UniAV: Unified Audio-Visual Perception for Multi-Task Video Localization
2404.03179
0
0

Abstract
Video localization tasks aim to temporally locate specific instances in videos, including temporal action localization (TAL), sound event detection (SED) and audio-visual event localization (AVEL). Existing methods over-specialize on each task, overlooking the fact that these instances often occur in the same video to form the complete video content. In this work, we present UniAV, a Unified Audio-Visual perception network, to achieve joint learning of TAL, SED and AVEL tasks for the first time. UniAV can leverage diverse data available in task-specific datasets, allowing the model to learn and share mutually beneficial knowledge across tasks and modalities. To tackle the challenges posed by substantial variations in datasets (size/domain/duration) and distinct task characteristics, we propose to uniformly encode visual and audio modalities of all videos to derive generic representations, while also designing task-specific experts to capture unique knowledge for each task. Besides, we develop a unified language-aware classifier by utilizing a pre-trained text encoder, enabling the model to flexibly detect various types of instances and previously unseen ones by simply changing prompts during inference. UniAV outperforms its single-task counterparts by a large margin with fewer parameters, achieving on-par or superior performances compared to state-of-the-art task-specific methods across ActivityNet 1.3, DESED and UnAV-100 benchmarks.
Create account to get full access
Overview
- This paper presents UniAV, a unified audio-visual perception model for multi-task video localization.
- UniAV is designed to leverage both visual and auditory information to perform tasks like action recognition, video grounding, and audio-visual event detection.
- The model aims to learn a shared representation that can effectively integrate and utilize multimodal data for improved performance across various video understanding tasks.
Plain English Explanation
The paper introduces a new model called UniAV that is designed to work with both visual and audio information from videos. The goal is to create a single model that can perform multiple tasks related to understanding and analyzing video content, such as recognizing actions, finding specific moments in videos, and detecting audio-visual events.
The key idea is to train UniAV to learn a shared representation that can effectively combine and use both the visual and audio data from videos. This shared representation is then used to tackle the different video understanding tasks, allowing the model to leverage the complementary information from the two modalities.
By unifying the audio and visual processing, the researchers hope to create a more powerful and versatile system for analyzing video content compared to approaches that treat the two modalities separately. This could have applications in areas like video search, video summarization, and automated video understanding for various domains.
Technical Explanation
The UniAV model proposed in this paper aims to learn a shared representation that can effectively integrate and utilize both visual and auditory information for multi-task video understanding.
The architecture consists of separate visual and audio encoders that extract features from the corresponding input modalities. These features are then fused using a multimodal fusion module to create the shared representation. This unified representation is then used as input to task-specific prediction heads for various video localization tasks, such as action recognition, video grounding, and audio-visual event detection.
The key innovation is the use of this shared representation, which allows the model to effectively leverage multimodal information and learn cross-modal relationships. This is in contrast to prior approaches that typically treat audio and visual processing as separate tasks with independent models.
The authors evaluate UniAV on several benchmark datasets for the target video localization tasks, comparing it to state-of-the-art unimodal and multimodal baselines. The results demonstrate the advantages of the unified audio-visual architecture, showing consistent improvements in performance across the different tasks.
Critical Analysis
The UniAV paper presents a promising approach for leveraging multimodal data for video understanding tasks. By learning a shared representation that can integrate both visual and auditory information, the model is able to outperform prior methods that treat the modalities independently.
However, the paper does not provide a deep analysis of the types of video content or tasks where the unified audio-visual approach is most beneficial. It would be helpful to understand the specific scenarios or video domains where the complementary nature of the audio and visual data is most impactful for improving localization performance.
Additionally, the paper does not discuss any potential limitations or failure cases of the UniAV model. It would be valuable to understand if there are any types of videos or tasks where the model struggles, and what the underlying reasons might be. This could inform future research directions to address the shortcomings.
Finally, the authors could have provided more insight into the learned shared representation and how it differs from representations obtained through separate audio and visual processing. An analysis of the cross-modal relationships captured by this unified representation could yield additional interesting findings.
Conclusion
The UniAV paper presents a novel unified audio-visual perception model for multi-task video localization. By learning a shared representation that can effectively integrate visual and auditory information, the model is able to outperform prior approaches that treat the modalities independently.
The results demonstrate the advantages of this multimodal integration, highlighting the potential of leveraging complementary audio-visual cues for improved video understanding. This could have important applications in areas like video search, summarization, and automated video analysis.
While the paper provides a solid technical contribution, further research is needed to fully understand the strengths and limitations of the UniAV approach, as well as explore ways to further enhance the capabilities of unified audio-visual perception models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Unified Video-Language Pre-training with Synchronized Audio
Shentong Mo, Haofan Wang, Huaxia Li, Xu Tang
0
0
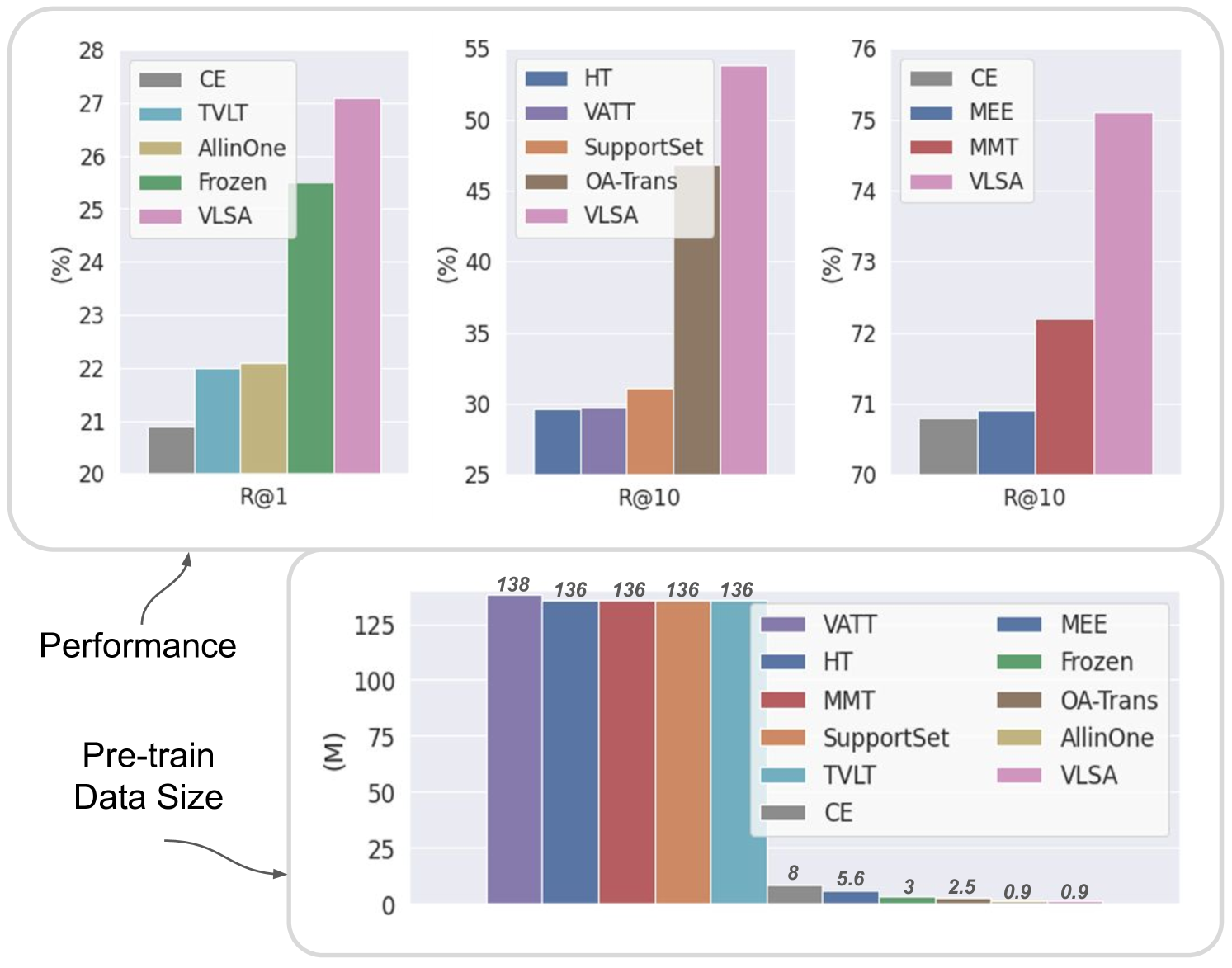
Video-language pre-training is a typical and challenging problem that aims at learning visual and textual representations from large-scale data in a self-supervised way. Existing pre-training approaches either captured the correspondence of image-text pairs or utilized temporal ordering of frames. However, they do not explicitly explore the natural synchronization between audio and the other two modalities. In this work, we propose an enhanced framework for Video-Language pre-training with Synchronized Audio, termed as VLSA, that can learn tri-modal representations in a unified self-supervised transformer. Specifically, our VLSA jointly aggregates embeddings of local patches and global tokens for video, text, and audio. Furthermore, we utilize local-patch masked modeling to learn modality-aware features, and leverage global audio matching to capture audio-guided features for video and text. We conduct extensive experiments on retrieval across text, video, and audio. Our simple model pre-trained on only 0.9M data achieves improving results against state-of-the-art baselines. In addition, qualitative visualizations vividly showcase the superiority of our VLSA in learning discriminative visual-textual representations.
5/14/2024
Exploring Audio-Visual Information Fusion for Sound Event Localization and Detection In Low-Resource Realistic Scenarios
Ya Jiang, Qing Wang, Jun Du, Maocheng Hu, Pengfei Hu, Zeyan Liu, Shi Cheng, Zhaoxu Nian, Yuxuan Dong, Mingqi Cai, Xin Fang, Chin-Hui Lee
0
0
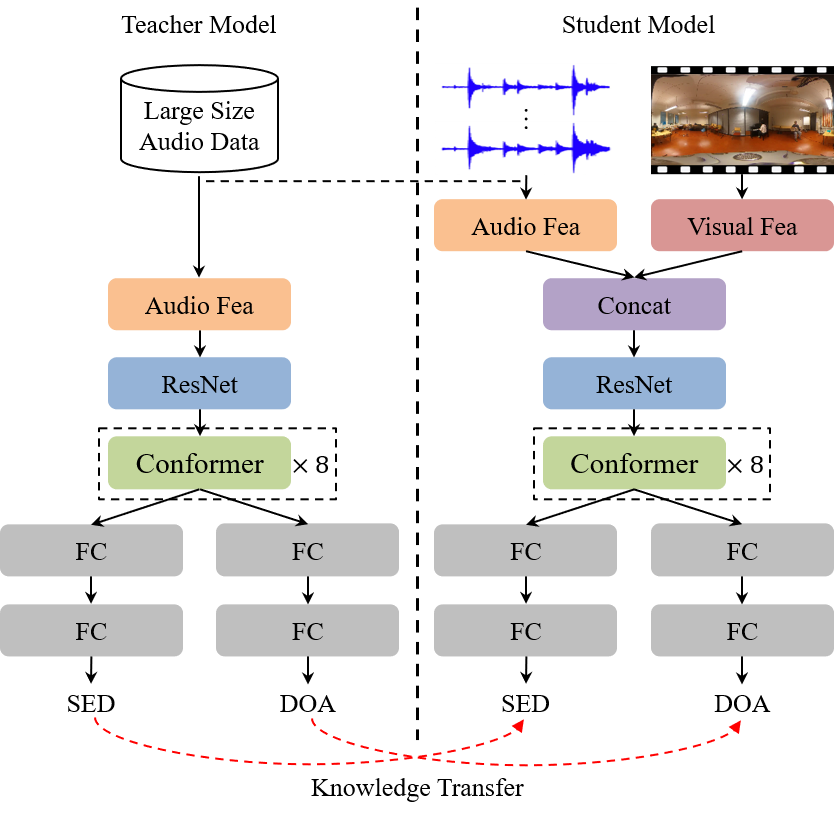
This study presents an audio-visual information fusion approach to sound event localization and detection (SELD) in low-resource scenarios. We aim at utilizing audio and video modality information through cross-modal learning and multi-modal fusion. First, we propose a cross-modal teacher-student learning (TSL) framework to transfer information from an audio-only teacher model, trained on a rich collection of audio data with multiple data augmentation techniques, to an audio-visual student model trained with only a limited set of multi-modal data. Next, we propose a two-stage audio-visual fusion strategy, consisting of an early feature fusion and a late video-guided decision fusion to exploit synergies between audio and video modalities. Finally, we introduce an innovative video pixel swapping (VPS) technique to extend an audio channel swapping (ACS) method to an audio-visual joint augmentation. Evaluation results on the Detection and Classification of Acoustic Scenes and Events (DCASE) 2023 Challenge data set demonstrate significant improvements in SELD performances. Furthermore, our submission to the SELD task of the DCASE 2023 Challenge ranks first place by effectively integrating the proposed techniques into a model ensemble.
6/24/2024

MA-AVT: Modality Alignment for Parameter-Efficient Audio-Visual Transformers
Tanvir Mahmud, Shentong Mo, Yapeng Tian, Diana Marculescu
0
0
Recent advances in pre-trained vision transformers have shown promise in parameter-efficient audio-visual learning without audio pre-training. However, few studies have investigated effective methods for aligning multimodal features in parameter-efficient audio-visual transformers. In this paper, we propose MA-AVT, a new parameter-efficient audio-visual transformer employing deep modality alignment for corresponding multimodal semantic features. Specifically, we introduce joint unimodal and multimodal token learning for aligning the two modalities with a frozen modality-shared transformer. This allows the model to learn separate representations for each modality, while also attending to the cross-modal relationships between them. In addition, unlike prior work that only aligns coarse features from the output of unimodal encoders, we introduce blockwise contrastive learning to align coarse-to-fine-grain hierarchical features throughout the encoding phase. Furthermore, to suppress the background features in each modality from foreground matched audio-visual features, we introduce a robust discriminative foreground mining scheme. Through extensive experiments on benchmark AVE, VGGSound, and CREMA-D datasets, we achieve considerable performance improvements over SOTA methods.
6/10/2024
EquiAV: Leveraging Equivariance for Audio-Visual Contrastive Learning
Jongsuk Kim, Hyeongkeun Lee, Kyeongha Rho, Junmo Kim, Joon Son Chung
0
0
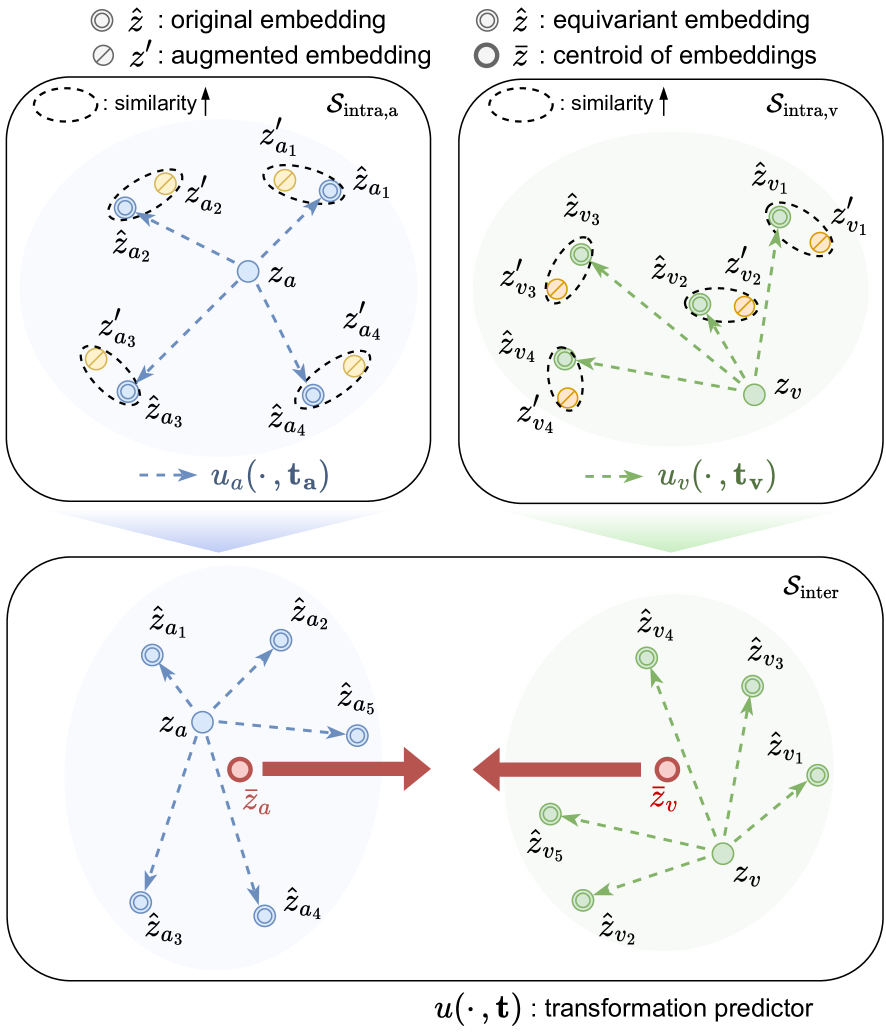
Recent advancements in self-supervised audio-visual representation learning have demonstrated its potential to capture rich and comprehensive representations. However, despite the advantages of data augmentation verified in many learning methods, audio-visual learning has struggled to fully harness these benefits, as augmentations can easily disrupt the correspondence between input pairs. To address this limitation, we introduce EquiAV, a novel framework that leverages equivariance for audio-visual contrastive learning. Our approach begins with extending equivariance to audio-visual learning, facilitated by a shared attention-based transformation predictor. It enables the aggregation of features from diverse augmentations into a representative embedding, providing robust supervision. Notably, this is achieved with minimal computational overhead. Extensive ablation studies and qualitative results verify the effectiveness of our method. EquiAV outperforms previous works across various audio-visual benchmarks. The code is available on https://github.com/JongSuk1/EquiAV.
6/21/2024