Meerkat: Audio-Visual Large Language Model for Grounding in Space and Time

0

Sign in to get full access
Overview
- This paper introduces Meerkat, an audio-visual large language model (AV-LLM) that can ground language in both space and time.
- Meerkat is trained on a new dataset called AVFIT, which contains aligned audio, visual, and textual data, allowing the model to learn multimodal representations.
- The paper demonstrates Meerkat's capabilities in various audio-visual tasks, such as audio-visual question answering, video-text retrieval, and audio-visual segmentation.
Plain English Explanation
Meerkat is a new type of artificial intelligence (AI) model that can understand and process both audio and visual information, in addition to language. This allows it to better comprehend the world around it and how different elements, like sounds and images, relate to each other and to what is being said or written.
To train Meerkat, the researchers created a new dataset called AVFIT, which contains a large amount of aligned audio, visual, and textual data. This means the model can see how words, sounds, and images all fit together, helping it build a more complete understanding of the world.
With Meerkat, the researchers demonstrate several impressive capabilities, such as linking audio and visual information to answer questions, finding relevant videos based on text descriptions, and identifying different elements within audio-visual scenes. This shows that Meerkat can understand the connections between language, sound, and visuals in a way that may be more human-like than traditional AI systems.
Overall, Meerkat represents an important step forward in developing large language models that can truly understand and interact with the multimodal world around us.
Technical Explanation
The key innovation of this work is the development of Meerkat, an audio-visual large language model (AV-LLM) that can ground language in both space and time. To train Meerkat, the researchers created a new dataset called AVFIT, which contains aligned audio, visual, and textual data from a variety of sources.
The Meerkat model architecture builds on previous work in multimodal transformers, with separate encoders for audio, visual, and text inputs, along with a shared cross-modal transformer to learn joint representations. The researchers experiment with different strategies for fusing the modalities, including late fusion, cross-attention, and multi-task learning.
Through extensive experiments, the paper demonstrates Meerkat's strong performance on a range of audio-visual tasks, including audio-visual question answering, video-text retrieval, and audio-visual segmentation. The model is able to effectively leverage the complementary information from the different modalities to achieve better results than unimodal or simpler multimodal baselines.
Critical Analysis
The authors acknowledge several limitations of their work, including the need for larger and more diverse datasets to further improve Meerkat's performance and generalization. They also note that the current model architecture may struggle with long-range temporal dependencies, which could be addressed through additional architectural innovations.
One potential concern is the computational complexity and resource requirements of training and deploying large multimodal models like Meerkat. The authors do not provide detailed information on the training time and inference latency of their model, which would be important considerations for real-world applications.
Additionally, the paper does not explore potential biases or ethical considerations that may arise from training such a powerful multimodal system on web-scraped data. As large language models become more capable, it will be crucial for researchers to carefully consider the societal implications of their work.
Conclusion
The Meerkat paper represents an exciting advance in the field of multimodal learning, demonstrating the potential for audio-visual large language models to better understand and interact with the world around us. By grounding language in both space and time, Meerkat opens up new possibilities for applications ranging from assistive technology to creative expression.
As the research in this area continues to evolve, it will be important to address the challenges and limitations highlighted in this work, such as dataset diversity, architectural scalability, and ethical considerations. Nonetheless, the Meerkat project serves as a promising step towards realizing the full potential of large language models to perceive and reason about the multimodal world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Meerkat: Audio-Visual Large Language Model for Grounding in Space and Time
Sanjoy Chowdhury, Sayan Nag, Subhrajyoti Dasgupta, Jun Chen, Mohamed Elhoseiny, Ruohan Gao, Dinesh Manocha
Leveraging Large Language Models' remarkable proficiency in text-based tasks, recent works on Multi-modal LLMs (MLLMs) extend them to other modalities like vision and audio. However, the progress in these directions has been mostly focused on tasks that only require a coarse-grained understanding of the audio-visual semantics. We present Meerkat, an audio-visual LLM equipped with a fine-grained understanding of image and audio both spatially and temporally. With a new modality alignment module based on optimal transport and a cross-attention module that enforces audio-visual consistency, Meerkat can tackle challenging tasks such as audio referred image grounding, image guided audio temporal localization, and audio-visual fact-checking. Moreover, we carefully curate a large dataset AVFIT that comprises 3M instruction tuning samples collected from open-source datasets, and introduce MeerkatBench that unifies five challenging audio-visual tasks. We achieve state-of-the-art performance on all these downstream tasks with a relative improvement of up to 37.12%.
Read more7/4/2024

0
Audio-visual training for improved grounding in video-text LLMs
Shivprasad Sagare, Hemachandran S, Kinshuk Sarabhai, Prashant Ullegaddi, Rajeshkumar SA
Recent advances in multimodal LLMs, have led to several video-text models being proposed for critical video-related tasks. However, most of the previous works support visual input only, essentially muting the audio signal in the video. Few models that support both audio and visual input, are not explicitly trained on audio data. Hence, the effect of audio towards video understanding is largely unexplored. To this end, we propose a model architecture that handles audio-visual inputs explicitly. We train our model with both audio and visual data from a video instruction-tuning dataset. Comparison with vision-only baselines, and other audio-visual models showcase that training on audio data indeed leads to improved grounding of responses. For better evaluation of audio-visual models, we also release a human-annotated benchmark dataset, with audio-aware question-answer pairs.
Read more7/23/2024

0
LLM4VG: Large Language Models Evaluation for Video Grounding
Wei Feng, Xin Wang, Hong Chen, Zeyang Zhang, Houlun Chen, Zihan Song, Yuwei Zhou, Yuekui Yang, Haiyang Wu, Wenwu Zhu
Recently, researchers have attempted to investigate the capability of LLMs in handling videos and proposed several video LLM models. However, the ability of LLMs to handle video grounding (VG), which is an important time-related video task requiring the model to precisely locate the start and end timestamps of temporal moments in videos that match the given textual queries, still remains unclear and unexplored in literature. To fill the gap, in this paper, we propose the LLM4VG benchmark, which systematically evaluates the performance of different LLMs on video grounding tasks. Based on our proposed LLM4VG, we design extensive experiments to examine two groups of video LLM models on video grounding: (i) the video LLMs trained on the text-video pairs (denoted as VidLLM), and (ii) the LLMs combined with pretrained visual description models such as the video/image captioning model. We propose prompt methods to integrate the instruction of VG and description from different kinds of generators, including caption-based generators for direct visual description and VQA-based generators for information enhancement. We also provide comprehensive comparisons of various VidLLMs and explore the influence of different choices of visual models, LLMs, prompt designs, etc, as well. Our experimental evaluations lead to two conclusions: (i) the existing VidLLMs are still far away from achieving satisfactory video grounding performance, and more time-related video tasks should be included to further fine-tune these models, and (ii) the combination of LLMs and visual models shows preliminary abilities for video grounding with considerable potential for improvement by resorting to more reliable models and further guidance of prompt instructions.
Read more9/14/2024
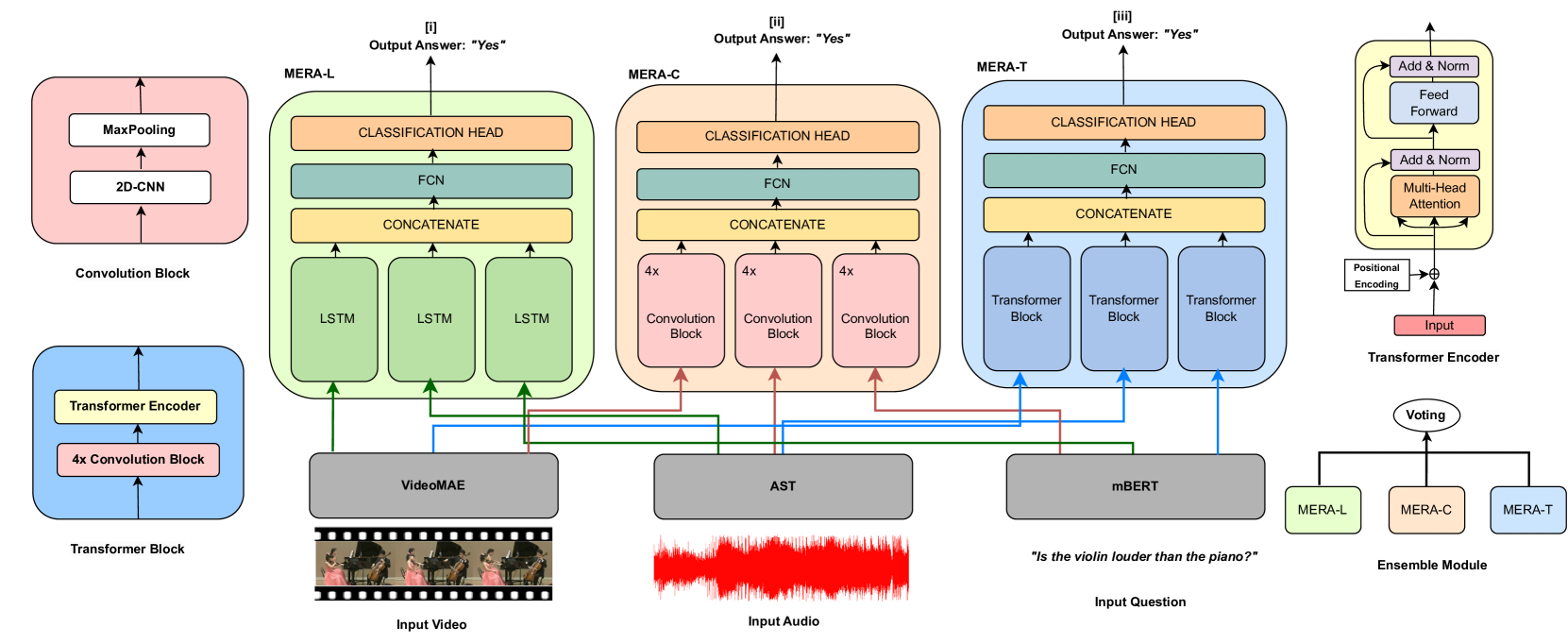
0
Towards Multilingual Audio-Visual Question Answering
Orchid Chetia Phukan, Priyabrata Mallick, Swarup Ranjan Behera, Aalekhya Satya Narayani, Arun Balaji Buduru, Rajesh Sharma
In this paper, we work towards extending Audio-Visual Question Answering (AVQA) to multilingual settings. Existing AVQA research has predominantly revolved around English and replicating it for addressing AVQA in other languages requires a substantial allocation of resources. As a scalable solution, we leverage machine translation and present two multilingual AVQA datasets for eight languages created from existing benchmark AVQA datasets. This prevents extra human annotation efforts of collecting questions and answers manually. To this end, we propose, MERA framework, by leveraging state-of-the-art (SOTA) video, audio, and textual foundation models for AVQA in multiple languages. We introduce a suite of models namely MERA-L, MERA-C, MERA-T with varied model architectures to benchmark the proposed datasets. We believe our work will open new research directions and act as a reference benchmark for future works in multilingual AVQA.
Read more6/14/2024