Auditing Privacy Mechanisms via Label Inference Attacks

0

Sign in to get full access
Overview
- This research paper presents a new privacy attack called a "label inference attack" that can be used to audit the privacy of machine learning systems.
- The attack exploits weaknesses in the way machine learning models handle sensitive labels or attributes, allowing the attacker to infer these labels even when the model is supposed to be protecting them.
- The authors demonstrate the effectiveness of this attack on several real-world machine learning models and datasets, highlighting the need for more rigorous privacy auditing of these systems.
Plain English Explanation
The paper is about a new way to test the privacy protections of machine learning models. Machine learning models are often used to make predictions or decisions based on data, and they're supposed to protect sensitive information about the people in the data. However, the researchers found a technique that can sometimes allow an attacker to figure out this sensitive information anyway, even when the model is trying to keep it private.
The key idea is that the attacker can use the model's own predictions to infer the sensitive labels or attributes that the model is trying to protect. For example, if the model is trying to predict someone's age while keeping their gender private, the attacker might be able to use the age prediction to figure out the gender. [This relates to the research in https://aimodels.fyi/papers/arxiv/linear-reconstruction-approach-attribute-inference-attacks-against.]
The researchers show that this "label inference attack" works quite well on real-world machine learning models and datasets. This suggests that the current methods for auditing the privacy of these models may not be enough, and more thorough testing is needed. [This ties into the findings from https://aimodels.fyi/papers/arxiv/evaluations-machine-learning-privacy-defenses-are-misleading.]
Technical Explanation
The paper introduces a new type of privacy attack called a "label inference attack" that can be used to audit the privacy guarantees of machine learning models. The key idea is that the attacker can leverage the model's own predictions to infer sensitive labels or attributes that the model is supposed to be protecting.
The attack works by training a separate "label inference model" that takes the model's predictions as input and tries to predict the sensitive labels. If the label inference model is able to accurately predict the sensitive labels, it reveals a weakness in the privacy protections of the original model.
The authors demonstrate the effectiveness of this attack on several real-world machine learning datasets and models, including ones that use techniques like differential privacy [see https://aimodels.fyi/papers/arxiv/attaxonomy-unpacking-differential-privacy-guarantees-against-practical] and other privacy-preserving mechanisms. They show that the label inference attack can often achieve high accuracy in recovering the sensitive labels, even when the original model is supposed to be protecting that information.
Critical Analysis
The label inference attack proposed in this paper provides a powerful new tool for auditing the privacy of machine learning systems. By directly targeting the model's ability to protect sensitive information, rather than just measuring broad privacy metrics, the attack can reveal meaningful weaknesses that may be missed by other evaluation methods.
However, the paper also acknowledges some limitations of the approach. For example, the effectiveness of the attack may depend on the specific datasets and models being tested, and the attack may be less successful against models that use more advanced privacy-preserving techniques.
Additionally, while the paper demonstrates the attack on several real-world examples, it does not provide a comprehensive survey of the privacy vulnerabilities across a wide range of machine learning applications. More research would be needed to fully understand the scope and severity of the issues uncovered by this type of attack.
Overall, the label inference attack represents an important advance in privacy auditing for machine learning, but should be seen as one tool among many that can be used to rigorously evaluate the privacy protections of these systems. Combining this attack with other techniques, such as those explored in https://aimodels.fyi/papers/arxiv/one-shot-empirical-privacy-estimation-federated-learning and https://aimodels.fyi/papers/arxiv/better-membership-inference-privacy-measurement-through-discrepancy, may lead to a more comprehensive understanding of machine learning privacy.
Conclusion
This research paper presents a new "label inference attack" that can be used to audit the privacy protections of machine learning models. By exploiting weaknesses in how these models handle sensitive information, the attack allows an attacker to recover private labels or attributes that the model is supposed to be keeping confidential.
The authors demonstrate the effectiveness of this attack on several real-world examples, highlighting the need for more rigorous and comprehensive privacy testing of machine learning systems. While the attack has some limitations, it represents an important new tool in the ongoing effort to ensure that these powerful technologies respect user privacy and do not inadvertently leak sensitive information.
As machine learning becomes increasingly ubiquitous, developing robust methods for evaluating and securing the privacy of these systems will only grow in importance. This paper's contribution to that effort is a significant step forward.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Auditing Privacy Mechanisms via Label Inference Attacks
R'obert Istv'an Busa-Fekete, Travis Dick, Claudio Gentile, Andr'es Mu~noz Medina, Adam Smith, Marika Swanberg
We propose reconstruction advantage measures to audit label privatization mechanisms. A reconstruction advantage measure quantifies the increase in an attacker's ability to infer the true label of an unlabeled example when provided with a private version of the labels in a dataset (e.g., aggregate of labels from different users or noisy labels output by randomized response), compared to an attacker that only observes the feature vectors, but may have prior knowledge of the correlation between features and labels. We consider two such auditing measures: one additive, and one multiplicative. These incorporate previous approaches taken in the literature on empirical auditing and differential privacy. The measures allow us to place a variety of proposed privatization schemes -- some differentially private, some not -- on the same footing. We analyze these measures theoretically under a distributional model which encapsulates reasonable adversarial settings. We also quantify their behavior empirically on real and simulated prediction tasks. Across a range of experimental settings, we find that differentially private schemes dominate or match the privacy-utility tradeoff of more heuristic approaches.
Read more6/6/2024
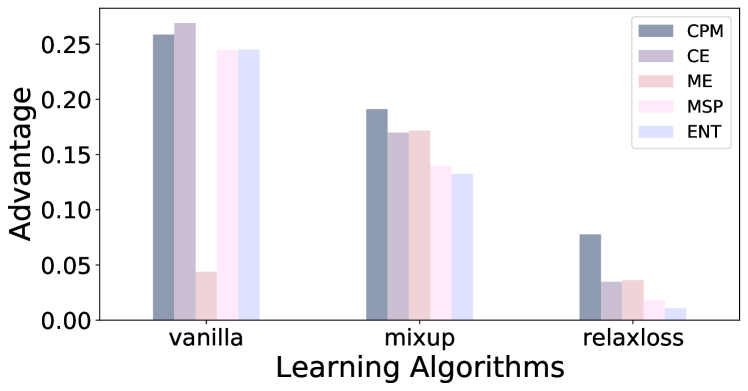
0
Better Membership Inference Privacy Measurement through Discrepancy
Ruihan Wu, Pengrun Huang, Kamalika Chaudhuri
Membership Inference Attacks have emerged as a dominant method for empirically measuring privacy leakage from machine learning models. Here, privacy is measured by the {em{advantage}} or gap between a score or a function computed on the training and the test data. A major barrier to the practical deployment of these attacks is that they do not scale to large well-generalized models -- either the advantage is relatively low, or the attack involves training multiple models which is highly compute-intensive. In this work, inspired by discrepancy theory, we propose a new empirical privacy metric that is an upper bound on the advantage of a family of membership inference attacks. We show that this metric does not involve training multiple models, can be applied to large Imagenet classification models in-the-wild, and has higher advantage than existing metrics on models trained with more recent and sophisticated training recipes. Motivated by our empirical results, we also propose new membership inference attacks tailored to these training losses.
Read more5/27/2024

0
Data Reconstruction Attacks and Defenses: A Systematic Evaluation
Sheng Liu, Zihan Wang, Yuxiao Chen, Qi Lei
Reconstruction attacks and defenses are essential in understanding the data leakage problem in machine learning. However, prior work has centered around empirical observations of gradient inversion attacks, lacks theoretical justifications, and cannot disentangle the usefulness of defending methods from the computational limitation of attacking methods. In this work, we propose to view the problem as an inverse problem, enabling us to theoretically, quantitatively, and systematically evaluate the data reconstruction problem. On various defense methods, we derived the algorithmic upper bound and the matching (in feature dimension and model width) information-theoretical lower bound on the reconstruction error for two-layer neural networks. To complement the theoretical results and investigate the utility-privacy trade-off, we defined a natural evaluation metric of the defense methods with similar utility loss among the strongest attacks. We further propose a strong reconstruction attack that helps update some previous understanding of the strength of defense methods under our proposed evaluation metric.
Read more6/28/2024
🤯
0
A Linear Reconstruction Approach for Attribute Inference Attacks against Synthetic Data
Meenatchi Sundaram Muthu Selva Annamalai, Andrea Gadotti, Luc Rocher
Recent advances in synthetic data generation (SDG) have been hailed as a solution to the difficult problem of sharing sensitive data while protecting privacy. SDG aims to learn statistical properties of real data in order to generate artificial data that are structurally and statistically similar to sensitive data. However, prior research suggests that inference attacks on synthetic data can undermine privacy, but only for specific outlier records. In this work, we introduce a new attribute inference attack against synthetic data. The attack is based on linear reconstruction methods for aggregate statistics, which target all records in the dataset, not only outliers. We evaluate our attack on state-of-the-art SDG algorithms, including Probabilistic Graphical Models, Generative Adversarial Networks, and recent differentially private SDG mechanisms. By defining a formal privacy game, we show that our attack can be highly accurate even on arbitrary records, and that this is the result of individual information leakage (as opposed to population-level inference). We then systematically evaluate the tradeoff between protecting privacy and preserving statistical utility. Our findings suggest that current SDG methods cannot consistently provide sufficient privacy protection against inference attacks while retaining reasonable utility. The best method evaluated, a differentially private SDG mechanism, can provide both protection against inference attacks and reasonable utility, but only in very specific settings. Lastly, we show that releasing a larger number of synthetic records can improve utility but at the cost of making attacks far more effective.
Read more5/10/2024