Audio-visual training for improved grounding in video-text LLMs

0

Sign in to get full access
Overview
- The paper explores using audio-visual training to improve the grounding of video-text large language models (LLMs).
- It examines how incorporating audio information can enhance the model's understanding and representation of video content.
- The research aims to address the challenge of effectively leveraging multimodal data for improved video-text understanding.
Plain English Explanation
The paper investigates a technique to make video-based language models better at understanding and describing video content. These models, known as video-text LLMs, are trained on both video and text data to learn how to relate the two.
The key idea is to incorporate audio information along with the video data during the training process. The researchers hypothesize that by exposing the model to both the visual and auditory aspects of the video, it can develop a richer and more grounded understanding of the content.
This is important because video-text LLMs often struggle to fully capture the nuances and context present in video data. By leveraging the additional audio cues, the model may be able to better comprehend the actions, events, and overall meaning conveyed in the video, leading to improved performance on tasks like video description and question-answering.
The paper explores the potential benefits of this audio-visual training approach and examines how it can enhance the capabilities of video-text LLMs compared to models trained on video and text alone.
Technical Explanation
The paper proposes an audio-visual training method for video-text LLMs. The key idea is to incorporate audio information during the training process, in addition to the visual video data and text transcripts typically used.
The researchers hypothesize that by exposing the model to both the visual and auditory aspects of the video content, the model can develop a more grounded and comprehensive understanding of the video, leading to improved performance on various video-related tasks.
The training process involves jointly optimizing the model to match video-text pairs as well as audio-video pairs, thereby leveraging the multimodal nature of the data. This is done by adding an audio encoder to the existing video-text model architecture and training the entire system end-to-end.
The researchers evaluate their approach on several video-text understanding tasks, such as video description, question-answering, and action recognition. The results demonstrate the benefits of the audio-visual training approach, with the model outperforming video-text LLMs trained on video and text alone.
The key insight is that audio information can provide complementary cues to the visual data, enhancing the model's ability to comprehend and reason about the video content. This multimodal training approach leads to more robust and grounded video-text representations, which in turn improves the model's performance on a range of video-related tasks.
Critical Analysis
The paper presents a compelling approach to improving video-text LLMs by incorporating audio information during training. The key strength of the research is the intuitive rationale behind the proposed method - that audio cues can provide additional context and grounding to enhance the model's understanding of video content.
However, the paper does not address some potential limitations and areas for further research. For example, it would be interesting to explore how the audio-visual training approach performs on more challenging or domain-specific video-text tasks, beyond the general-purpose tasks considered in the experiments.
Additionally, the paper does not provide a detailed analysis of the types of errors or failure cases that the audio-visual model still experiences, compared to the video-text-only model. Understanding these shortcomings could guide future improvements to the approach.
It would also be valuable to investigate the computational and memory requirements of the audio-visual training approach, as incorporating additional modalities could increase the model complexity and training overhead.
Overall, the paper makes a compelling case for the benefits of audio-visual training for video-text LLMs, but further research is needed to fully understand the strengths, limitations, and broader applicability of this promising technique.
Conclusion
This paper presents an innovative approach to improving video-text large language models (LLMs) by incorporating audio information during the training process. The key insight is that audio cues can provide complementary information to the visual data, enhancing the model's understanding and representation of video content.
The audio-visual training method demonstrated improved performance on various video-text understanding tasks, such as video description and question-answering, compared to models trained on video and text alone. This suggests that leveraging multimodal data can lead to more grounded and contextual video-text representations, which is a promising direction for advancing the capabilities of video-text LLMs.
While the paper presents a compelling approach, further research is needed to fully understand the limitations, computational requirements, and broader applicability of this audio-visual training technique. Nonetheless, this work represents an important step towards enhancing the multimodal understanding of video-text models, with potential implications for a wide range of video-centric applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Audio-visual training for improved grounding in video-text LLMs
Shivprasad Sagare, Hemachandran S, Kinshuk Sarabhai, Prashant Ullegaddi, Rajeshkumar SA
Recent advances in multimodal LLMs, have led to several video-text models being proposed for critical video-related tasks. However, most of the previous works support visual input only, essentially muting the audio signal in the video. Few models that support both audio and visual input, are not explicitly trained on audio data. Hence, the effect of audio towards video understanding is largely unexplored. To this end, we propose a model architecture that handles audio-visual inputs explicitly. We train our model with both audio and visual data from a video instruction-tuning dataset. Comparison with vision-only baselines, and other audio-visual models showcase that training on audio data indeed leads to improved grounding of responses. For better evaluation of audio-visual models, we also release a human-annotated benchmark dataset, with audio-aware question-answer pairs.
Read more7/23/2024
0
Unified Video-Language Pre-training with Synchronized Audio
Shentong Mo, Haofan Wang, Huaxia Li, Xu Tang
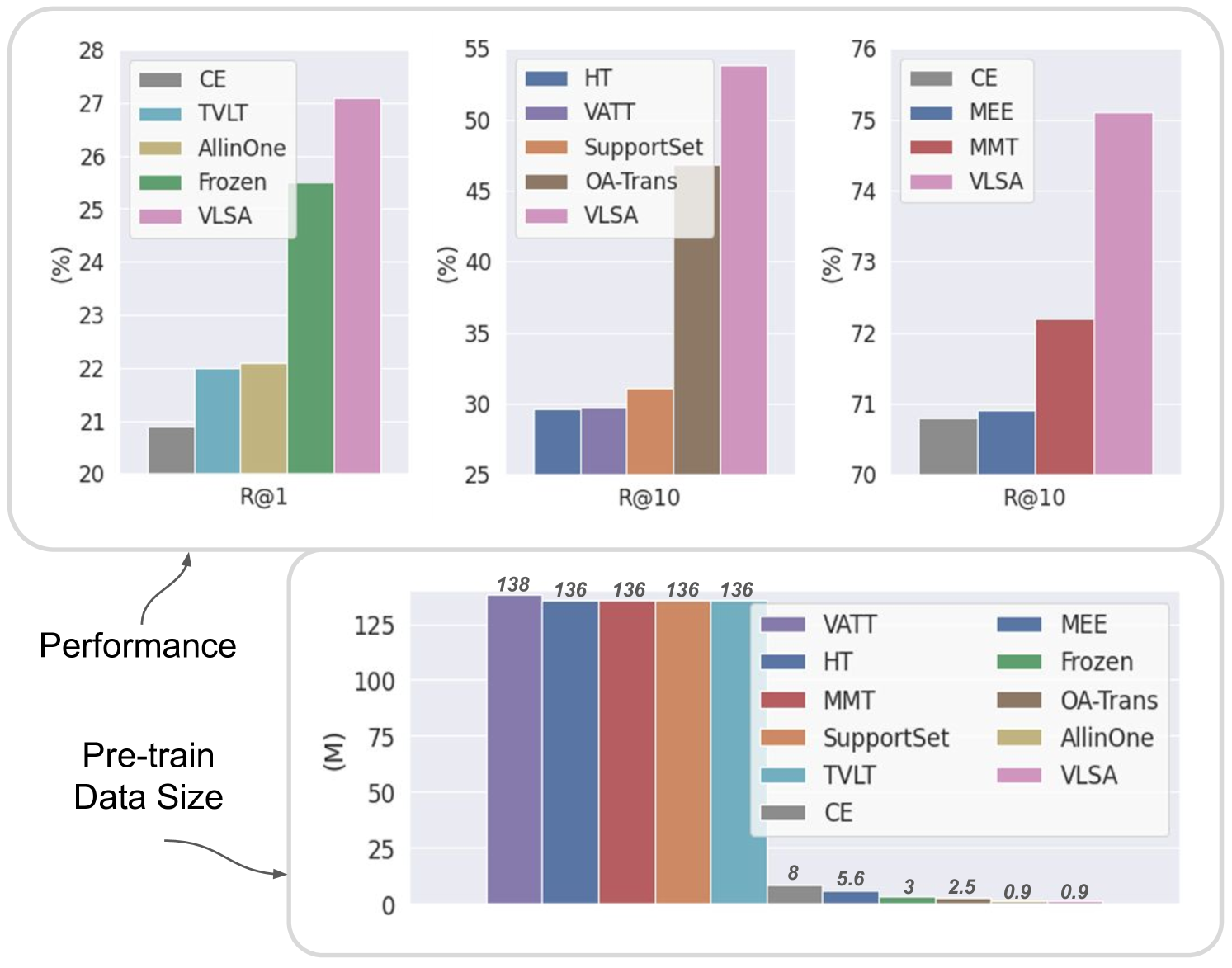
Video-language pre-training is a typical and challenging problem that aims at learning visual and textual representations from large-scale data in a self-supervised way. Existing pre-training approaches either captured the correspondence of image-text pairs or utilized temporal ordering of frames. However, they do not explicitly explore the natural synchronization between audio and the other two modalities. In this work, we propose an enhanced framework for Video-Language pre-training with Synchronized Audio, termed as VLSA, that can learn tri-modal representations in a unified self-supervised transformer. Specifically, our VLSA jointly aggregates embeddings of local patches and global tokens for video, text, and audio. Furthermore, we utilize local-patch masked modeling to learn modality-aware features, and leverage global audio matching to capture audio-guided features for video and text. We conduct extensive experiments on retrieval across text, video, and audio. Our simple model pre-trained on only 0.9M data achieves improving results against state-of-the-art baselines. In addition, qualitative visualizations vividly showcase the superiority of our VLSA in learning discriminative visual-textual representations.
Read more5/14/2024
📈
0
Multimodal Input Aids a Bayesian Model of Phonetic Learning
Sophia Zhi, Roger P. Levy, Stephan C. Meylan
One of the many tasks facing the typically-developing child language learner is learning to discriminate between the distinctive sounds that make up words in their native language. Here we investigate whether multimodal information--specifically adult speech coupled with video frames of speakers' faces--benefits a computational model of phonetic learning. We introduce a method for creating high-quality synthetic videos of speakers' faces for an existing audio corpus. Our learning model, when both trained and tested on audiovisual inputs, achieves up to a 8.1% relative improvement on a phoneme discrimination battery compared to a model trained and tested on audio-only input. It also outperforms the audio model by up to 3.9% when both are tested on audio-only data, suggesting that visual information facilitates the acquisition of acoustic distinctions. Visual information is especially beneficial in noisy audio environments, where an audiovisual model closes 67% of the loss in discrimination performance of the audio model in noise relative to a non-noisy environment. These results demonstrate that visual information benefits an ideal learner and illustrate some of the ways that children might be able to leverage visual cues when learning to discriminate speech sounds.
Read more7/24/2024

0
Meerkat: Audio-Visual Large Language Model for Grounding in Space and Time
Sanjoy Chowdhury, Sayan Nag, Subhrajyoti Dasgupta, Jun Chen, Mohamed Elhoseiny, Ruohan Gao, Dinesh Manocha
Leveraging Large Language Models' remarkable proficiency in text-based tasks, recent works on Multi-modal LLMs (MLLMs) extend them to other modalities like vision and audio. However, the progress in these directions has been mostly focused on tasks that only require a coarse-grained understanding of the audio-visual semantics. We present Meerkat, an audio-visual LLM equipped with a fine-grained understanding of image and audio both spatially and temporally. With a new modality alignment module based on optimal transport and a cross-attention module that enforces audio-visual consistency, Meerkat can tackle challenging tasks such as audio referred image grounding, image guided audio temporal localization, and audio-visual fact-checking. Moreover, we carefully curate a large dataset AVFIT that comprises 3M instruction tuning samples collected from open-source datasets, and introduce MeerkatBench that unifies five challenging audio-visual tasks. We achieve state-of-the-art performance on all these downstream tasks with a relative improvement of up to 37.12%.
Read more7/4/2024