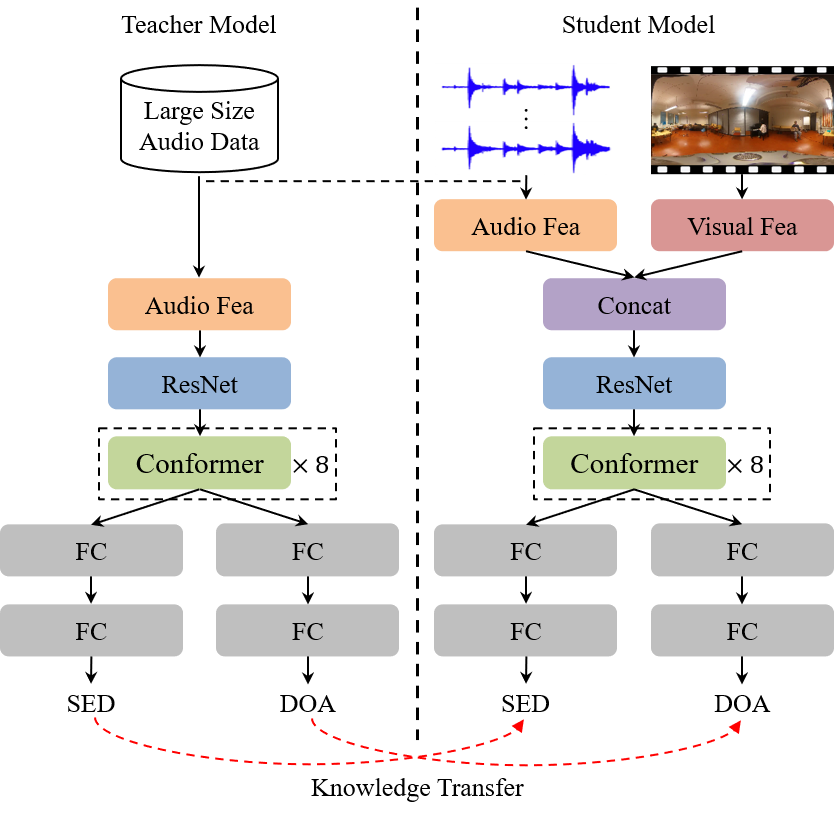
This study presents an audio-visual information fusion approach to sound event localization and detection (SELD) in low-resource scenarios. We aim at utilizing audio and video modality information through cross-modal learning and multi-modal fusion. First, we propose a cross-modal teacher-student learning (TSL) framework to transfer information from an audio-only teacher model, trained on a rich collection of audio data with multiple data augmentation techniques, to an audio-visual student model trained with only a limited set of multi-modal data. Next, we propose a two-stage audio-visual fusion strategy, consisting of an early feature fusion and a late video-guided decision fusion to exploit synergies between audio and video modalities. Finally, we introduce an innovative video pixel swapping (VPS) technique to extend an audio channel swapping (ACS) method to an audio-visual joint augmentation. Evaluation results on the Detection and Classification of Acoustic Scenes and Events (DCASE) 2023 Challenge data set demonstrate significant improvements in SELD performances. Furthermore, our submission to the SELD task of the DCASE 2023 Challenge ranks first place by effectively integrating the proposed techniques into a model ensemble.
6/24/2024
T-VSL: Text-Guided Visual Sound Source Localization in Mixtures
Tanvir Mahmud, Yapeng Tian, Diana Marculescu
0
0
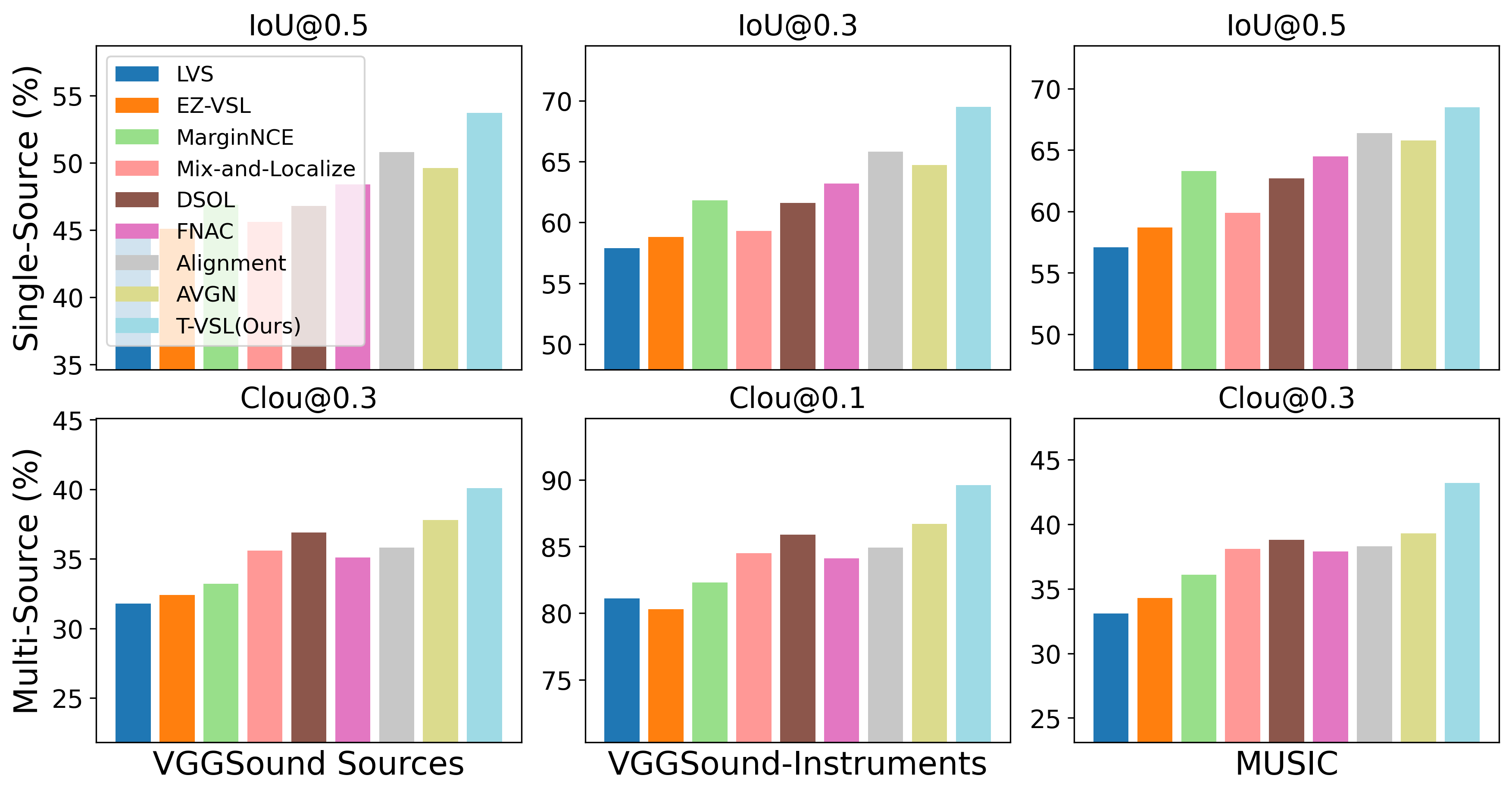
Visual sound source localization poses a significant challenge in identifying the semantic region of each sounding source within a video. Existing self-supervised and weakly supervised source localization methods struggle to accurately distinguish the semantic regions of each sounding object, particularly in multi-source mixtures. These methods often rely on audio-visual correspondence as guidance, which can lead to substantial performance drops in complex multi-source localization scenarios. The lack of access to individual source sounds in multi-source mixtures during training exacerbates the difficulty of learning effective audio-visual correspondence for localization. To address this limitation, in this paper, we propose incorporating the text modality as an intermediate feature guide using tri-modal joint embedding models (e.g., AudioCLIP) to disentangle the semantic audio-visual source correspondence in multi-source mixtures. Our framework, dubbed T-VSL, begins by predicting the class of sounding entities in mixtures. Subsequently, the textual representation of each sounding source is employed as guidance to disentangle fine-grained audio-visual source correspondence from multi-source mixtures, leveraging the tri-modal AudioCLIP embedding. This approach enables our framework to handle a flexible number of sources and exhibits promising zero-shot transferability to unseen classes during test time. Extensive experiments conducted on the MUSIC, VGGSound, and VGGSound-Instruments datasets demonstrate significant performance improvements over state-of-the-art methods.
4/3/2024

UniAV: Unified Audio-Visual Perception for Multi-Task Video Localization
Tiantian Geng, Teng Wang, Yanfu Zhang, Jinming Duan, Weili Guan, Feng Zheng
0
0
Video localization tasks aim to temporally locate specific instances in videos, including temporal action localization (TAL), sound event detection (SED) and audio-visual event localization (AVEL). Existing methods over-specialize on each task, overlooking the fact that these instances often occur in the same video to form the complete video content. In this work, we present UniAV, a Unified Audio-Visual perception network, to achieve joint learning of TAL, SED and AVEL tasks for the first time. UniAV can leverage diverse data available in task-specific datasets, allowing the model to learn and share mutually beneficial knowledge across tasks and modalities. To tackle the challenges posed by substantial variations in datasets (size/domain/duration) and distinct task characteristics, we propose to uniformly encode visual and audio modalities of all videos to derive generic representations, while also designing task-specific experts to capture unique knowledge for each task. Besides, we develop a unified language-aware classifier by utilizing a pre-trained text encoder, enabling the model to flexibly detect various types of instances and previously unseen ones by simply changing prompts during inference. UniAV outperforms its single-task counterparts by a large margin with fewer parameters, achieving on-par or superior performances compared to state-of-the-art task-specific methods across ActivityNet 1.3, DESED and UnAV-100 benchmarks.
4/5/2024
Separate in the Speech Chain: Cross-Modal Conditional Audio-Visual Target Speech Extraction
Zhaoxi Mu, Xinyu Yang
0
0
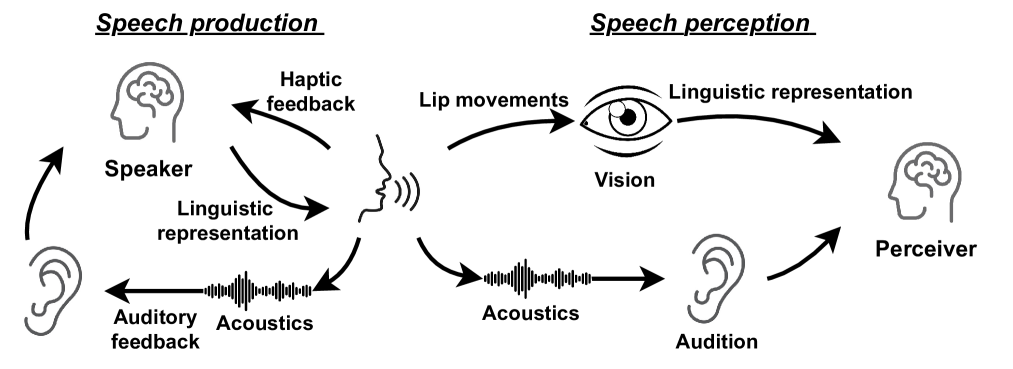
The integration of visual cues has revitalized the performance of the target speech extraction task, elevating it to the forefront of the field. Nevertheless, this multi-modal learning paradigm often encounters the challenge of modality imbalance. In audio-visual target speech extraction tasks, the audio modality tends to dominate, potentially overshadowing the importance of visual guidance. To tackle this issue, we propose AVSepChain, drawing inspiration from the speech chain concept. Our approach partitions the audio-visual target speech extraction task into two stages: speech perception and speech production. In the speech perception stage, audio serves as the dominant modality, while visual information acts as the conditional modality. Conversely, in the speech production stage, the roles are reversed. This transformation of modality status aims to alleviate the problem of modality imbalance. Additionally, we introduce a contrastive semantic matching loss to ensure that the semantic information conveyed by the generated speech aligns with the semantic information conveyed by lip movements during the speech production stage. Through extensive experiments conducted on multiple benchmark datasets for audio-visual target speech extraction, we showcase the superior performance achieved by our proposed method.
5/7/2024